CTAS支持实时同步数据及将上游表结构(Schema)变更同步至下游表,提升目标表创建与源表Schema变更的维护效率。本文为您介绍CTAS用法及实践场景。
建议使用数据摄入YAML作业完成数据摄入作业逻辑开发,已有的CTAS/CDAS SQL作业可以通过CTAS/CDAS作业生成功能一键转换为YAML作业。
功能:通过YAML作业的方式实现将数据从源端同步到目标端。
YAML作业优势:不仅覆盖CTAS和CDAS的关键能力(如整库同步、单表同步、分库分表同步、新增表同步、表结构变更和自定义计算列同步等),还支持表结构变更立即同步、原始Binlog同步、Where条件过滤、列裁剪等能力。
可以参考Flink CDC数据摄入最佳实践了解更多案例。
核心功能
数据同步
功能 | 详情 |
单表同步 | 支持实时同步源表的全量和增量数据到结果表中。(示例:单表同步) |
分库分表合并同步 | 支持使用正则表达式定义库名和表名,匹配数据源的多张分库分表,合并后同步到下游的一张表中。(示例:分库分表合并同步) 说明 正则匹配时,不支持使用^进行表开头的匹配。 |
自定义计算列同步 | 支持在源表中添加计算列,用于对特定列进行转换计算。计算列可使用系统或自定义函数,并允许指定其位置。新增列将作为结果表的物理列,实时同步计算结果。(示例:自定义计算列同步) |
多CTAS语句 |
|
表结构变更同步
通过CTAS语句,在实时同步数据的同时,还能将源表Schema的变更同步到结果表中。Schema变更包括初始的表创建以及未来的表变更。
支持同步的Schema变更
Schema变更
说明
添加可空列
自动在结果表Schema末尾添加对应的列并同步数据。新增的列会默认设置为可空列,变更前该列的数据自动设置为NULL值。
添加非空列
自动在结果表Schema末尾添加对应的列并同步数据。
删除可空列
不会直接在结果表中删除该列,而是将该列数据自动设置为NULL值。
重命名列
等同于添加新列并删除旧列,即在结果表Schema末尾添加重命名后的列,并将重命名前的列数据自动设置为NULL值。
说明例如,如果col_a被重命名为col_b,则会在结果表末尾添加col_b,并自动将col_a的数据填充为NULL值。
列类型变更
下游系统支持列类型变更:目前只有Paimon支持处理列类型变更。CTAS支持普通列的类型变更,例如,从INT类型变更到BIGINT类型。
此类变更依赖于下游Sink支持的列类型变更规则,请参考对应结果表文档获取其支持的列类型变更规则。
下游系统不支持列类型变更:目前只有Hologres支持宽容模式处理列类型变更,即CTAS作业启动时创建类型更加宽泛的下游表,通过下游Sink对列类型变更的兼容性实现列类型变更支持,具体可参见示例:宽容模式同步数据。
重要宽容模式应该在首次启动CTAS作业时开启,如果在首次启动时未开启宽容模式,需要删除下游表并且将作业无状态重启才能生效。
重要CTAS是对比前后两条数据的Schema差异,不会去识别具体的DDL类型。
删除了某列后重新添加该列,且期间无数据变化,那么CTAS会认为没有发生结构变更。
添加新列后且有数据变化时,CTAS才会感知到结构变更,然后同步结构变更到结果表。
不支持同步的Schema变更
不支持主键或索引等约束的变更。
不支持非空列的删除。
不支持从NOT NULL转为NULLABLE的变更。
重要如果遇到以上不支持的Schema变更,需要您手动删除下游结果表,重新启动CTAS作业,即重新创建结果表并重新同步历史数据。
启动流程
以通过CTAS同步MySQL数据至Hologres为例,具体流程如下所示。
流程图 | 启动流程 |
 | 当执行CTAS语句时,将会按照以下流程执行:
|
前提条件
执行CTAS语法前,确保工作空间中已注册目标端的Catalog。详情请参见数据管理。
使用限制
语法限制
不支持调试功能。
不支持与INSERT INTO语句在同一作业中混合使用。
不支持同步到StarRocks分区表。
不支持MiniBatch配置。
重要创建SQL作业前:请确保配置管理页面的作业默认配置页签中的其他配置处删除了MiniBatch配置。
创建SQL作业后:具体解决方案可参见报错:Currently does not support merge StreamExecMiniBatchAssigner type ExecNode in CTAS/CDAS syntax。
上下游存储兼容性
CTAS支持的上下游存储列表如下,您可以从下表的源表和结果表中各选一个进行组合。
连接器名称 | 源表 | 结果表 | 备注 |
√ | × |
| |
√ | × | 无。 | |
√ | × |
| |
× | √ | 无。 | |
× | √ | 仅支持EMR的StarRocks。 | |
× | √ | 如果下游是Hologres,CTAS在默认情况下会为每个表创建相应数量(connectionSize参数值)个连接。此时您就可以使用connectionPoolName参数,让配置相同名称连接池的表可以共享连接池。 说明 在将数据同步到Hologres时,如果您的上游源表包含了Fixed Plan不支持类型的数据,建议通过INSERT INTO语句的方式,在Flink内部做类型转换后将数据同步到Hologres。不要用CTAS方式创建Sink结果表进行数据同步,因为这种方式会无法走Fixed Plan,写入性能较差。 | |
× | √ | 仅实时计算引擎VVR 11.1及以上版本支持同步到Paimon DLF 2.5结果表。 |
基本语法
CREATE TABLE IF NOT EXISTS <sink_table>
(
[ <table_constraint> ]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (
key1=val1,
key2=val2,
...
)
AS TABLE <source_table> [/*+ OPTIONS(key1=val1, key2=val2, ... ) */]
[ADD COLUMN { <column_component> | (<column_component> [, ...])}];
<sink_table>:
[catalog_name.][db_name.]table_name
<table_constraint>:
[CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED
<source_table>:
[catalog_name.][db_name.]table_name
<column_component>:
column_name AS computed_column_expression [COMMENT column_comment] [FIRST | AFTER column_name]CTAS语法复用了CREATE TABLE语法的基本结构,其中的参数解释如下表所示。
参数 | 说明 |
| 数据同步的结果表名,可以指定具体的Catalog名称和数据库名称。 |
| 结果表的描述,默认使用source_table的描述。 |
| 系统支持根据某列进行分区,创建分区表。 重要 暂不支持同步到StarRocks分区表。 |
| 定义表主键约束,用于确保数据唯一性。 |
| 结果表参数,可填入结果表支持的WITH参数。支持的WITH参数详情请参见Upsert Kafka WITH参数、Hologres WITH参数、StarRocks WITH参数或Paimon WITH参数。 说明 key和value都需要为字符串类型,例如 |
| 数据同步的源表表名,可指定具体的Catalog名称和Database名称。 |
| 源表的参数,可填入源表支持的WITH参数。支持的WITH参数详情请参见MySQL WITH参数和Kafka WITH参数。 说明 key和value都需要为字符串类型,例如'server-id' = '65500'。 |
| 定义目标表相对于源表新增或重命名的字段,支持字段别名与计算列。 重要 纯字段映射(如 |
| 新增列的描述。 |
| 计算列表达式的描述。 |
| 新增列作为源表的第一个字段。如果不添加该参数,则新增列会默认作为源表的最后一个字段。 |
| 新增列放在源表指定字段后面。 |
IF NOT EXISTS关键字为必填,如果结果表在目标存储中并不存在,则会先创建该结果表,否则跳过创建步骤。
创建的结果表Schema会使用源表的Schema,包括主键以及物理字段的字段名和字段类型,不包括计算列、meta字段、Watermark。
源表到结果表的字段类型会经过类型映射,详情请参见对应连接器文档中的类型映射。
代码示例
单表同步
同步场景:将MySQL中的web_sales表同步到Hologres。
前提条件:已在工作空间注册以下Catalog。
Hologres Catalog:名称为holo。
MySQL Catalog:名称为mysql。
代码示例:
CTAS通常会配合数据源的Catalog和目标的Catalog一起使用,其中源Catalog可以自动解析源表的Schema及参数(无需手动编写DDL),最终完成源表到目标表的全量和增量数据同步。
USE CATALOG holo;
CREATE TABLE IF NOT EXISTS web_sales -- 没有指定数据库,则同步到默认数据库的web_sales表。
WITH ('jdbcWriteBatchSize' = '1024') -- 可选,指定结果表的参数。
AS TABLE mysql.tpcds.web_sales
/*+ OPTIONS('server-id'='8001-8004') */; -- 指定mysql-cdc源表的额外参数。分库分表合并同步
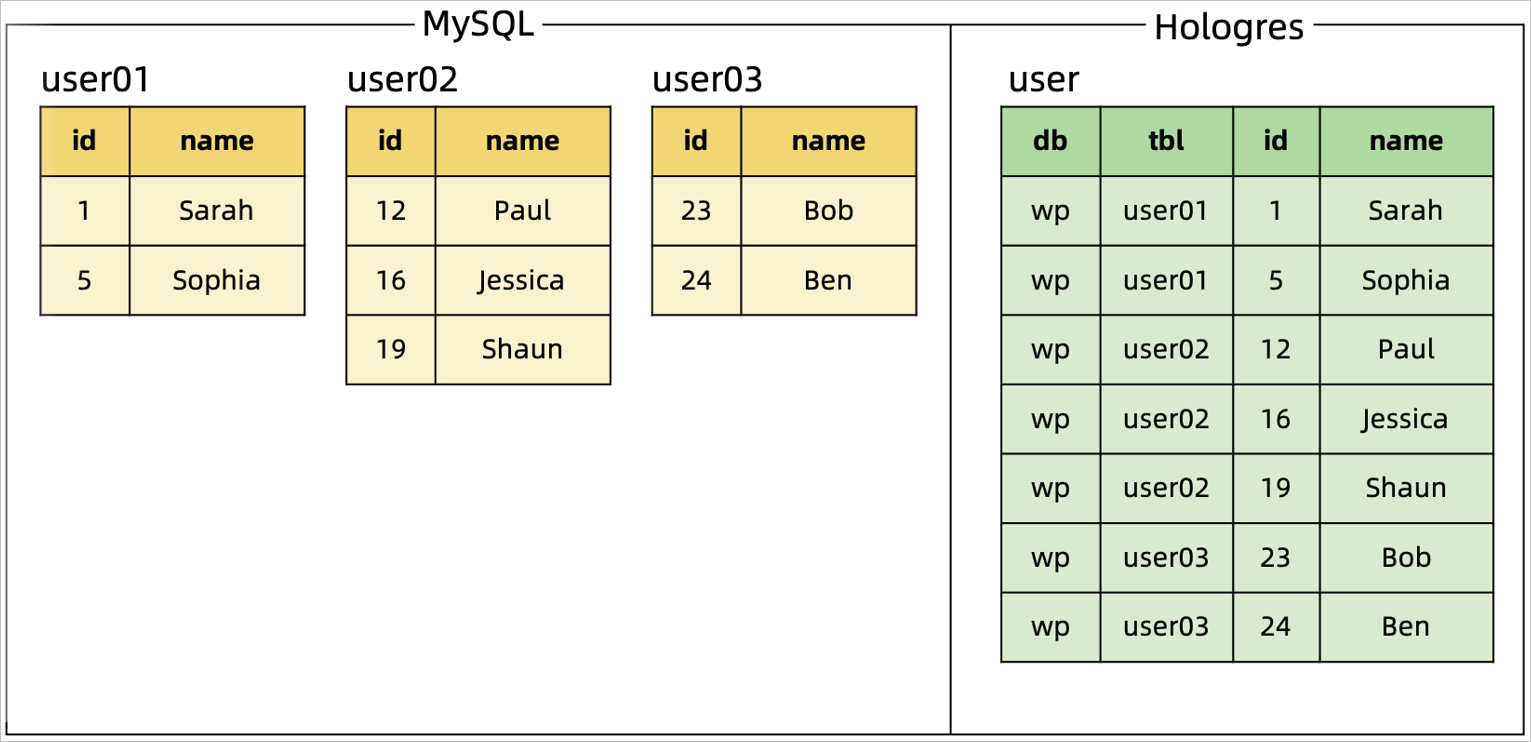
同步场景:使用CTAS将MySQL多张分库分表合并到一张Hologres表中。
同步方案:结合MySQL Catalog,利用正则表达式的库名和表名匹配要同步的多张表。其中库名和表名会作为额外的两个字段写入到结果表中,为保证主键唯一性,库名、表名和原主键会一起作为该Hologres表的新联合主键。
代码示例及合并效果:
代码示例 | 合并效果 |
分库分表合并同步场景: |
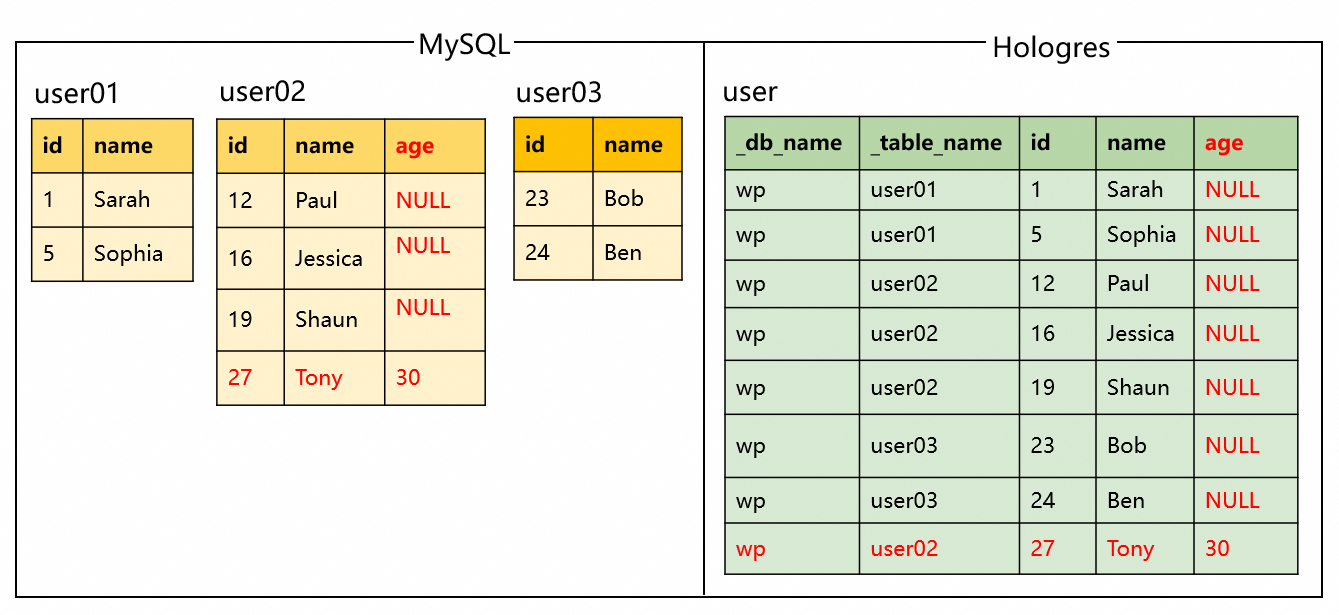
|
源表结构变更场景:在user02表中新增一列age,并插入一条数据。(虽然多张分表的Schema并不一致,但是user02表后续的数据和Schema变更都能实时地自动同步到下游表中。) |
|
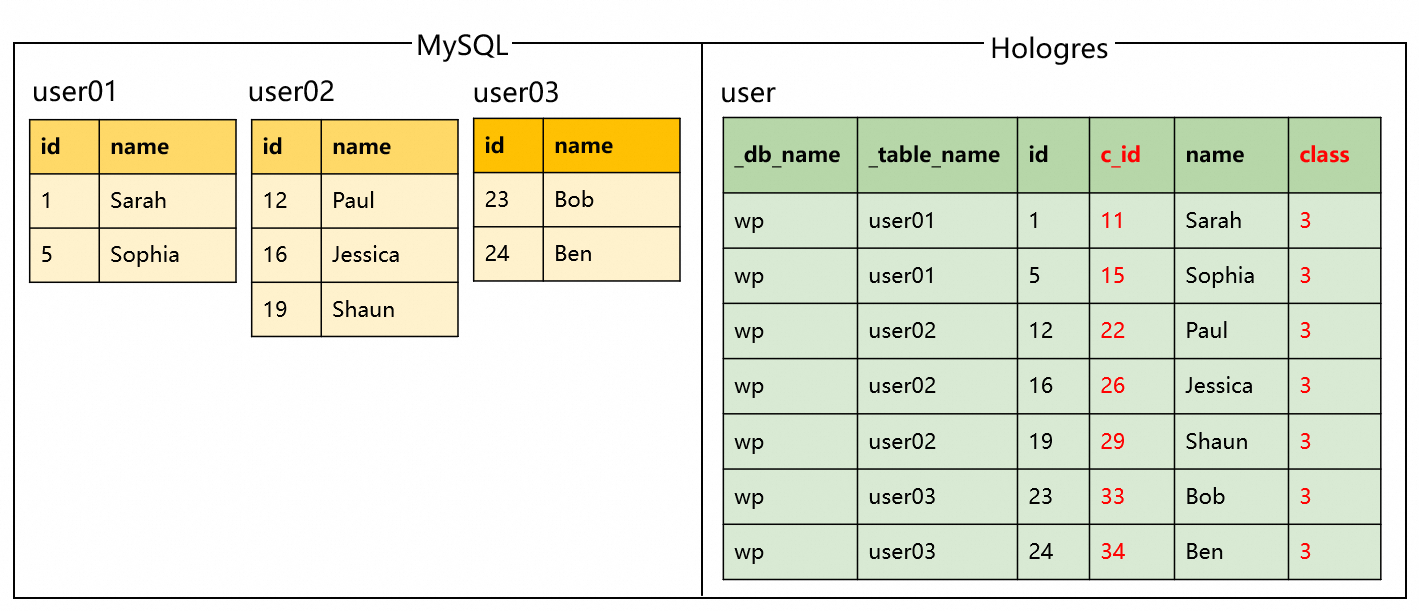
自定义计算列同步
同步场景:在MySQL分库分表合并过程中新增自定义计算列同步到Hologres表中。
代码示例及合并效果:
代码示例 | 合并效果 |
|
|
多CTAS语句:作为一个作业提交
同步场景:将MySQL中的web_sales表、user分库分表作为一个作业同步到Hologres。
同步方案:使用STATEMENT SET语法将多个CTAS语句作为一个作业提交。该方案可以复用一个Source节点读取多张业务表的数据,在MySQL CDC数据源场景可以减少server-id的使用及数据库的连接数与读取压力。
Source表的options完全一致才能合并成功达到Source复用优化的目的。
MySQL连接器中Server ID的设置,请参见设置Server ID,避免Binlog消费冲突。
代码示例:
USE CATALOG holo;
BEGIN STATEMENT SET;
-- 同步web_sales表。
CREATE TABLE IF NOT EXISTS web_sales
AS TABLE mysql.tpcds.web_sales
/*+ OPTIONS('server-id'='8001-8004') */;
-- 同步user分库分表。
CREATE TABLE IF NOT EXISTS user
AS TABLE mysql.`wp.*`.`user[0-9]+`
/*+ OPTIONS('server-id'='8001-8004') */;
END;多CTAS语句:同一源表同步到多结果表
结果表不添加计算列
USE CATALOG `holo`; BEGIN STATEMENT SET; -- 通过CTAS语句同步MySQL的user表到Holo数仓database1的user表中 CREATE TABLE IF NOT EXISTS `database1`.`user` AS TABLE `mysql`.`tpcds`.`user` /*+ OPTIONS('server-id'='8001-8004') */; -- 通过CTAS语句同步MySQL的user表到Holo数仓database2的user表中 CREATE TABLE IF NOT EXISTS `database2`.`user` AS TABLE `mysql`.`tpcds`.`user` /*+ OPTIONS('server-id'='8001-8004') */; END;结果表需要添加计算列
-- 基于源表user创建临时表user_with_changed_id,支持定义计算列,例如这里的computed_id是基于源表的id计算获得。 CREATE TEMPORARY TABLE `user_with_changed_id` ( `computed_id` AS `id` + 1000 ) LIKE `mysql`.`tpcds`.`user`; -- 基于源表user创建临时表user_with_changed_age,支持定义计算列,例如这里的computed_age是基于源表的age计算获得。 CREATE TEMPORARY TABLE `user_with_changed_age` ( `computed_age` AS `age` + 1 ) LIKE `mysql`.`tpcds`.`user`; BEGIN STATEMENT SET; -- 通过CTAS语句同步MySQL的user表到Holo数仓的user_with_changed_id表中,表中会包含通过计算获得的id,即computed_id列。 CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`user_with_changed_id` AS TABLE `user_with_changed_id` /*+ OPTIONS('server-id'='8001-8004') */; -- 通过CTAS语句同步MySQL的user表到Holo数仓的user_with_changed_age表中,表中会包含通过计算获得的age,即computed_age列。 CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`user_with_changed_age` AS TABLE `user_with_changed_age` /*+ OPTIONS('server-id'='8001-8004') */; END;
多CTAS语句:新增表同步
同步场景:多个CTAS语句的作业启动后,需要新增CTAS语句对新增表进行数据同步。
同步方案:在SQL作业中开启新增表读取功能,新增CTAS语句后从作业快照重启,捕获到新表后进行数据同步。
使用限制:
VVR 8.0.1及以上版本支持新增表功能。
使用CDC源表同步时,仅支持源表启动模式为initial的作业使用新增表功能。
新增CTAS语句中新增的源表配置要和原有的源表配置完全一致,确保Source能够复用。
新增CTAS语句前后,作业配置参数不能变更(例如更改启动模式等)。
操作步骤:
当需要新增CTAS语句时,在作业运维页面停止作业并勾选停止前创建一次快照。
在SQL作业中开启新增表读取功能并新增CTAS语句,然后重新部署作业。
在SQL作业中增加以下语句,开启新增表读取功能。
SET 'table.cdas.scan.newly-added-table.enabled' = 'true';在SQL作业中增加CTAS语句,最终完整的代码示例如下。
-- 开启新增表读取功能。 SET 'table.cdas.scan.newly-added-table.enabled' = 'true'; USE CATALOG holo; BEGIN STATEMENT SET; -- 同步web_sales表。 CREATE TABLE IF NOT EXISTS web_sales AS TABLE mysql.tpcds.web_sales /*+ OPTIONS('server-id'='8001-8004') */; -- 同步user分库分表。 CREATE TABLE IF NOT EXISTS user AS TABLE mysql.`wp.*`.`user[0-9]+` /*+ OPTIONS('server-id'='8001-8004') */; -- 同步product表。(新增表) CREATE TABLE IF NOT EXISTS product AS TABLE mysql.tpcds.product /*+ OPTIONS('server-id'='8001-8004') */; END;单击部署。
从快照恢复作业。
在作业运维页面单击目标作业名称,状态集管理页签,单击历史。
在作业快照列表中,找到停止作业时创建的快照。
单击目标快照操作列,选择完成作业启动。详情请参见作业启动。
同步到Hologres分区表
同步场景:通过CTAS语句将MySQL源表同步到Hologres分区表。
Hologres分区表规则:在Hologres中,如果目标表定义了主键,则分区字段必须包含在主键列中。
代码示例:
MySQL源表的建表语句如下:
CREATE TABLE orders (
order_id INTEGER NOT NULL,
product_id INTEGER NOT NULL,
city VARCHAR(100) NOT NULL
order_date DATE,
purchaser INTEGER,
PRIMARY KEY(order_id, product_id)
);需要根据源表的主键与分区字段的关系采取不同的处理方式。
源表主键包含分区字段:直接通过CTAS语句完成同步。
Hologres会自动验证分区字段是否为主键的一部分。
CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`orders` PARTITIONED BY (product_id) AS TABLE `mysql`.`tpcds`.`orders`;源表主键不包含分区字段:在CTAS语句中重新声明目标表的主键。
如果Hologres表的分区字段(如city)不在上游表主键中,则直接同步会导致作业失败。您需要在CTAS语句中重新声明目标表的主键,确保分区字段成为主键的一部分。
-- 可以通过如下SQL指定Hologres分区表的主键为order_id,product_id和city。 CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`orders`( CONSTRAINT `PK_order_id_city` PRIMARY KEY (`order_id`,`product_id`,`city`) NOT ENFORCED ) PARTITIONED BY (city) AS TABLE `mysql`.`tpcds`.`orders`;
宽容模式同步数据
同步场景:使用CTAS语句同步数据到Hologres表时,需要支持调整已有字段数据类型的精度(如从VARCHAR(10)修改为VARCHAR(20))或者修改数据类型(如从SMALLINT修改为INT)的场景。
同步方案:使用Hologres字段类型宽容模式同步数据。宽容模式应该在CTAS作业首次启动时开启,若未开启,需要删除下游表并且将作业无状态重启才能生效。
类型归一化规则:
上游数据类型修改后,若修改类型与原类型的归一化类型相同,则视为类型修改成功,CTAS作业正常运行。否则属于不兼容的情况,CTAS作业会抛出异常。具体规则如下:
TINYINT、SMALLINT、INT和BIGINT归一化为BIGINT。
CHAR、VARCHAR和STRING归一化为STRING。
FLOAT和DOUBLE归一化为DOUBLE。
其他数据类型按照原本的类型映射规则创建,详情参见类型映射。
代码示例:
CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`orders`
WITH (
'connector' = 'hologres',
'enableTypeNormalization' = 'true' -- 使用字段类型宽容模式。
) AS TABLE `mysql`.`tpcds`.`orders`;将MongoDB源表同步到Hologres表
使用限制:
实时计算Flink VVR版本要求8.0.6及以上,MongoDB数据库版本为6.0及以上。
在SQL Hints中需设置参数scan.incremental.snapshot.enabled和scan.full-changelog为true。
MongoDB数据库需要开启前像后像(Pre- and Post-images)记录功能,开启方法参见Document Preimages。
使用一个作业同步多个MongoDB集合时,需要满足以下要求:
每张表中MongoDB的配置必须完全相同,包括hosts、scheme、username、password、connectionOptions。
每张表的scan.startup.mode配置必须完全相同。
代码示例:
BEGIN STATEMENT SET;
CREATE TABLE IF NOT EXISTS `holo`.`database`.`table1`
AS TABLE `mongodb`.`database`.`collection1`
/*+ OPTIONS('scan.incremental.snapshot.enabled'='true','scan.full-changelog'='true') */;
CREATE TABLE IF NOT EXISTS `holo`.`database`.`table2`
AS TABLE `mongodb`.`database`.`collection2`
/*+ OPTIONS('scan.incremental.snapshot.enabled'='true','scan.full-changelog'='true') */;
END;常见问题
作业运行异常
作业性能问题
数据同步问题
相关文档
CTAS需要配合Catalog一起使用,通过Catalog为表提供持久化元数据管理能力,解决CTAS无法持久化表结构和跨作业访问的问题。常用的Catalog使用请参见:
CTAS和CDAS的使用及实践场景:
整库同步、分库合并或源库新增表同步:CREATE DATABASE AS(CDAS)语句。
将MySQL整库同步到Kafka(降低多个任务对MySQL数据库的压力):Flink CDC MySQL整库同步Kafka。
使用CTAS和CDAS实现数据同步的教程:数据库实时入仓快速入门、Hologres实时数仓搭建或Paimon+StarRocks流式湖仓构建。
通过YAML作业实现数据同步:
快速入门:Flink CDC数据摄入作业快速入门。
将CTAS作业转化为YAML作业:创建Flink CDC数据摄入作业。