为了更好地融入大数据生态,并支持外部引擎访问MaxCompute中的数据,MaxCompute提供了开放存储(Storage API)。第三方主流计算引擎可通过调用Storage API直接访问MaxCompute的底层存储,从而显著提升数据访问和交互效率。
开放存储介绍
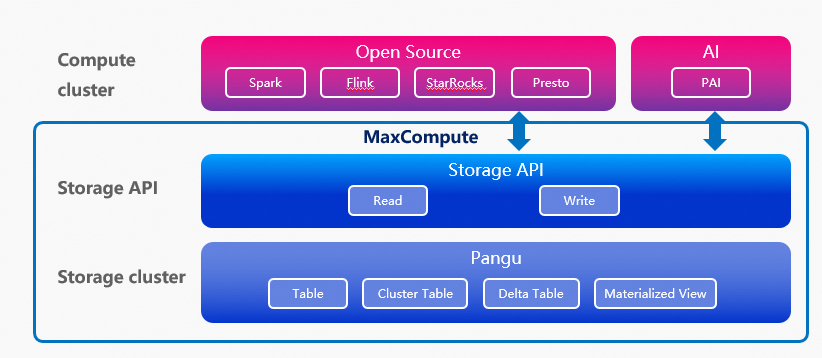
开放存储(Storage API)是一种数据服务接口,提供了高效、低延迟、安全的数据访问方式,支持第三方主流计算访问MaxCompute的存储系统,提升了MaxCompute与开源计算引擎和机器学习引擎的集成度和数据处理效率。其中,Spark、StarRocks、Presto和Flink还直接通过Connector访问存储在MaxCompute中的数据,更加简化了数据使用过程,提高了数据访问性能。架构图如下:
应用场景
开放存储(Storage API)可应用于数据开放与多引擎计算场景,当企业或开发者需要在不同的计算框架间灵活切换,或者利用特定引擎的特性处理MaxCompute中的数据时,Storage API可以作为桥梁促进数据流通和处理的多样化。
关键特性
高吞吐:具备列级高效读取的能力,支持在数据传输前通过谓词下推来过滤数据,同时支持Arrow格式。
安全易用:提供Table语义直读底层存储,屏蔽存储细节,同时满足项目隔离、权限控制、数据加密等安全策略。
生态融合:Spark on EMR和StarRocks可直接通过Connector访问MaxCompute的数据,简化了计算引擎的集成过程。
适用范围
第三方引擎访问MaxCompute时,支持读取普通表、分区表、聚簇表、Delta Table和物化视图;不支持读取MaxCompute的外部表、逻辑视图。
不支持读JSON数据类型。
开放存储(按量付费)每个租户的请求并发数限制为不超过1000个,每个并发传输速率限制为不超过10 MB/s。
数据传输资源
第三方引擎通过MaxCompute开放存储进行数据传输任务时,可选择使用数据传输服务独享资源组(包年包月)资源。详细介绍如下。
资源组名称 | 费用说明 | 支持地域 | 使用说明 |
包年包月,按购买并发数的数量计费。 |
|
在资源观测页面,可查看数据传输服务独享资源组(包年包月)的使用详情,请参见资源观测。
使用示例
通过Connector访问MaxCompute,详情请参见:
通过SDK访问MaxCompute,详情请参见:
Arrow数据类型映射
MaxCompute 开放存储(Storage API)基于Apache Arrow数据类型,确保数据在存储和传输过程中保持高效的结构化表示。在使用MaxCompute Storage API写入数据时,不会对数据进行计算或加工处理(如Map数据去重),当存储引擎无特殊限制时,将保留原始数据结构。
MaxCompute与Apache Arrow数据类型映射表,如下所示:
MaxCompute数据类型 | Arrow数据类型 |
TINYINT | Int8Type |
SMALLINT | Int16Type |
INT | Int32Type |
BIGINT | Int64Type |
FLOAT | FloatType |
DOUBLE | DoubleType |
BOOLEAN | BooleanType |
DECIMAL | Decimal128Type 说明 MaxCompute DECIMAL类型比Storage API Decimal128Type精度更高:
|
DECIMAL(precision, scale) | Decimal128Type |
STRING | StringType |
BINARY | BinaryType |
VARCHAR | StringType |
CHAR | StringType |
DATETIME | TimestampType[1] TimeUnit为毫秒,timezone为UTC。 |
TIMESTAMP | TimestampType[2] TimeUnit为纳秒,timezone为UTC。 说明 TIMESTAMP类型支持的值域范围更广,使用Storage API读写TIMESTAMP类型数据超出TimestampType精度范围时,高精度部分的值会被截断,此时会出现精度丢失的情况。 |
DATE | Date32Type |
INTERVAL_DAY_TIME | DayTimeIntervalType 说明 INTERVAL_DAY_TIME类型支持到纳秒,Storage API DayTimeIntervalType类型支持到毫秒,使用Storage API读写 INTERVAL_DAY_TIME 数据时,纳秒部分信息会被截断,此时会出现精度丢失的情况。 |
INTERVAL_YEAR_MONTH | MonthIntervalType |
ARRAY | ListType |
MAP | MapType 说明 如果MAP中存在重复Key (Duplicate Key) ,
例如:写入原始数据: |
STRUCT | StructType |
JSON | StringType |