本文介绍如何基于MaxCompute创建面向Hologres的元数据映射和数据同步。
背景信息
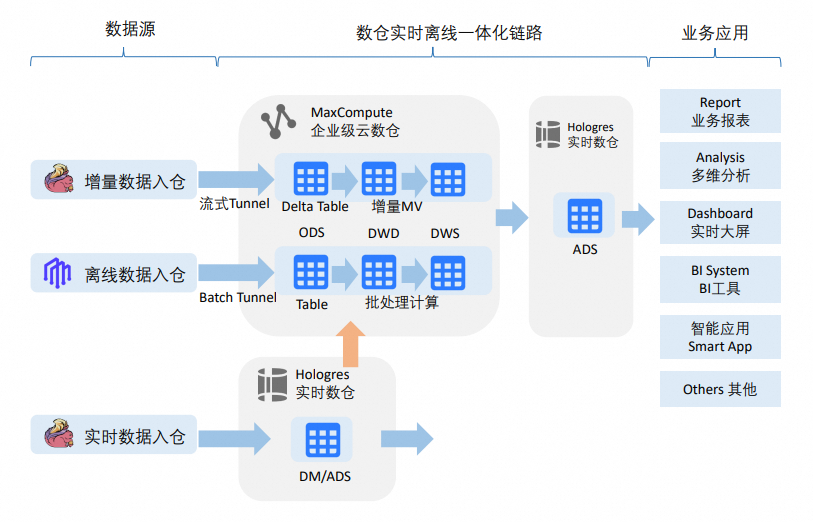
传统数仓架构将上游实时或批量数据写入数仓,并使用OLAP引擎分析(图示上半部分)。但部分场景需要在MaxCompute中读取Hologres的数据(图示下半部分),例如:
实时数据透出与归档:数据需要从实时数据源快速透出到业务,完成实时数仓业务需求后,数据归档到企业级数仓对应分层和主题域。
业务先行与数据回流:没有经过数仓统一处理,先满足业务需求,但是数据集市稳定后,仍然需要回流到企业级数仓,和DWD、DWS等融合。
这两种场景的数据访问方式包括:
数仓模型迭代完善过程中浏览实时数仓中的数据。
实时数仓或数据集市的数据定期归档入企业级数仓。
企业级数仓加工后的数据写入Hologres ADS层,供业务消费。
功能介绍
本教程构建了从MaxCompute到Hologres的元数据映射链路,具体功能如下:
Schema级别元数据映射:可基于RAMRole权限认证方式,通过外部Schema实时读取Hologres元数据和数据,进行Schema级别的数据访问。
单表级元数据映射:可在Hologres数据目录中选择目标表,一键自动创建映射Hologres表的MaxCompute外部表。
数据同步:可将需要周期同步的表一键配置为数据同步任务,满足周期性地向企业级数仓同步的需求。
MaxCompute和Hologres之间的数据类型映射存在差异,Hologres部分数据类型不支持同步至MaxCompute。
数据同步流程
本教程基于使用Flink+Hologres搭建的实时数仓,在Hologres实时数仓的DWD层,增加了MaxCompute映射Hologres Schema、Table,并从DWD层表中同步数据的流程。具体如下: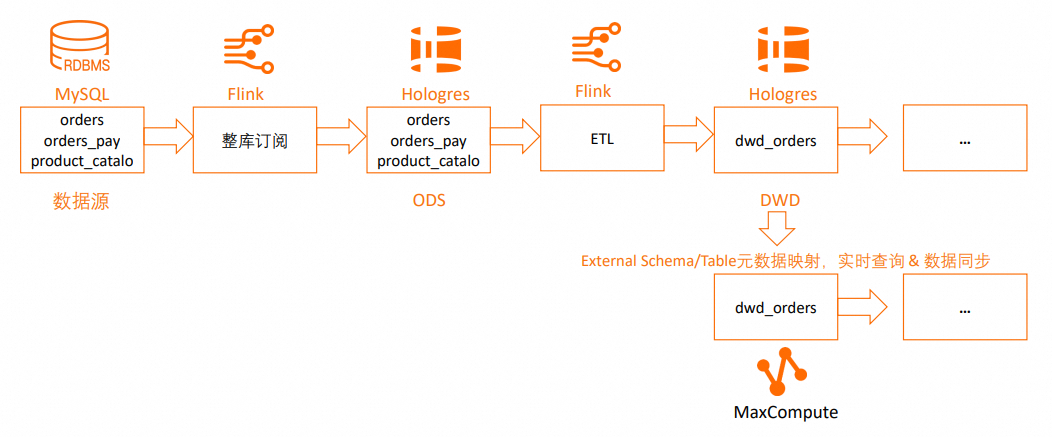
支持:
通过External Schema映射Hologres的Schema;
通过External Table映射Hologres的Table;
指定Hologres的表进行一次性或周期性数据同步。
操作步骤
前置准备
已创建RAM角色并配置信任策略。
已开通RDS
已开通Hologres
已开通Flink
步骤一:创建RDS MySQL并准备数据源
登录RDS 控制台。
在左侧导航栏,选择实例列表,在左上角选择地域。
在实例列表页面,单击创建实例。
本示例中计费方式选择按量付费,引擎选择MySQL 8.0。
在实例列表页面,单击目标实例ID/名称,进入实例详情页。
在左侧导航栏,单击账号管理。
创建数据库登录账号。
在左侧导航栏,单击数据库管理。
单击新建数据库。配置如下参数:
参数
是否必填
说明
示例
数据库(DB)名称
必填
长度为2~64个字符。
以字母开头,以字母或数字结尾。
由小写字母、数字、下划线或中划线组成。
数据库名称在实例内必须是唯一的。
数据库名称中如果包含
-,则创建出的数据库文件夹名字中的-会变成@002d。
hologres_test授权账号
选填
此处仅会显示普通账号。高权限账号拥有所有数据库的所有权限,无需授权。
选择刚刚创建的登录账号。单击登录数据库,在左侧导航栏选择数据库实例,双击选中已创建的数据库,在右侧SQLConsole页面执行下列语句,创建测试表并写入测试数据。
CREATE TABLE `orders` ( order_id bigint not null primary key, user_id varchar(50) not null, shop_id bigint not null, product_id bigint not null, buy_fee numeric(20,2) not null, create_time timestamp not null, update_time timestamp not null default now(), state int not null ); CREATE TABLE `orders_pay` ( pay_id bigint not null primary key, order_id bigint not null, pay_platform int not null, create_time timestamp not null ); CREATE TABLE `product_catalog` ( product_id bigint not null primary key, catalog_name varchar(50) not null ); -- 准备数据 INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee'); INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000.05, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1), (100002, 'user_002', 12346, 2, 4000.04, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1), (100003, 'user_003', 12347, 3, 3000.03, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1), (100004, 'user_001', 12347, 4, 2000.02, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1), (100005, 'user_002', 12348, 5, 1000.01, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1), (100006, 'user_001', 12348, 1, 1000.01, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1), (100007, 'user_003', 12347, 4, 2000.02, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, '2023-02-15 17:40:56'), (2002, 100002, 1, '2023-02-15 17:40:56'), (2003, 100003, 0, '2023-02-15 17:40:56'), (2004, 100004, 0, '2023-02-15 17:40:56'), (2005, 100005, 0, '2023-02-15 18:40:56'), (2006, 100006, 0, '2023-02-15 18:40:56'), (2007, 100007, 0, '2023-02-15 18:40:56');
步骤二:创建Hologres实例并新建数据库
登录Hologres管理控制台,在左上角选择地域。
如果没有实例,先购买Hologres。
商品类型选择独享实例(按量付费)
实例类型选择计算组型
计算组预留计算资源选择64 CU
在实例列表页面,单击目标实例名称。
在实例详情页面,单击登录实例。
单击上方元数据管理页签。
单击新建数据库,在弹出的对话框中,填写数据库名称,其他参数保持默认。
示例Hologres数据库名为
holodb。单击上面安全中心页签。
在左侧导航栏选择用户管理。
步骤三:在Flink中创建RDS MySQL整库同步任务-ODS层表
在Flink中创建RDS MySQL整库同步任务,将RDS MySQL中的数据同步至Hologres数据库
holodb的publicSchema下,并使用Hologres的默认计算组init_warehouse查询ODS数据。MySQL需要提前开启Binlog,可以在RDS MySQL的数据库中执行
show variables like "log_bin";命令,查看Binlog是否开启。详情请参见MySQL服务器配置要求。创建Session集群。
登录Flink控制台,在左上角选择地域。
单击目标工作空间名称,然后在左侧导航栏,选择。
单击创建Session集群。
创建Hologres Catalog
单击目标工作空间名称,然后在左侧导航栏,选择数据管理。
在右侧Catalog列表界面,单击创建Catalog。在弹出的创建 Catalog对话框里,选择Hologres,单击下一步 并配置如下参数:
参数
是否必填
说明
catalog name
必填
自定义MySQL Catalog名称。
endpoint
必填
endpoint在Hologres实例详情页面,网络信息部分指定VPC处获取:
hg****cn-cn-2****f-cn-shenzhen-vpc-st.hologres.aliyuncs.com:80。dbname
必填
Hologres数据库名
username
必填
Access Key ID。
password
必填
Access Key Secret。
创建MySQL Catalog
在右侧Catalog列表 界面,单击创建Catalog 。在弹出的创建 Catalog 对话框里,选择MySQL,单击下一步 并配置如下参数:
参数
是否必填
说明
catalog name
必填
自定义MySQL Catalog名称。
hostname
必填
MySQL数据库的IP地址或者Hostname。
可登录RDS MySQL控制台,在数据库实例详情页,单击数据库连接查看数据库内网地址、外网地址及内网端口。
在跨VPC或公网访问时需要打通网络,详情请参见网络连通性。
port
默认
连接到服务器的端口,默认为3306。
default database
必填
默认数据库名称。
username
必填
连接MySQL数据库服务器时使用的用户名。可登录RDS MySQL控制台,在数据库实例详情页,单击账号管理查看。
password
必填
连接MySQL数据库服务器时使用的密码。可登录RDS MySQL控制台,在数据库实例详情页,单击账号管理查看。
通过Flink将RDS MySQL数据同步至Hologres中
单击目标工作空间名称,然后在左侧导航栏,选择。
在作业草稿页签,单击
 ,新建文件夹。
,新建文件夹。右键文件夹,选择新建流作业,在弹出的新建作业草稿对话框,填写文件名称并选择引擎版本。
CREATE DATABASE IF NOT EXISTS <your hologres catalog>.<hologres database name> -- 创建catalog时设置了table_property.binlog.level参数,因此通过CDAS创建的所有表都开启了binlog。 AS DATABASE <your mysql catalog>.<mysql database name> INCLUDING all tables -- 可以根据需要选择上游数据库需要入仓的表。 /*+ OPTIONS('server-id'='8001-8004') */ ; -- 指定mysql-cdc实例server-id范围。单击右上角部署。
在作业运维页面,单击目标作业名称,进入作业部署详情页面。
在目标作业部署详情页右上角,单击启动,选择无状态启动后,单击启动。
说明本示例默认将数据同步到Hologres数据库的public Schema下。也可以将数据同步到Hologres目标库的指定Schema中,详情请参见作为CDAS的目标端Catalog,指定后使用Catalog时的表名格式也会发生变化,详情请参见使用Hologres Catalog。
如果源表的数据结构发生变化,则需要等待源表的数据出现变更(删除、插入、更新),结果表的数据结构才会看到变化。
步骤四:向Hologres加载数据
Table Group是Hologres中数据的载体。
使用计算组init_warehouse查询holodb数据库中Table Group(本示例为order_dw_tg_default)的数据时,需要为计算组加载Table Group,然后才可以使用init_warehouse计算组查询及写入数据。
在HoloWeb开发页单击SQL编辑器,确认实例名和数据库名称后,执行如下命令。
更多详情请参见创建新计算组实例。
登录Hologres管理控制台,在左上角选择地域。
在左侧导航栏选择实例列表。
在实例列表页面,单击目标实例名称。
在实例详情页面,单击登录实例。
单击上方SQL编辑器页签。
确认实例名和数据库名称后,执行如下命令。加载后,可以查看到计算资源组已经加载了
holodb_tg_defaultTable Group的数据。--查看当前数据库有哪些Table Group SELECT tablegroup_name FROM hologres.hg_table_group_properties GROUP BY tablegroup_name; --为计算组加载Table Group CALL hg_table_group_load_to_warehouse ('<hologres database name>.<table group name>', '<your Virtual Warehouse name>', 1); --查看计算组加载Table Group的情况 SELECT * FROM hologres.hg_warehouse_table_groups;执行如下命令,查看MySQL同步到Hologres的3张表数据。
---查orders中的数据。 SELECT * FROM orders; ---查orders_pay中的数据。 SELECT * FROM orders_pay; ---查product_catalog中的数据。 SELECT * FROM product_catalog;
步骤五:在Flink中创建DWD层表
构建DWD层用到了Hologres连接器特有的部分列更新能力,可以使用INSERT DML方便地表达部分列更新的语义。作业中需要对不同的维表进行查询,是基于Hologres行存以及行列共存表提供的高性能的点查能力。同时,Hologres资源强隔离的架构,可以保证写入、读取、分析等作业之间互不干扰。
通过Flink Catalog功能在Hologres中创建DWD层的宽表dwd_orders。
登录Flink控制台,在左上角选择地域。
单击目标工作空间名称,然后在左侧导航栏,选择。
在查询脚本页签,单击
 ,新建查询脚本。
,新建查询脚本。输入如下代码后,单击右上角运行。
-- 宽表字段要nullable,因为不同的流写入到同一张结果表,每一列都可能出现null的情况。 CREATE TABLE <hologres catalog>.<hologres database>.dwd_orders ( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int comment 'platform 0: phone, 1: pc', pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ); -- 支持通过catalog修改Hologres物理表属性。 ALTER TABLE <hologres catalog>.<hologres database>.dwd_orders SET ( 'table_property.binlog.ttl' = '604800' --修改binlog的超时时间为一周。 );实现实时消费ODS层
orders、orders_pay表的binlog。单击目标工作空间名称,然后在左侧导航栏,选择。
新建名为DWD的SQL流作业,并将如下代码拷贝到SQL编辑器后,部署并启动作业。
orders会与product_catalog维表关联,并将最终结果写入dwd_orders表中,实现数据的实时打宽。BEGIN STATEMENT SET; INSERT INTO <your hologres catalog name>.<your hologres database name>.dwd_orders ( order_id, order_user_id, order_shop_id, order_product_id, order_fee, order_create_time, order_update_time, order_state, order_product_catalog_name ) SELECT o.*, dim.catalog_name FROM <your hologres catalog name>.<your hologres database name>.orders as o LEFT JOIN <your hologres catalog name>.<your hologres database name>.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim ON o.product_id = dim.product_id; INSERT INTO <your hologres catalog name>.<your hologres database name>.dwd_orders (pay_id, order_id, pay_platform, pay_create_time) SELECT * FROM <your hologres catalog name>.<your hologres database name>.orders_pay; END;查看宽表
dwd_orders数据。在HoloWeb开发页面连接Hologres实例并登录目标数据库后,在SQL编辑器上执行如下命令。
SELECT * FROM dwd_orders;运行结果:
+------------+---------------+---------------+------------------+----------------------------+------------+-------------------+-------------------+-------------+------------+--------------+-----------------+ | order_id | order_user_id | order_shop_id | order_product_id | order_product_catalog_name | order_fee | order_create_time | order_update_time | order_state | pay_id | pay_platform | pay_create_time | +------------+---------------+---------------+------------------+----------------------------+------------+-------------------+-------------------+-------------+------------+--------------+-----------------+ | 100002 | user_002 | 12346 | 2 | phone_bbb | 4000.04 | 2023-02-15 15:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100004 | user_001 | 12347 | 4 | phone_ddd | 2000.02 | 2023-02-15 13:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 11111 | user_test | 12346 | 2 | phone_bbb | 4000.04 | 2025-12-15 00:00:00 | 2025-12-15 00:00:00 | 1 | NULL | NULL | NULL | | 100001 | user_001 | 12345 | 1 | phone_aaa | 5000.05 | 2023-02-15 16:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100007 | user_003 | 12347 | 4 | phone_ddd | 2000.02 | 2023-02-15 10:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100006 | user_001 | 12348 | 1 | phone_aaa | 1000.01 | 2023-02-15 11:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100005 | user_002 | 12348 | 5 | phone_eee | 1000.01 | 2023-02-15 12:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100003 | user_003 | 12347 | 3 | phone_ccc | 3000.03 | 2023-02-15 14:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | +------------+---------------+---------------+------------------+----------------------------+------------+-------------------+-------------------+-------------+------------+--------------+-----------------+
dw中分别绑定MC项目和holo实例
回到mc创建外部schema
步骤六:在DataWorks中绑定MaxCompute和Hologres计算资源
登录DataWorks控制台,在左上角选择地域。
创建新版DataWorks工作空间。本教程中工作空间名称设置为
Hologres_DW_TEST。在工作空间列表页面,单击目标工作空间名称。
在空间详情页面,单击左侧导航栏计算资源。
在计算资源页面,单击绑定计算资源,分别选择MaxCompute和Hologres。
填写基本信息,具体操作请参见绑定计算资源。
添加及查看MaxCompute项目和Hologres实例。
在左侧导航栏选择。
选择工作空间,单击进入Data Studio。
添加及查看MaxCompute项目和Hologres实例。
步骤七:创建映射Hologres Schema的MaxCompute外部Schema
通过外部Schema映射Hologres表,无需在MaxCompute内创建含有DDL元信息的表,Hologres源端表结构变化或数据变化,元数据和数据都会在MaxCompute实时感知并查询获取。
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择 。
在外部数据源页面,单击创建外部数据源。
在弹出的新增外部数据源对话框,根据界面提示配置相关参数。参数说明如下:
参数
是否必填
说明
外部数据源类型
必填
选择Hologres。
外部数据源名称
必填
可自定义命名。命名规则如下:
以字母开头,且只能包含小写字母、下划线和数字。
不能超过128个字符。
例如
holo_external_source。外部数据源描述
选填
根据需要填写。
连接方式
必填
默认为经典网络访问(内网)。
InstanceID
必填
选择当前地域下需要连接的Hologres实例。
Host
必填
系统默认生成。
Port
必填
系统默认生成。
DBNAME
必填
连接的Hologres数据库名称。
认证和鉴权
必填
云RAM角色
任务执行者身份:Hologres外部项目所需外部数据源需要配置为任务执行者身份的认证模式。
RoleARN
必填
RAM角色的ARN信息。
登录RAM控制台。
在左侧导航栏选择。
在基础信息区域,可以获取ARN信息。
示例:
acs:ram::124****:role/aliyunodpsdefaultrole。关联服务角色
必填
若选择任务执行者身份,关联服务角色为
acs:ram::124****:role/aliyunserviceroleformaxcomputeidentitymgmt。外部数据源补充属性
选填
特殊声明的外部数据源补充属性。指定后,使用此外部数据源的任务可以按照参数定义的行为访问源系统。
说明支持的具体参数请关注后续官网文档更新说明,具体参数将随产品能力演进逐步放开。
步骤八:在DataWorks中映射Hologres实例和MaxCompute的Schema
登录DataWorks控制台,在左上角选择地域。
在左侧导航栏选择。
选择工作空间,单击进入Data Studio。
在Data Studio页面,单击左侧导航栏的
 图标,进入数据目录。
图标,进入数据目录。展开Hologres数据目录,右键单击目标实例的Schema(本教程中为
public),选择元数据映射至 MaxCompute。在元数据映射至 MaxCompute页面中配置Hologres源端和MaxCompute目标端的参数。
本教程中重点参数配置如下,其余参数保持默认即可。
参数名
描述
项目查找方式
选择来自 DataWorks 数据源。
数据源
选择已绑定至DataWorks的MaxCompute计算资源名称。
外部Schema名称
指定源端Hologres Schema下的元数据映射至目标MaxCompute的外部Schema名称。
本教程中配置为
public。外部数据源
选择MaxCompute中已创建的Hologres联邦数据源名称。
本教程中为
holo_external_source。单击页面左上角的运行。
运行成功后,可看到和Hologres Schema(public)同名的MaxCompute外部Schema。
可直接浏览Hologres中的表,并在MaxCompute中使用如下SQL命令查询数据。
SET odps.namespace.schema=true; SELECT * FROM public.dwd_orders;
若Schema级映射运行成功,但在数据目录的MaxCompute目录下无法显示映射后的表名,显示查询失败,请确认创建的RAM角色权限是否配置正确。详情请参见创建RAM角色。
不同于外部Schema,外部表需要将Hologres表在MaxCompute内建为外部表。外部表支持RAMRole和双签名两种认证方式:
RAMRole:支持跨账号角色扮演。您需在Hologres侧,完成以下操作:
双签名:使用当前执行任务的用户身份鉴权。即当前用户在Hologres中拥有哪些表的权限,通过MaxCompute外部表,也可使用此身份访问Hologres数据。详情请参见Hologres外部表。
步骤九:创建映射Hologres Table的MaxCompute外部表
可挑选部分或全部字段进行映射,映射规则请参见参数说明的tblproperties参数部分。
登录DataWorks控制台,在左上角选择地域。
在左侧导航栏选择。
选择工作空间,单击进入Data Studio。
在Data Studio页面,单击左侧导航栏的
图标,进入数据目录。展开Hologres数据目录,右键单击目标实例
publicSchema下的dwd_orders表,选择元数据映射至 MaxCompute。在元数据映射至 MaxCompute页面中配置Hologres源端和MaxCompute目标端的参数。
本教程中重点参数配置如下,其余参数保持默认即可。参数详情请参见单表级元数据映射。
参数名
描述
实例查找方式
选择来自 DataWorks 数据源。
数据源
选择已绑定至DataWorks的MaxCompute数据源名称。
Schema
指定源端Hologres Schema下的元数据映射至目标MaxCompute的外部Schema名称。
本教程中配置为
default。External Table
指定MaxCompute中新创建的外表名称,源端表数据将会被映射至此表中,默认与Hologres中表名称保持一致。
创建外表为一次性动作,不会自动刷新元数据,如需刷新元数据,需要删除当前外表并重新手动创建元数据映射。
MaxCompute 外表权限
选择双签名。
选择RamRole方式时,需要在Hologres侧添加用户,并DB授权。
生命周期
设置表的生命周期。
单击页面左上角的运行。
运行成功后,即可在左侧MaxCompute Schema下显示新建的外部表。
使用如下语句在MaxCompute中查询该外部表的数据。
SET odps.namespace.schema=true; SELECT * FROM dwd_orders;
步骤十:创建同步Hologres Table的周期任务
若需要周期性地将Hologres实时数仓中的DWD表数据归档到MaxCompute云数仓的一张内部表中,可以使用数据同步任务,并配置周期调度实现。
登录DataWorks控制台,在左上角选择地域。
在左侧导航栏选择。
选择工作空间,单击进入Data Studio。
在Data Studio页面,单击左侧导航栏的
 图标,进入数据开发页面,并新建项目目录。
图标,进入数据开发页面,并新建项目目录。在Data Studio页面,单击左侧导航栏的
图标,进入数据目录。展开Hologres数据目录,右键单击目标实例
publicSchema下的dwd_orders表,选择数据同步至 MaxCompute。在元数据映射至 MaxCompute页面中配置Hologres源端和MaxCompute目标端的参数。
本教程中重点参数配置如下,其余参数保持默认即可。参数详情请参见单表级元数据映射。
在新建节点弹框中,为云数仓内的表命名
dwd_holo_orders,单击确认。进入同步Hologres数据至MaxCompute的配置页面,配置Hologres源端和MaxCompute目标端的参数。本教程中重点参数配置如下,更多参数说明请参见配置同步节点。
参数名
描述
数据源
选择已绑定至DataWorks的Hologres数据源名称。
Schema
选择想要存储的Schema。
Table
自定义MaxCompute内部表名称。
本教程中配置为
dwd_holo_orders。生命周期
设置表的生命周期。
导入方式
选择数据写入MaxCompute内表的方式:
覆盖:需要删除原有数据,将新数据写入到目标表时,选择覆盖写入。
追加:需要保留原有数据,将新数据追加到目标表时,选择追加写入。
访问 Hologres 权限
根据实际情况选择以下方式访问Hologres实例:
双签名访问方式:通过当前身份进行Hologres权限校验。
确保在MaxCompute项目下,拥有MaxCompute表读取权限的同时,也需要有该MaxCompute表对应的Hologres源表权限。
RamRole访问方式:通过指定RAM角色进行访问身份校验。
为RAM用户授权
AliyunSTSAssumeRoleAccess权限策略。详情请参见RAM角色授权模式。授权完成后,在RamRole中配置指定的RAM角色。
单击页面右侧的调度配置,在调度配置页面中配置工作流和调度周期,操作详情请参见节点调度配置。
单击页面左上角的运行。
运行成功后,即可在左侧MaxCompute下显示新建的内部表,您可使用如下SQL语句在MaxCompute中查询该外部表的数据。
SET odps.namespace.schema=true; SELECT * FROM default.dwd_holo_orders;