您可以使用作业调试功能模拟作业运行、检查输出结果,验证SELECT或INSERT业务逻辑的正确性,提升开发效率,降低数据质量风险。本文为您介绍如何进行Flink SQL作业调试。
背景信息
您可以在Flink开发控制台使用作业调试功能本地验证作业逻辑的正确性,而不会将数据实际写入您生产的下游中(无论您使用什么样的结果表)。使用调试功能时,您可以使用上游的线上数据或指定调试数据。调试可以包含多个SELECT或INSERT的复杂作业。此外,查询语句支持UPSERT,即可以执行count(*)等包含更新操作的语句。
使用限制
作业调试功能需要已创建Session集群。
仅SQL作业支持作业调试。
CTAS和CDAS语法不支持调试。
Flink默认读取最多1000条数据后会自动暂停。
Session 集群调试不支持无限期运行,每次调试最长仅持续三分钟,以确保集群生命周期的可控性与稳定性。
注意事项
在创建Session集群时会消耗集群资源,其中消耗的资源和您创建集群时选择的资源配置有关。
请勿将Session集群用于正式生产环境,Session集群可以作为开发测试环境。使用Session集群调试作业,可以提高作业JM(Job Manager)资源利用率。在正式环境中使用Session集群,JM的复用机制会对作业间的稳定性产生负面影响,详情如下:
JobManager单点故障会对集群内的所有作业造成影响。
TaskManager单点故障会对在其上有task运行的相关作业造成影响。
同一个TaskManager内部,不同Task之间如果没有进程隔离,则存在相互影响的潜在风险。
如果Session集群为默认配置,则有以下建议:
对于单并发的小作业,建议整个集群的作业总数不超过100个。
对于复杂作业,建议单作业最大并发数不超过512,64个并发的中等规模作业单集群不多于32个。否则可能会出现心跳超时等问题影响集群稳定性。此时,您需要增大心跳间隔和心跳超时时间。
如果您需要同时运行更多的任务,则需要增加Session集群的资源配置。
操作步骤
步骤一:创建Session集群
进入Session集群管理页面。
登录实时计算控制台。
单击目标工作空间操作列下的控制台。
在左侧导航栏上,单击。
单击创建Session集群。
填写配置信息。
参数详情如下表所示。
模块
配置项
说明
基础配置
名称
Session集群名称。
部署目标
选择目标资源队列,资源队列创建详情请参见管理资源队列。
状态
设置当前集群的期望运行状态:
RUNNING:当集群配置完成后保持运行状态。
STOPPED:当集群配置完成后保持停止状态,同样会停止所有部署在该Session集群上运行的作业。
定时Session管理
为避免Session集群长时间运行造成资源的浪费,可以设定一定时间内无作业运行则自动关闭集群。
标签名
您可以在标签选项中添加作业标签,便于在总览页面快速定位作业。
标签值
无。
配置
引擎版本
引擎版本详情请参见引擎版本介绍和生命周期策略。建议您使用推荐版本或稳定版本,引擎版本标记含义详情如下:
推荐版本:当前最新大版本下的最新小版本。
稳定版本:还在产品服务期内的大版本下最新的小版本,已修复历史版本缺陷。
普通版本:还在产品服务期内的其他小版本。
EOS版本:超过产品服务期限的版本。
Flink重启策略配置
该参数取值如下:
Failure Rate:基于失败率重启。
选择该选项后,您还需要填写检测Failure Rate的时间间隔、时间间隔内的最大失败次数和每次重启时间间隔。
Fixed Delay:固定间隔重启。
选择该选项后,您还需要填写尝试重启的次数和每次重启时间间隔。
No Restarts:作业task失败不会重启。
重要如果您没有配置该参数,则按Apache Flink默认的重启策略,即当有Task失败时,如果没有开启Checkpoint,JobManager进程不会重启。如果开启了Checkpoint,则JobManager进程会重启。
其他配置
在此设置更多Flink配置。例如
taskmanager.numberOfTaskSlots: 1。资源配置
Task Managers数量
默认与并行度一致。
JobManager CPU Cores
默认值为1。
JobManager Memory
最小值为1 GiB,推荐值为4 GiB。单位建议使用GiB或MiB,例如,1024 MiB或1.5 GiB。
TaskManager CPU Cores
默认值为2。
TaskManager Memory
最小值为1 GiB,推荐值为8 GiB。单位建议使用GiB或MiB,例如,1024 MiB或1.5 GiB。
TaskManager推荐配置包含单个TaskManager的Slot个数(taskmanager.numberOfTaskSlots)及TaskManager资源大小。具体内容如下:
对于单并发小作业,建议单Slot的CPU内存比为1:4,使用的资源不小于1核2 GiB。
对复杂作业,建议单Slot使用资源不小于1核4 GiB。在默认资源配置下,每个TaskManager可以配置2个Slot。
TaskManager资源不宜过小,也不宜过大,推荐默认资源配置并将Slot数目设为2。
重要如果单个TaskManager资源过小,则可能影响其上作业的稳定性,并且由于其Slot数目不多,无法有效平摊TaskManager的开销,降低了资源的利用效率。
如果单个TaskManager资源过大,则TaskManager上运行的作业数会很多,一旦TaskManager发生单点故障,影响面会很大。
日志配置
根日志等级
日志级别从低到高的顺序如下:
TRACE:比DEBUG更细粒度的信息。
DEBUG:系统运行状态的信息。
INFO:重要或者您感兴趣的信息。
WARN:系统可能出现潜在错误的信息。
ERROR:系统出现错误和异常的信息。
类日志等级
填写日志名和级别。
日志模板
可以选择系统模板或自定义模板。
说明关于Flink与资源编排框架(例如Kubernetes、Yarn等)集成的相关选项详情,请参见Resource Orchestration Frameworks。
单击创建Session集群。
Session集群创建完成后,您可以在作业调试界面或部署界面选择此集群。
步骤二:作业调试
SQL作业开发,编写作业代码。详情请参见作业开发地图。
在ETL页面,单击调试,并选择调试集群,单击下一步。
配置调试数据。
如果您使用线上数据,直接单击确定即可。
如果您需要使用调试数据,需要先单击下载调试数据模板后,填写调试数据后,上传调试数据。
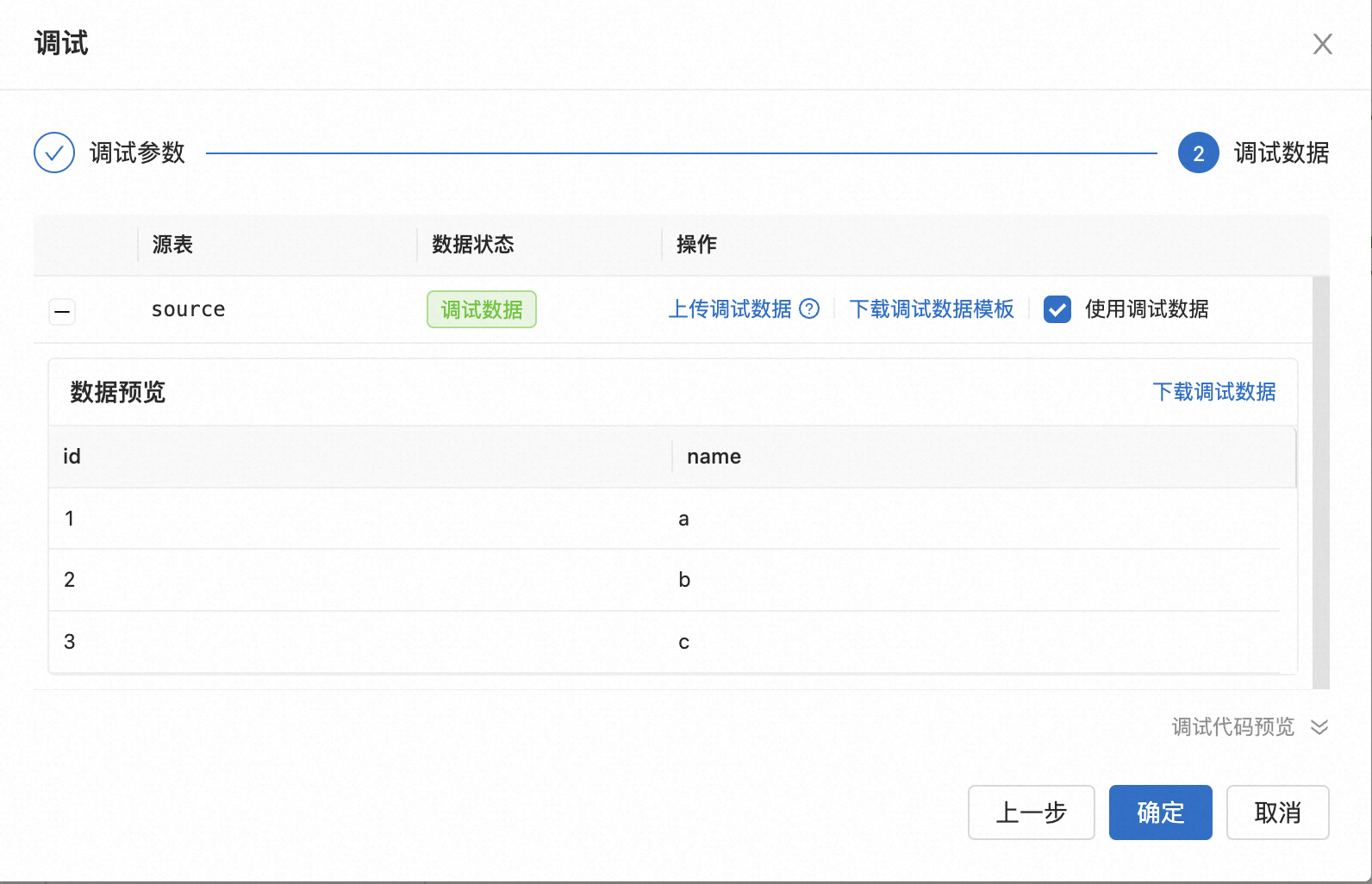
其中该页面涉及的功能解释如下。
配置项
说明
下载调试数据模板
为了便于编辑,您可以直接下载调试数据模板,模板已适配源表的数据结构。
上传调试数据
如果您需要使用本地调试数据进行调试,您可以先下载调试数据模板,在本地编辑好数据后上传,并选中使用调试数据。
调试数据文件存在以下限制:
上传文件仅支持CSV格式。
CSV格式的文件必须含有表头,例如 id(INT)。
调试数据CSV文件最大支持1 MB或1千条记录。
数据预览
上传好调试数据后,单击源表名称左侧的
 图标,可以预览数据和下载调试数据。
图标,可以预览数据和下载调试数据。调试代码预览
调试功能会自动改变源表和结果表的DDL代码,但不会改变作业中的实际代码。您可以在下方预览代码详情。
确定好调试数据后,单击确定。
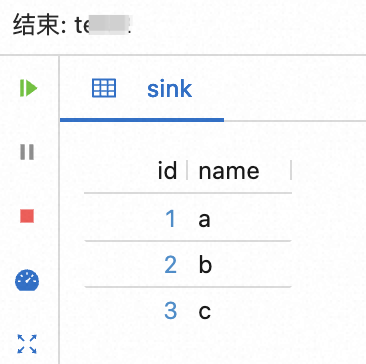
单击确定后,SQL编辑器下方会显示调试结果。
相关文档
作业开发或调试完成后,如果您需要将作业部署上线,请参见部署作业。
完成作业部署后,如果您需要将作业启动至运行阶段,请参见作业启动。
如果您需要了解Flink SQL作业的完整的操作流程示例,请参见Flink SQL作业快速入门。