本文为您介绍如何进行PyODPS的去重。
前提条件
请提前完成如下操作:
在DataWorks上完成业务流程创建,本例使用DataWorks简单模式。详情请参见创建业务流程。
操作步骤
创建表并导入数据。
下载鸢尾花数据集iris.data,重命名为iris.csv。
创建表pyodps_iris并上传数据集iris.csv。操作方法请参见建表并上传数据。
建表语句如下。
CREATE TABLE if not exists pyodps_iris ( sepallength DOUBLE comment '片长度(cm)', sepalwidth DOUBLE comment '片宽度(cm)', petallength DOUBLE comment '瓣长度(cm)', petalwidth DOUBLE comment '瓣宽度(cm)', name STRING comment '种类' );
- 登录DataWorks控制台。
在左侧导航栏上单击工作空间。
选择操作列中的。
在数据开发页面,右键单击已经创建的业务流程,选择。
在新建节点对话框,输入节点名称,并单击确认。
在PyODPS节点输入代码实现数据去重。
示例代码如下。
from odps.df import DataFrame iris = DataFrame(o.get_table('pyodps_iris')) print iris[['name']].distinct() print iris.distinct('name') print iris.distinct('name','sepallength').head(3) #您可以调用unique对Sequence进行去重操作,但是调用unique的Sequence不能用在列选择中 print iris.name.unique()单击运行。
在运行日志中查看运行结果。
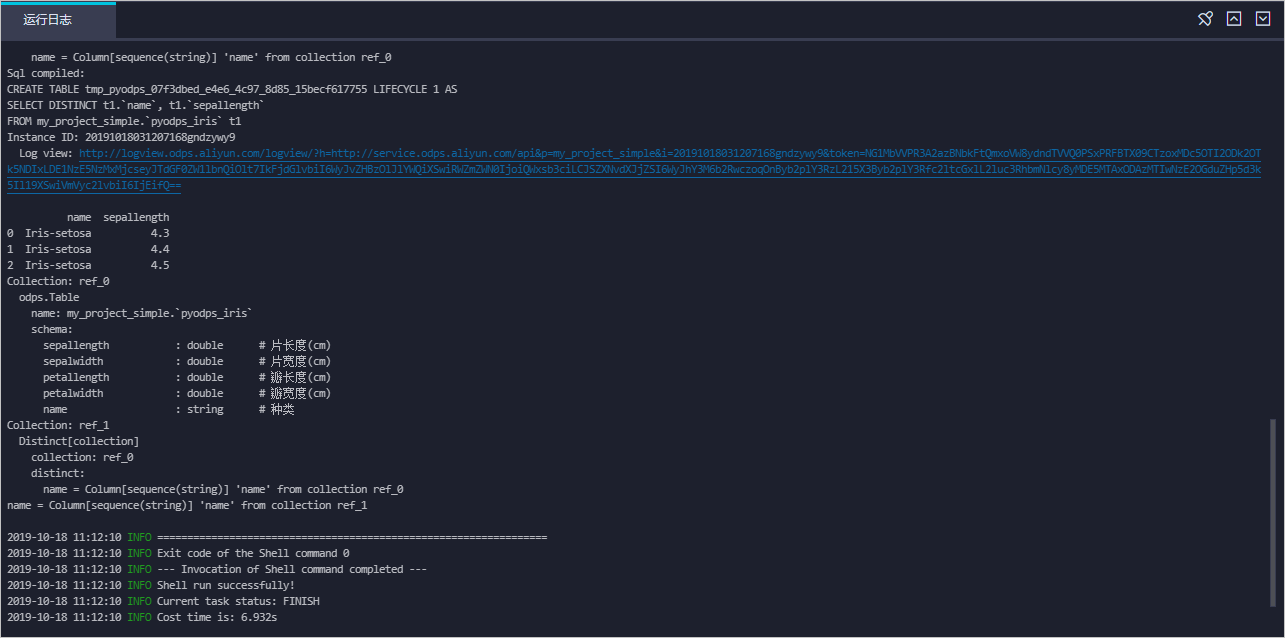
完整的运行结果如下。
Sql compiled: CREATE TABLE tmp_pyodps_ed85ebd5_d678_44dd_9ece_bff1822376f6 LIFECYCLE 1 AS SELECT DISTINCT t1.`name` FROM WB_BestPractice_dev.`pyodps_iris` t1 Instance ID: 2019101006391142g2cp5692 name 0 Iris-setosa 1 Iris-versicolor 2 Iris-virginica Sql compiled: CREATE TABLE tmp_pyodps_8ce6128f_9c6f_45af_b9de_c73ce9d5ba51 LIFECYCLE 1 AS SELECT DISTINCT t1.`name` FROM WB_BestPractice_dev.`pyodps_iris` t1 Instance ID: 20191010063915987gmuws592 name 0 Iris-setosa 1 Iris-versicolor 2 Iris-virginica Sql compiled: CREATE TABLE tmp_pyodps_a3dc338e_0fea_4d5f_847c_79fb19ec1c72 LIFECYCLE 1 AS SELECT DISTINCT t1.`name`, t1.`sepallength` FROM WB_BestPractice_dev.`pyodps_iris` t1 Instance ID: 2019101006392210gj056292 name sepallength 0 Iris-setosa 4.3 1 Iris-setosa 4.4 2 Iris-setosa 4.5 Sql compiled: CREATE TABLE tmp_pyodps_bc0917bb_f10c_426b_9b75_47e94478382a LIFECYCLE 1 AS SELECT t2.`name` FROM ( SELECT DISTINCT t1.`name` FROM WB_BestPractice_dev.`pyodps_iris` t1 ) t2 Instance ID: 20191010063927189g9fsz192 name 0 Iris-setosa 1 Iris-versicolor 2 Iris-virginica