基于RAG搭建知识库在线问答
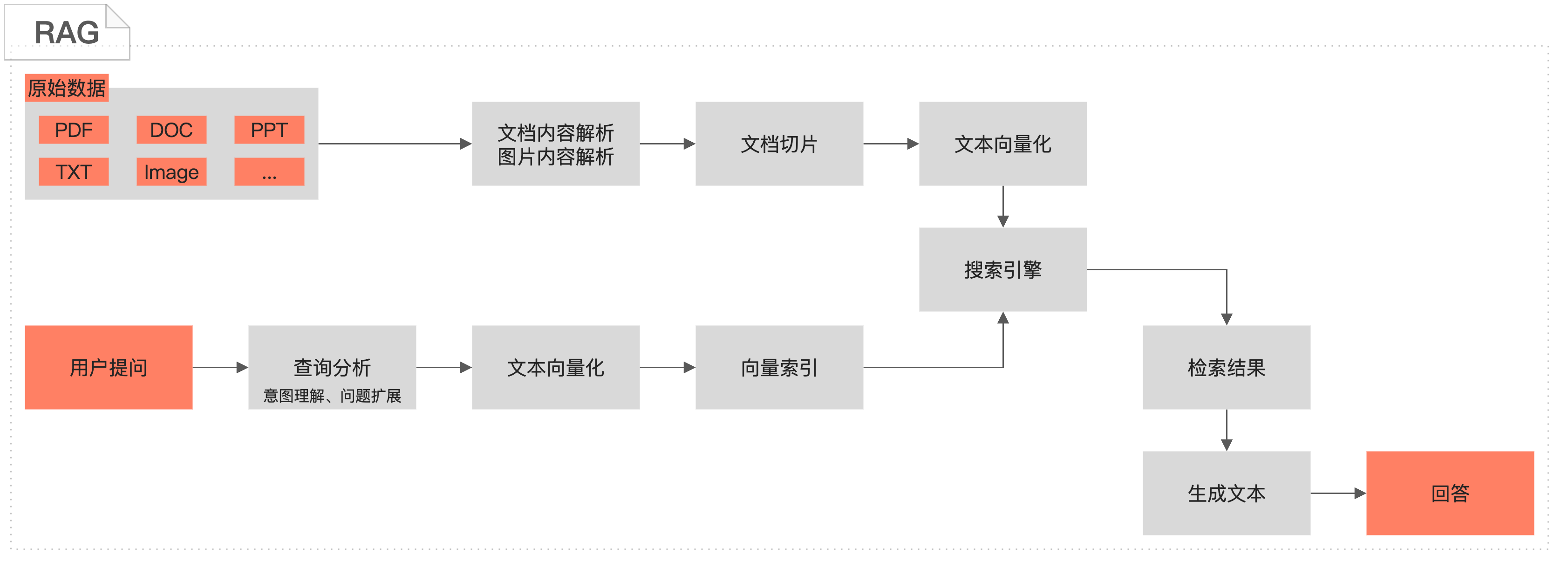
针对知识库在线问答场景,AI搜索开放平台提供完整的RAG开发链路搭建方法,整体链路包含数据预处理、检索服务以及问答总结生成三大模块。AI搜索开放平台将各模块可用的算法服务组件化,可灵活选择各模块使用的服务,如文档解析、排序、问答总结服务等,快速生成开发代码。AI搜索开放平台以API形式透出服务,开发者只需将代码下载到本地,根据本文操作步骤替换API_KEY、API调用地址、本地知识库等信息,即可快速搭建基于RAG开发链路的知识库问答应用。
技术原理
检索增强生成RAG(Retrieval-Augmented Generation)结合了检索技术和生成技术的人工智能方法,旨在提升模型生成内容的相关性、准确性和多样性。处理生成任务时,RAG首先在大量外部数据或知识库中检索与输入最相关的片段,然后将检索到的信息与原始输入一起输入到大语言模型(LLM)中,作为提示或者上下文引导模型生成更精确和丰富的回答。这种方法允许模型在生成响应时不仅依赖于其内部的参数和训练数据,还可以使用外部最新或特定领域的信息提升回答准确性。
应用场景
知识库在线问答常用于企业内部知识库检索与总结、垂直领域的在线问答等业务场景,基于客户的专业知识库文档,通过RAG(检索增强生成)技术和LLM(大语言模型) ,理解和响应复杂的自然语言查询,帮助企业客户通过自然语言快速从PDF、WORD、表格、图片文档中检索到所需信息。
在对话式问答界面中,用户提交自然语言问题后,系统以结构化步骤形式返回回答,并在下方提供推荐问题供进一步探索。
前提条件
-
开通AI搜索开放平台服务,详情请参见开通服务。
-
获取服务调用地址和身份鉴权信息,详情请参见获取服务接入地址、获取API-KEY。
AI搜索开放平台支持通过公网和VPC地址调用服务,且可通过VPC实现跨地域调用服务。目前支持上海、杭州、深圳、北京、张家口、青岛地域的用户,通过VPC地址调用AI搜索开放平台的服务。
在 API Keys 页面,顶部提示"API Key 用于服务调用权限,请妥善保管;一旦泄露请立即禁用,至多有 10 个 API Key 同时启用"。访问域名 区域分别展示公网 API 域名和私网 API 域名,两者均支持 HTTPS 访问。
-
创建阿里云Elasticsearch(ES)实例,要求ES 8.5及以上版本,详情请参见创建阿里云Elasticsearch实例。通过公网或私网访问阿里云ES实例时,需要将待访问设备的IP地址加入实例的访问白名单中,详情请参见配置实例公网或私网访问白名单。
-
Python版本3.7及以上,在开发环境中引入Python包依赖aiohttp 3.8.6、elasticsearch 8.14。
RAG开发链路搭建
为方便用户使用,AI搜索开放平台提供四种类型的开发框架:
-
Java SDK。
-
Python SDK。
-
如果业务已经使用LangChain开发框架,在开发框架中选择LangChain。
-
如果业务已经使用LlamaIndex开发框架,在开发框架中选择LlamaIndex。
步骤一:完成服务选型和代码下载
根据知识库和业务需要,选择RAG链路中需要使用的算法服务以及开发框架,本文以Python SDK开发框架为例介绍如何搭建RAG链路。
-
登录AI搜索开放平台控制台。
-
选择上海地域,切换到AI搜索开放平台,切换到目标空间。
说明-
目前仅支持在上海、德国(法兰克福)开通AI搜索开放平台功能。
-
支持杭州、深圳、北京、张家口、青岛地域的用户,通过VPC地址跨地域调用AI搜索开放平台的服务。
-
-
在左侧导航栏选择场景中心,选择RAG场景-知识库在线问答右侧的进入。
-
根据服务信息结合业务特点,从下拉列表中选择所需服务,服务详情页面可查看服务详细信息。
说明-
通过API调用RAG链路中的算法服务时,需要提供服务ID(service_id),如文档内容解析服务的ID为ops-document-analyze-001。
-
从服务列表中切换服务后,生成代码中的service_id会同步更新。当代码下载到本地环境后,您仍可以更改service_id,调用对应服务。
环节
服务说明
文档内容解析
文档内容解析服务(ops-document-analyze-001):提供通用文档解析服务,支持从非结构化文档(文本、表格、图片等)中提取标题、分段等逻辑层级结构,以结构化格式输出。
图片内容解析
-
图片内容理解服务(ops-image-analyze-vlm-001):可基于多模态大模型对图片内容进行解析理解以及文字识别,解析后的文本可用于图片检索问答场景。
-
图片文本识别服务(ops-image-analyze-ocr-001):使用OCR能力进行图片文字识别,解析后的文本可用于图片检索问答场景。
文档切片
文档切片服务(ops-document-split-001):提供通用文本切片服务,支持基于文档段落、文本语义、指定规则,对HTML、Markdown、txt格式的结构化数据进行拆分,同时支持以富文本形式提取文档中的代码、图片以及表格。
文本向量化
-
OpenSearch文本向量化服务-001(ops-text-embedding-001):提供多语言(40+)文本向量化服务,输入文本最大长度300,输出向量维度1536维。
-
OpenSearch通用文本向量化服务-002(ops-text-embedding-002):提供多语言(100+)文本向量化服务,输入文本最大长度8192,输出向量维度1024维。
-
OpenSearch文本向量化服务-中文-001(ops-text-embedding-zh-001):提供中文文本向量化服务,输入文本最大长度1024,输出向量维度768维。
-
OpenSearch文本向量化服务-英文-001(ops-text-embedding-en-001):提供英文文本向量化服务,输入文本最大长度512,输出向量维度768维。
文本稀疏向量化
提供将文本数据转化为稀疏向量形式表达的服务,稀疏向量存储空间更小,常用于表达关键词和词频信息,可与稠密向量搭配进行混合检索,提升检索效果。
OpenSearch文本稀疏向量化服务(ops-text-sparse-embedding-001):提供多语言(100+)文本向量化服务,输入文本最大长度8192。
查询分析
查询分析服务001(ops-query-analyze-001)提供通用的Query分析服务,可基于大语言模型对用户输入的Query进行意图理解,以及相似问题扩展。
搜索引擎
-
阿里云Elasticsearch:基于开源Elasticsearch构建的全托管云服务,100%兼容开源功能的同时,支持开箱即用、按需付费。
说明搜索引擎服务选择阿里云Elasticsearch时,由于兼容性问题,文本稀疏向量化服务不可用,建议使用文本向量化相关服务。
-
OpenSearch-向量检索版是阿里巴巴自主研发的大规模分布式向量检索引擎,支持多种向量检索算法,高精度下性能表现优异,能完成大规模高性价比的索引构建和检索,同时,索引支持水平拓展与合并,支持索引流式构建、即增即查、数据实时动态更新。
说明如您需要使用OpenSearch-向量检索版引擎方案,可以在RAG链路中替换引擎配置及代码。
排序服务
BGE重排模型(ops-bge-reranker-larger):通用文档打分服务,支持根据query与文档内容的相关性,按分数由高到低对文档排序,并输出打分结果。
大模型
-
-
完成服务选型后,单击配置完成,进入代码查询查看和下载代码。
按照应用调用RAG链路时的运行流程,将代码分为离线文档处理和在线用户问答处理两部分:
流程
作用
说明
离线文档处理
负责文档处理,包含文档解析、图片提取、切片、向量化以及将文档处理结果写入ES索引。
使用主函数document_pipeline_execute完成以下流程,可通过文档URL或Base64编码输入待处理文档。
-
文档解析,服务调用请参见文档解析API。
-
调用异步文档解析接口,从文档URL地址中提取文档内容,或者从Base64编码文件中进行解码。
-
通过create_async_extraction_task函数构造解析任务,通过poll_task_result函数轮询任务完成状态。
-
-
图片提取,服务调用请参见图片内容提取API。
-
调用异步图片解析接口,从图片URL地址中提取图片内容,或者从Base64编码文件中进行解码。
-
通过create_image_analyze_task函数创建图片解析任务,通过get_image_analyze_task_status函数获取图片解析任务状态。
-
-
文档切片,服务调用请参见文档切片API。
-
调用文档切片接口,将解析后的文档按指定策略切片。
-
通过document_split函数进行文档切片,包含文档切片和富文本内容解析两部分。
-
-
文本向量化,服务调用请参见文本向量化API。
-
调用文本稠密向量表示接口,将切片后的文本向量化。
-
通过text_embedding函数计算每个切片的embedding向量。
-
-
写入ES,服务调用请参见使用Elasticsearch的向量近邻检索(kNN)功能。
-
创建ES索引配置,包含指定向量字段embedding和文档内容字段content。
重要创建ES索引时,系统会删除已有同名索引。为避免误删同名索引,请更改代码中的索引名称。
-
通过helpers.async_bulk函数将向量化结果批量写入ES索引。
-
在线问答处理
负责处理用户在线查询,包含生成查询向量、查询分析、检索相关文档切片、排序检索结果以及根据检索结果生成回答。
使用主函数query_pipeline_execute完成以下流程,对用户查询进行处理并输出回答。
-
query向量化,服务调用请参见文本向量化API。
-
调用文本稠密向量表示接口,将用户的查询转换为向量。
-
通过text_embedding函数生成查询向量。
-
-
调用查询分析服务,请参见查询分析API。
调用查询分析接口,通过分析历史消息识别用户提问意图及生成相似问题。
-
搜索embedding切片,服务调用请参见使用Elasticsearch的向量近邻检索(kNN)功能。
-
使用ES检索索引中与查询向量相近的文档切片。
-
通过AsyncElasticsearch的search接口,结合KNN查询进行相似度检索。
-
-
调用排序服务,请参见排序API。
-
调用排序服务接口,对检索到的相关切片打分排序。
-
通过documents_ranking函数,根据用户查询对文档内容打分排序。
-
-
调用大模型生成答案,服务调用请参见答案生成API。
调用大模型服务,使用检索结果和用户查询通过llm_call函数生成最终答案。
分别选择代码查询下的文档处理流程和在线问答流程,单击复制代码或者下载文件,将代码下载到本地。
-
步骤二:本地环境适配和测试RAG开发链路
将代码分别下载到本地的两个文件后,例如online.py和offline.py,需要配置代码中的关键参数。
|
类别 |
参数 |
说明 |
|
AI搜索开放平台 |
api_key |
API调用密钥,获取方式请参见管理API Key。 |
|
aisearch_endpoint |
API调用地址,获取方式请参见获取服务接入地址。 说明
注意需要去掉“http://”。 支持通过公网和VPC两种方式调用API。 |
|
|
workspace_name |
AI搜索开放平台 |
|
|
service_id |
服务ID,为操作方便,可以分别在离线文档处理(offline.py)和在线问答处理代码(online.py)中,通过service_id_config配置各项服务以及ID。 |
|
|
ES搜索引擎 |
es_host |
Elasticsearch(ES)实例访问地址,通过公网或私网访问阿里云ES实例时,需要先将待访问设备的IP地址加入实例的访问白名单中,详情参见配置实例公网或私网访问白名单。 |
|
es_auth |
访问Elasticsearch实例时的账号和密码,账号为elastic,密码为您创建实例时设置的密码。如果忘记密码可重置,具体操作请参见重置实例访问密码。 |
|
|
其他参数 |
如使用示例数据则无需修改 |
|
完成参数配置后即可在Python 3.7及以上版本环境中,先后运行offline.py离线文档处理文件和online.py在线问答处理文件测试运行结果是否正确。
如知识库文档为AI搜索开放平台介绍,对文档提问:AI搜索开放平台可以做什么?
运行结果如下:
-
离线文档处理结果
image analyze :https://img.alicdn.com/imgextra/i2/O1CN01bYc1m81RrcSAyOjMu_!!6000000002165-54-tps-60-60.apng https://img.alicdn.com/imgextra/i2/O1CN01bYc1m81RrcSAyOjMu_!!6000000002165-54-tps-60-60.apng is not analyzable. image analyze :https://help-static-aliyun-doc.aliyuncs.com/assets/img/zh-CN/3873436171/p802381.png image analyze :https://help-static-aliyun-doc.aliyuncs.com/assets/img/zh-CN/0650850271/p819277.png image analyze :https://help-static-aliyun-doc.aliyuncs.com/assets/img/zh-CN/0650850271/p819277.png image analyze ://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif https://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif is not analyzable. image analyze ://img.alicdn.com/tfs/TB1..50QpXXXX7XpXXXXXXXXXX-40-40.png image analyze :https://img.alicdn.com/tfs/TB1A0dINW6qK1RjSZFmXXX0PFXa-258-258.jpg image analyze ://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif https://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif is not analyzable. image analyze ://img.alicdn.com/tfs/TB1..50QpXXXX7XpXXXXXXXXXX-40-40.png image analyze ://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif https://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif is not analyzable. image analyze ://img.alicdn.com/tfs/TB1..50QpXXXX7XpXXXXXXXXXX-40-40.png text-embedding done OS write response: {"status":"OK","code":200} -
在线问答处理结果
/opt/miniconda3/envs/QA-pytest-base-lib1/bin/python /Users/liu/codeRepos/QA-pytest-base-lib/rag/case/SDK/python_sdk_es_zx.py query analysis rewrite result:opensearch搜索开发平台可以做什么? 大模型最终回答: OpenSearch搜索开发平台可以提供智能搜索服务,支持包括淘宝、天猫在内的阿里集团核心业务的搜索服务,并为外部各行业客户提供智能搜索解决方案。它具备行业查询语义理解和机器学习排序算法的能力,可以帮助开发者搭建效果较好的智能搜索服务。此外,OpenSearch还 该平台适用于多种场景,包括但不限于: - 电商、零售智能搜索 - 内容资讯搜索 - 游戏行业搜索 - 医疗行业搜索 - 金融行业搜索 OpenSearch搜索开发工作台围绕智能搜索及RAG (Retrieval-Augmented Generation) 场景,提供组件化服务和灵活的调用机制。它内置了文档解析、文档切片、文本向量、召回、排序及大模型等服务,能够实现一站式灵活的AI搜索业务开发。通过这些服务,用户可以玩转RAG及搜索链路, Process finished with exit code 0 -
查看源码文件
常见问题
代码运行期间,由于资源未及时释放可能出现Unclosed connector相关提示,无需处理。