工作流应用将复杂的任务拆分成一系列有序执行的步骤,以降低系统复杂度。在阿里云百炼,通过工作流组合使用大模型、API和函数计算等节点,可有效降低编码成本。本文介绍如何创建工作流。

应用介绍
为什么使用工作流应用
工作流是一种将复杂任务拆分为一系列有序步骤的方法,旨在简化系统复杂度,提高工作效率。在现代软件开发和业务流程管理中,工作流应用变得尤为重要。通过在阿里云百炼平台上创建工作流应用,可以清晰地定义任务的执行顺序、责任分配以及各步骤之间的依赖关系,从而实现自动化和优化。
工作流应用有许多使用场景,如:
旅行规划:用户可通过工作流插件选择目的地等参数,自动生成旅行计划,包括航班、住宿、景点推荐等。
报告分析:针对复杂数据集,通过组合数据处理、分析和可视化插件,生成结构化和格式化的分析报告,满足不同业务需求。
客服支持:通过自动化工作流处理客户咨询,包括问题分类等,提高客服响应速度和准确性。
内容创作:实现文章、市场营销文案等内容的生成,用户只需输入主题和要求,系统自动生成符合要求的文稿。
教育培训:通过工作流设计个性化学习方案,包括学习进度跟踪、测评等,实现学生的自主学习。
医疗问诊:根据患者输入的症状,通过组合多种分析工具生成初步诊断或推荐相关检查,辅助医生进行进一步判断。
支持模型
如需了解模型的详细介绍,请参阅模型列表与价格。
如需了解各模型的 API 调用速率限制,请参阅限流。
模型的支持情况以智能体应用内显示为准。
具体案例
本章节以创建一个判断短信是否涉及电信诈骗的工作流应用为例进行说明。
| |
| |
|
|
|
|
|
|
|
|
| |




节点说明
节点是工作流应用的核心功能单元,各自承担特定任务,如执行操作、触发条件、处理数据或决定流程走向。它们就像积木般灵活拼接,共同构建高效、智能的自动化流程。
开始/结束
何时使用
在设计工作流时,您需要确定输入/输出参数的结构和内容,并填入开始/结束节点。
如何使用
开始节点
组件
说明
变量名
输入参数的名称,后续节点可通过变量名调用此变量。
类型
输入参数的数据类型(当前仅支持 String / Boolean / Number,如需传入 Array 或 Object,需在进入工作流之前自行解析)。
描述
输入参数的描述,用于解释参数的作用。
说明除了自定义的变量外,应用还内置了一些实用变量:
query
用户查询变量,用于接收 API 调用的 prompt 变量,或测试窗用户发送的文本。
historyList(仅在对话型工作流时启用)
对话历史列表,用于应用自动维护对话历史记录,提供多轮对话体验。
imageList(仅在对话型工作流时启用)
图片列表,用于存储测试窗用户上传的图片,目前仅支持存储单张图片。
结束节点
组件
说明
输出模式
输出参数的格式,支持“文本输出”及“JSON 输出”两种模式。
文本框(仅在文本模式下生效)
可自由编排输出内容的段落格式,支持输入文本或引用变量,适合输出非结构化的内容。
变量名/变量值(仅在 JSON 模式下生效)
需按照 JSON 格式编排输出内容,可自定义变量名,支持输入文本或引用变量,适合输出结构化的内容。
结果返回
仅在 API 调用应用时生效,用于决定是否输出节点内容。如需了解该组件的用途,请参阅通过“结果返回”控制节点内容的方法。
知识库
为什么使用它
想象一下,你有一座巨大的“知识宝库”,里面存放了海量文档、FAQ、产品资料。这个节点能帮你从海量信息里提取“最相关”的内容,为后续 AI 问答做好准备。
功能与用法
通过搜索一个或多个知识库来得到相关文档片段,让 AI 能“读到”更多上下文,回答更专业或精准。常常与大模型节点结合使用。
在构建对话型工作流、智能客服系统时尤其常用。
参数配置
参数名
参数说明
输入
content:可直接输入文本,也可引用前面节点输出的变量 。imageList:支持图片搜索,可直接输入图片链接,也可引用前面节点输出的变量。选择知识库
指定要在哪些知识库里进行搜索(支持多选)。
输出
命名本节点的结果变量,如
kbResult。输出结构示例:
{ "rewriteQuery": "...", "chunkList": [ { "score": 0.36, "documentName": "文档名称", "title": "文档标题", "content": "相关内容片段", "imagesUrl": "图片URL" } ] }这里常用的就是
chunkList,含有文档内容片段及相似度分值。
搜索结果得分越高代表匹配度越强,可以在后续节点里对结果做过滤、排序或组合。
不支持本地的向量数据库,您需要将您的文件上传到知识库即可使用。
大模型
为什么使用它
这是整个工作流的“智慧大脑”——能读懂语言、生成文字、分析图像,还能参与多轮对话。你可以用它写文案、做文本总结、甚至对图片内容做分析(如果是 VL 系列模型)。
功能特性
既支持一次性处理一个输入,也能批量处理大量数据。
可以配置不同大模型(如通义千问-Plus),根据性能、速度或其他特性的需求选择合适的模型。
节点参数配置
参数名
参数说明
模式选择
单次处理模式:使用较低的搜索比例且不使用Query改写的快速搜索版本。
批次处理模式:在批处理模式中,节点会多次运行。每次运行时,列表中的一个项目会被依次分配给批处理变量。这个过程会一直持续,直到处理完列表中的所有项目或达到设定的最大批处理次数为止。
批处理配置:
批处理次数上限(范围1-100,普通用户默认100):批处理运行的次数上限。
说明实际批次处理次数取决于用户输入数组中的最小长度,若没有输入变量,则取决于配置中的批次数量。
并行运行数量(范围1-10):批处理的并发限制,设置为1表示串行执行所有任务。
模型配置
选择合适的大模型,支持模型参数调整,具体支持模型,请参见工作流应用。
模型选择VL模型时:
模型入参:vlImageUrl可引用参数或输入图片链接。
图片来源:可选图片集/视频帧。
图片集:模型会认为上传的图片是独立的,会根据问题匹配对应图片进行理解。
视频帧:模型会认为上传的图片来源于同一个视频,会把图片按序看作一个整体来理解,视频帧需不少于4张。
参数配置
温度系数:用于调节生成内容的多样性。较高的温度值将增加生成文本的随机性,产生更多独特的输出;而较低的温度值会使生成内容更为保守和一致。
DeepSeek R1 系列模型暂不支持此项配置
最长回复长度:限制模型生成文本的最大长度(不包括Prompt)。该限制因模型类型而异,具体最大值可能会有所不同。
System Prompt
可用于设定模型的角色、任务、输出格式等内容,如“你是一个数学专家,专业解决数学问题,请输出符合格式的数学解题过程和结果”。
User Prompt
配置Prompt模板,支持变量插入,大模型将根据Prompt的配置进行处理和生成。
输出
输出本节点处理结果的变量名,用于后续节点识别和处理本节点的结果。
DeepSeek R1 系列模型支持输出深度思考过程(reasoningContent)。
说明如需通过API集成应用到您的业务,请参阅应用调用。
对话型工作流下的大模型节点
与任务型工作流应用的大模型节点的不同:支持进行多轮对话配置,模型支持将选定的历史对话信息作为输入。
多轮对话配置:对话型应用会把前几轮对话中在“上下文”中要求的变量收集起来作为输入参数传给大模型。

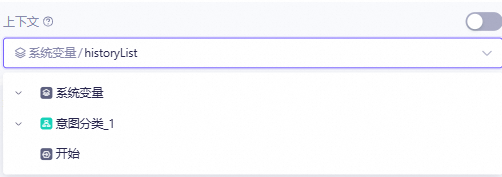
上下文:声明大模型需要的上下文输入,默认的 ${系统变量.historyList}代表的是前几轮对话的应用输入输出。其他参数均指的是前几轮对话中的应用参数。
文本模型节点示例
在测试界面,query参数中输入
芯片工程师: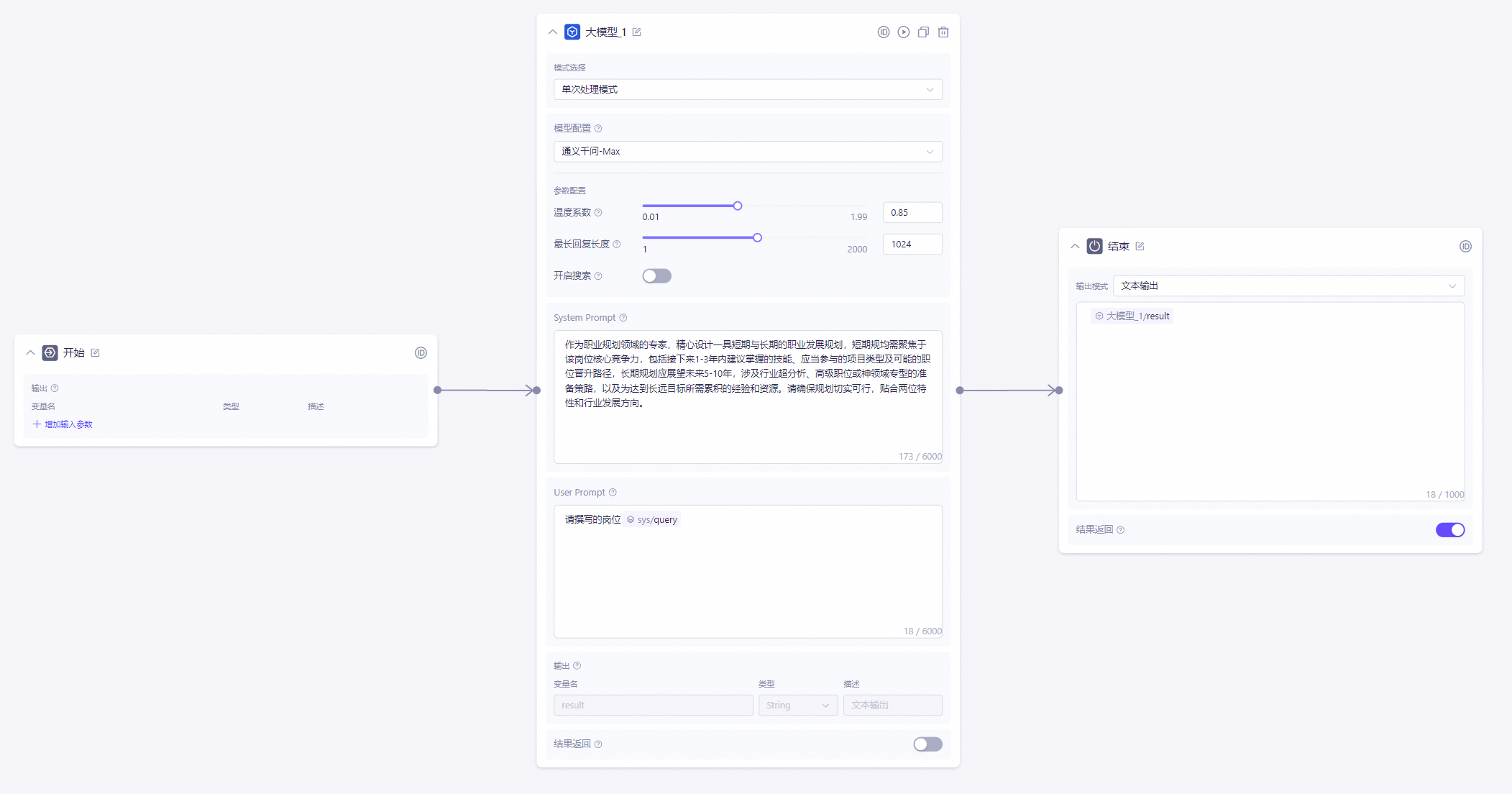
结束节点输出:

图像模型节点示例
大模型支持单个图像或多张图片传入,支持URL和base64方式传入。
说明单张图片可以直接传入。例如:
https://****.com/****.jpg。多张图片可列表传入。例如:
["URL","URL","URL"]。在测试界面,query参数中输入:
https://****.com/****.jpg。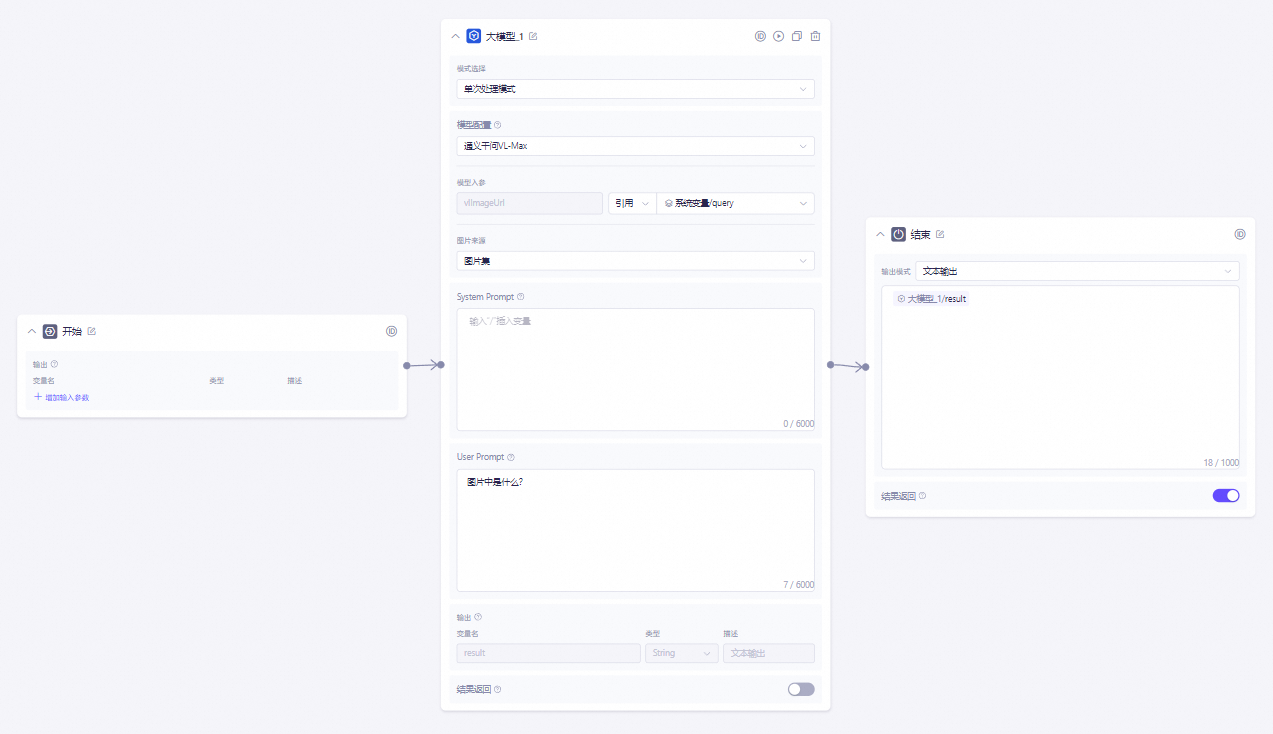
结束节点输出:

API
API 节点的默认超时限制为 5000ms,暂不支持调整。
为确保 API 节点能成功访问目标服务,请将百炼应用服务 IP 地址(
47.93.216.17和39.105.109.77)添加到您目标服务器的安全组(或防火墙)的入方向规则白名单中。
定义
通过POST、GET、PUT、PATCH、DELETE的方式,调用自定义API服务,输出API调用结果。
调用方式
用途
POST
用于向服务器提交数据,以创建新资源。
GET
用于获取资源的表示形式,不会对服务器上的数据进行修改。
PUT
用于向服务器更新指定资源的表示形式,或者在服务器上创建新资源。
PATCH
用于向服务器部分更新资源。
DELETE
用于从服务器删除指定资源。
参数配置
参数名
参数说明
API地址
填写要调用的API地址,可选POST、GET、PUT、PATCH、DELETE。
Header设置
设置Header参数,设置KEY,VALUE。
Param设置
设置Param参数,设置KEY,VALUE。
Body设置
可选:none,form-data,raw,JSON。
输出
输出本节点处理结果的变量名,用于后续节点识别和处理本节点的结果。
说明如需通过API集成应用到您的业务,请参阅应用调用。
节点示例
使用POST方法,调用接口。
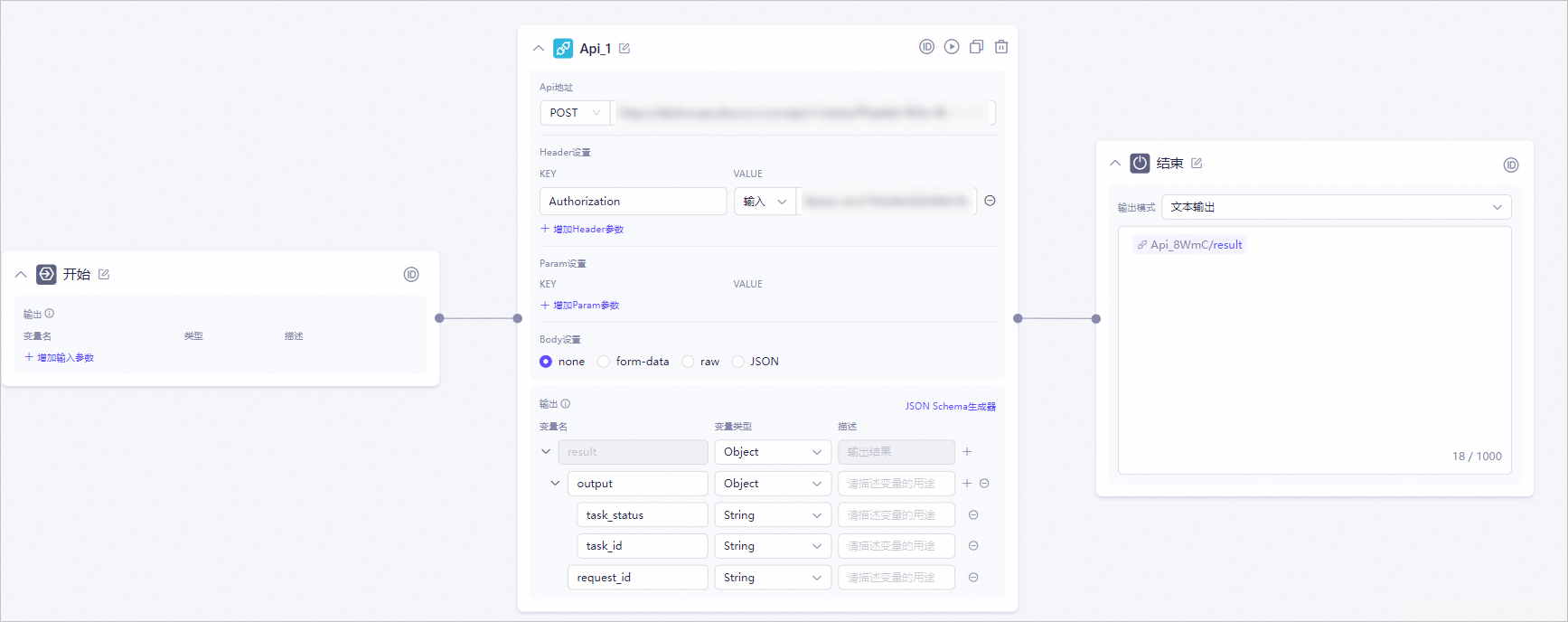
意图分类
定义
根据意图描述智能分类匹配,选择其中一个链路执行。
参数配置
参数名
参数说明
输入
输入本节点需要处理的变量,用于识别需要处理的内容,支持引用前置/开始节点变量或直接输入变量值。
模型配置
模型选择:通义千问-Plus。
意图配置
配置不同的意图,输入意图描述,模型将根据不同的意图描述匹配后续链路,如:“用于数学题的计算”,“关于天气相关的知识问答”。
其他意图
意图未匹配时,匹配此链路。
意图模式
单选模式:大模型将从现有的意图配置中挑选最合适的意图作为输出。
多选模式:大模型将从现有的意图配置中挑选所有匹配的意图作为输出。
思考模式
快速模式:该模式能够避免输出复杂的推理过程,从而提升处理速度,适用于简单场景。
效果模式:该模式通过逐步思考,能够更准确地匹配相应的分类。
高级配置
高级配置内容将作为额外的prompt提供给模型。在此,您可以输入更多限制条件或提供更多案例,从而使模型的分类结果更符合您的要求。
在该实例中,高级配置通过提供具体的分类案例,引导模型将“查询送达时间”归类为“订单查询”意图,同时限定了分类范围,排除了其他无关问题。
上下文
开启上下文能力后,系统将以Message格式自动记录历史对话信息,调用模型时传入上下文,模型将结合上下文内容进行生成。
仅在对话型工作流的意图分类节点中有该配置项。
说明若开启上下文,您传入该节点的变量类型需为List类型。
输出
输出本节点处理结果的变量名,用于后续节点识别和处理本节点的结果。
说明该节点在对话型工作流中支持上下文。
运行该节点将消耗Token,并在运行时显示其消耗数量。
文本转换
定义
用于文本内容的转换与处理,如抽取特定内容、格式转换等,支持模板模式。
参数配置
参数名
参数说明
输出模式
支持文本输出和JSON输出。
输入
通过大模型指定处理方式将需要处理内容转换为特定格式,用于后续节点的处理,可通过变量配置的方式引用前置节点的处理结果。
文本输出:输入
/可插入变量。JSON输出:变量名 | 引用/输入 | 变量。
节点示例
以下是一个简单的文本转换节点示例。其工作流程逻辑如下:首先,用户输入一个关键词。然后,这个关键词被传递给文本转换节点,节点内部根据该关键词进行处理,生成相应的输出回复。最后,回复通过结束节点输出,从而完成整个流程。
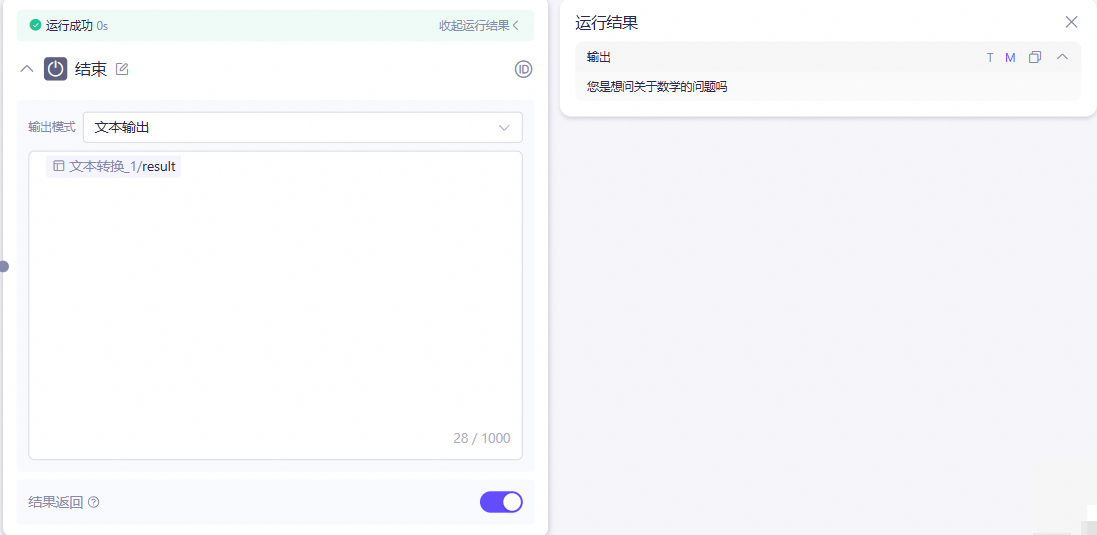
在测试界面,query参数中输入
数学: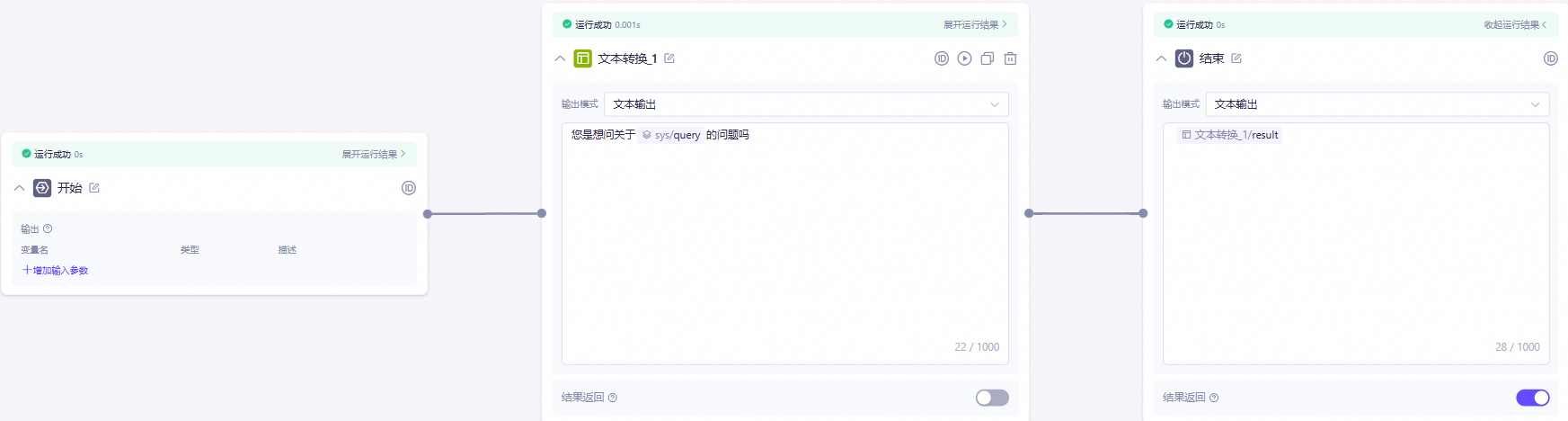
结束节点输出:
脚本转换
定义
通过脚本代码处理,将输入内容转化为特定格式的模板或输出形式。该过程包括对输入数据的解析、转换和格式化,以实现一致性和可读性。
节点示例
这是一个 Python 脚本转换示例:从上游节点传入
city和date两个变量,保存在键值对params中。转换后输出一个 JSON 对象,包含result,result.key0及result.key1。代码返回值的 JSON Schema 与节点输出的必须保持一致。说明什么是 JSON Schema?
JSON Schema 是一种数据结构规范,能让平台中的其他节点清晰地了解当前节点会输出哪些字段(如
result,key1)及其类型,从而方便您在下游节点中进行引用。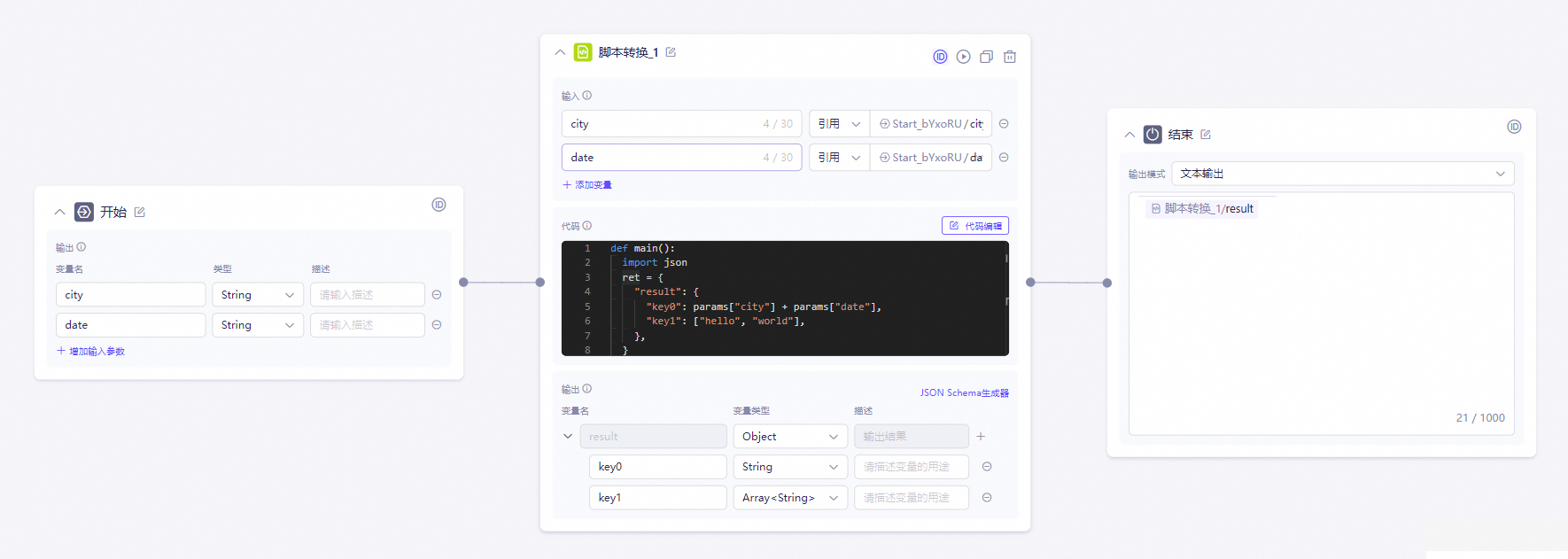
参数配置
参数名
参数说明
输入
定义该节点的输入数据。您可以通过两种方式提供输入:
静态值(输入):在左侧的输入面板中直接填写固定的值,如
北京。动态变量(引用):引用上游节点的输出。例如,若上一个节点名为
node_a,其输出名为city_name的字段,您可以选择node_a.output.city_name来引用它。
输出
节点的代码逻辑所产生的结果。代码中
return的字典将作为本节点的输出。例如,若返回
{'result': '处理成功'},下游节点就可以通过本节点名.result来获取“处理成功”这个字符串。代码
编写核心逻辑代码。
获取输入:请使用内置的
params对象获取输入参数。返回输出:处理函数
main必须return一个 字典/对象,其键值对将构成节点的输出。
条件判断
定义
设置条件分支。当变量满足条件后,流程将选择相应的后续链路。支持且/或条件配置,多个条件是从上而下按顺序执行。
参数配置
参数名
参数说明
条件分支
填写条件判断语句。
其他
不需要条件判断的可从此输出。
节点示例
以下是一个简单的条件判断节点示例。其工作流程逻辑如下:用户首先输入两个参数,这些参数随后被传递给条件判断节点。在节点内部对参数进行条件判断,然后通过不同分支的文本转换节点生成输出回复。最后,结束节点将生成的回复输出。
在测试界面,scert参数中输入
12345,admin参数中输入admin: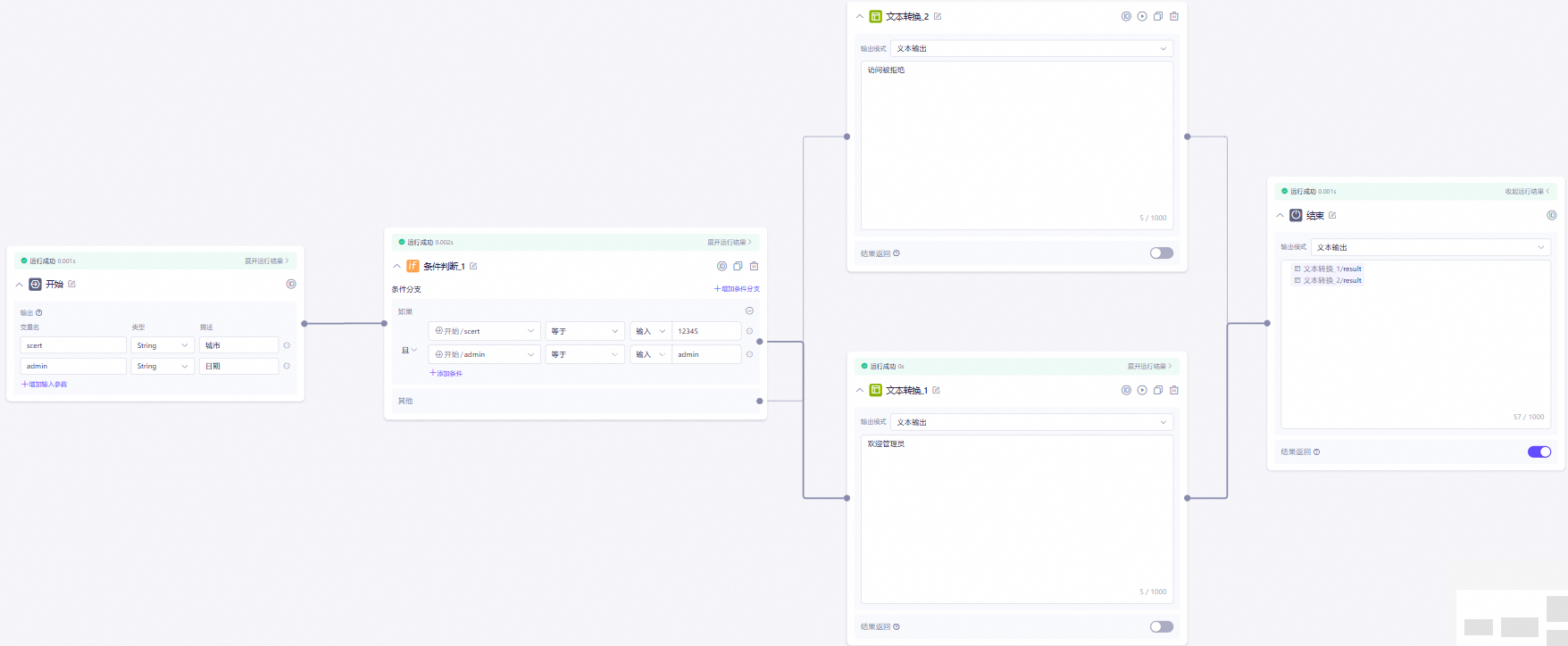
结束节点输出:
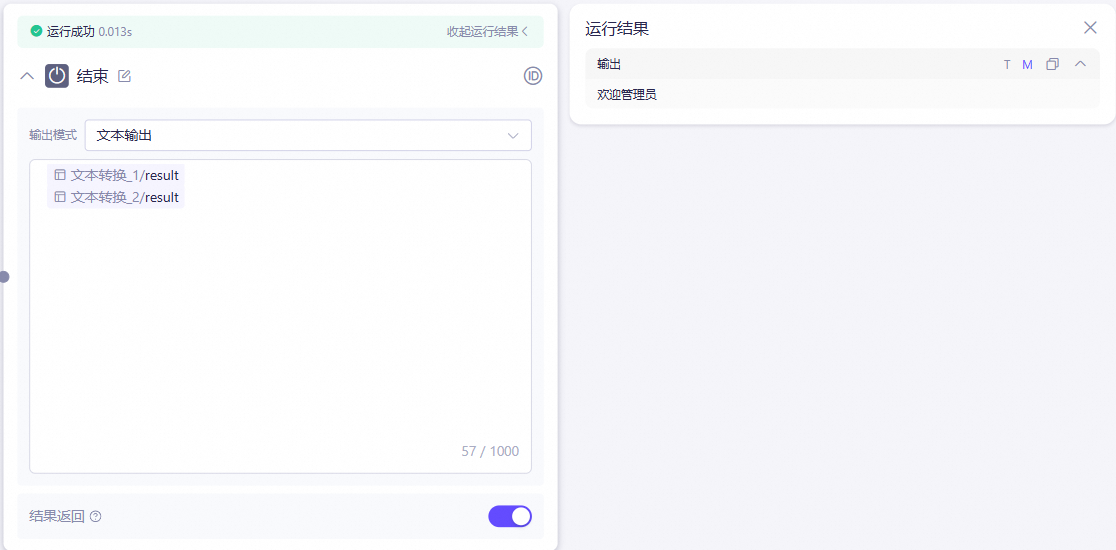
函数计算
定义
授权阿里云函数计算服务,调用函数计算中自定义的服务。
参数配置
参数名
参数说明
输入
输入本节点需要处理的变量,用于识别需要处理的内容,支持引用前置/开始节点变量或直接输入变量值。
Region
选择地域:新加坡、吉隆坡、雅加达。
服务配置
选择服务配置。
输出
输出本节点处理结果的变量名,用于后续节点识别和处理本节点的结果。
插件
定义
您可以将插件节点配置到工作流应用中以拓展应用能力,执行更复杂的任务。阿里云百炼提供了一系列官方插件,例如夸克搜索、计算器、Python代码解释器等,您也可以根据特定需求创建自定义插件。
更多信息,请参见插件概述。
发布应用
发布后的应用可以被API调用,也可以通过Web页面分享给同一主账号下的RAM子账号使用。您可以单击智能体应用管理界面右上角的发布按钮。
通过API调用
您可以在工作流应用分享渠道页签,单击API调用,查看通过API调用智能体应用的方法。
注:您需用您的API KEY对YOUR_API_KEY进行替换才可发起调用。

关于API调用的相关问题总结:
关于调用方式(HTTP/SDK),请参见应用调用。
关于调用接口的详细参数信息,请参见应用调用参数信息。
关于调用参数传递问题,请参见应用的参数传递。
关于调用报错信息,请参见错误信息进行解决。
关于调用并发数限制问题,应用本身不限流,主要与您内部调用的模型有关,有关模型内容请参见模型列表。
目前不支持在工作流中调用析言服务,可以通过API节点调用自定义的API服务。
API调用的超时时间为 300 秒,暂不支持修改。
其他调用方式(对话型工作流应用)
其他分享方式,请参见应用分享。
查看工作流应用版本
|
|
|
|
|
|

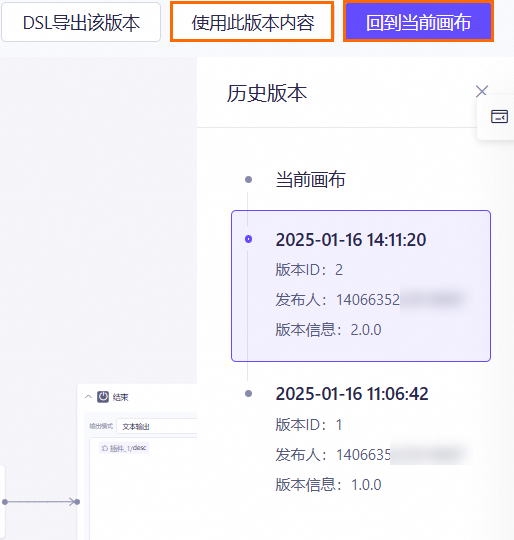
删除与复制工作流应用
您可以在应用管理找到已发布的应用卡片,在进行删除与复制工作流、修改应用名操作。 |
|