PostgreSQL数据源为您提供读取和写入PostgreSQL双向通道的功能,方便您后续可以通过向导模式和脚本模式配置数据同步任务。本文为您介绍DataWorks的PostgreSQL数据同步能力支持情况。
支持的版本
目前仅支持配置PostgreSQL数据源为PostgreSQL10、11、12、13、14、15、16.4版本。您可以通过如下语句查看PostgreSQL数据库的版本。
SHOW SERVER_VERSION;使用限制
离线读写
支持读取视图表。
PostgreSQL数据源支持Password认证方式(支持SCRAM-SHA-256认证方式),如果PostgreSQL数据库端更改了密码和密码认证方式,则需要更新数据源配置,并且重新测试连通性和手动运行相关任务验证。
当PostgreSQL中表名称、字段名称是以数字开头,或者名称中包含大小写英文字母、中划线(-)时需要使用双引号("")进行转义,不进行转义会导致PostgreSQL插件读取或写入PostgreSQL数据失败。但是在PostgreSQL Reader和Writer插件中,双引号("")为JSON关键字,因此,您需要使用反斜线(\)再次对双引号("")进行转义。例如,表名称为
123Test,则转义后表名称为\"123Test\"。说明双引号("")中,前引号(")和后引号(")均需使用反斜线(\)进行转义。
向导模式不支持转义,您需要转换为脚本模式进行转义。
使用脚本模式进行转义的代码示例如下。
"parameter": { "datasource": "abc", "column": [ "id", "\"123Test\"", //添加转义符 ], "where": "", "splitPk": "id", "table": "public.wpw_test" },暂不支持基于唯一索引直接更新写入到Postgres数据源,建议先将数据写入临时表,再通过
RENAME操作来完成更新。
实时读
数据集成实时同步任务存在如下约束与限制:
数据集成对
ADD COLUMN进行了特别支持:约束:
ADD COLUMN时不能有ADD COLUMN和DROP COLUMN或者其他DDL的组合。重要ADD COLUMN时其他DROP COLUMN、RENAME COLUMN等ALTER COLUMN的行为将使数据同步任务不能正常工作。限制:除了
ADD COLUMN外,无法识别用户的其他DDL操作。
不支持
ALTER TABLE/CREATE TABLE。不支持TEMPORARY表、UNLOGGED表和Hyper表复制,PostgreSQL数据库没有提供机制来对这两种类型的表进行log解析订阅。
不支持Sequences复制(
serial/bigserial/identity)。不支持TRUNCATE操作。
不支持大对象复制(Bytea)。
不支持视图、物化视图、外部表复制。
支持的字段类型
支持大部分PostgreSQL类型,在离线读写时也存在部分类型未被支持的情况,请注意检查您的数据类型。
针对PostgreSQL的类型转换列表,如下所示。
类型分类 | PostgreSQL数据类型 |
整数类 | BIGINT、BIGSERIAL、INTEGER、SMALLINT和SERIAL |
浮点类 | DOUBLE PRECISION、MONEY、NUMERIC和REAL |
字符串类 | VARCHAR、CHAR、TEXT、BIT和INET |
日期时间类 | DATE、TIME和TIMESTAMP |
布尔型 | BOOL |
二进制类 | BYTEA |
除上述列举的字段类型外,其它类型均不支持。
PostgreSQL Reader中MONEY、INET和BIT需要您使用
a_inet::varchar类似的语法进行转换。
数据同步前准备
在DataWorks上进行数据同步前,您需要参考本文提前在PostgreSQL侧进行数据同步环境准备,以便在DataWorks上进行PostgreSQL数据同步任务配置与执行时服务正常。以下为您介绍PostgreSQL同步前的相关环境准备。
准备工作1:创建账号并配置账号权限
您需要规划一个数据库的登录账号用于后续执行操作,此账号需要拥有数据库的REPLICATION、 LOGIN权限。
实时同步只支持逻辑复制机制,逻辑复制使用发布和订阅模型,其中一个或多个订阅者订阅发布者节点上的一个或多个发布。订阅者从他们订阅的发布中提取数据。
表的逻辑复制通常从对发布者数据库上的数据进行快照并将其复制到订阅者开始。完成后,发布者上的更改会实时发送给订阅者。
创建账号。
操作详情请参见创建账号和数据库。
配置权限。
检查账号是否有
replication权限。select userepl from pg_user where usename='xxx'预期返回结果为True,返回False则表示无权限,您可以通过如下语句进行授权。
ALTER USER <user> REPLICATION;
准备工作2:检查是否支持备库
SELECT pg_is_in_recovery()
目前仅支持主库,预期返回结果为False,返回True时表示是备库,实时同步不支持备库,需修改数据源配置信息为主库的信息,请参见配置PostgreSQL数据源。
准备工作3:检查wal_level是否为logical
show wal_level
wal_level指定了wal_log的级别,预期返回结果为logical,否则不支持逻辑复制机制。
准备工作4:检查是否可以启动wal_sender进程
-- 查询 max_wal_senders
show max_wal_senders;
-- 查询 pg_stat_replication 数量
select count(*) from pg_stat_replication当max_wal_senders不为空,且max_wal_senders值大于pg_stat_replication数量时,则表示有空闲可用的wal_sender进程。PostgreSQL数据库会为同步数据程序启动wal_sender进程,以便给订阅者发送日志。
对于每一个需要同步的表,需要手动执行ALTER TABLE [tableName] REPLICA IDENTITY FULL语句进行授权,否则实时同步任务会报错。
PostgreSQL实时同步任务启动后,会在数据库中自动创建slot、publications,slot名称格式为:di_slot_ + 解决方案ID ,publication名称格式为:di_pub_ + 解决方案ID,当实时同步任务停止或下线后,需手动删除,否则可能会导致PostgreSQL WAL持续增长。
创建数据源
在进行数据同步任务开发时,您需要在DataWorks上创建一个对应的数据源,操作流程请参见数据源管理,详细的配置参数解释可在配置界面查看对应参数的文案提示。
如果您的PostgreSQL数据库开启了SSL认证,那么您在添加DataWorks的PostgreSQL数据源时也需要开启SSL认证,具体操作流程请参见附录二:PostgreSQL数据源增加SSL认证。
数据同步任务开发:PostgreSQL同步流程引导
数据同步任务的配置入口和通用配置流程可参见下文的配置指导。
单表离线同步任务配置指导
脚本模式配置的全量参数和脚本Demo请参见下文的附录一:脚本Demo与参数说明。
整库离线读、单表/整库全增量实时读等同步任务配置指导
操作流程请参见整库实时同步任务配置。
常见问题
主备同步数据恢复问题 。
主备同步问题指PostgreSQL使用主从灾备,备库从主库不间断恢复数据。由于主备数据同步存在一定的时间差,特别是在某些特定情况,例如网络延迟等问题,导致备库同步恢复的数据与主库有较大差别,从备库同步的数据不是一份当前时间的完整镜像。
一致性约束 。
PostgreSQL在数据存储划分中属于RDBMS系统,对外可以提供强一致性数据查询接口。例如,在一次同步任务启动运行过程中,当该库存在其他数据写入方写入数据时,由于数据库本身的快照特性,PostgreSQL Reader完全不会获取到写入的更新数据。
上述是在PostgreSQL Reader单线程模型下数据同步一致性的特性,PostgreSQL Reader可以根据您配置的信息使用并发数据抽取,因此不能严格保证数据一致性。
当PostgreSQL Reader根据splitPk进行数据切分后,会先后启动多个并发任务完成数据同步。多个并发任务相互之间不属于同一个读事务,同时多个并发任务存在时间间隔,因此这份数据并不是完整的、一致的数据快照信息。
针对多线程的一致性快照需求,目前在技术上无法实现,只能从工程角度解决。工程化的方式存在取舍,在此提供以下解决思路,您可以根据自身情况进行选择。
使用单线程同步,即不再进行数据切片。缺点是速度比较慢,但是能够很好地保证一致性。
关闭其它数据写入方,保证当前数据为静态数据,例如锁表、关闭备库同步等。缺点是可能影响在线业务。
数据库编码问题 。
PostgreSQL在服务器端仅支持EUC_CN和UTF-8两种简体中文编码,PostgreSQL Reader底层使用JDBC进行数据抽取,JDBC天然适配各类编码,并在底层进行了编码转换。因此PostgreSQL Reader不需您指定编码,可以自动获取编码并转码。
对于PostgreSQL底层写入编码和其设定的编码不一致的混乱情况,PostgreSQL Reader对此无法识别,也无法提供解决方案,导出结果有可能为乱码。
增量数据同步的方式。
PostgreSQL Reader使用JDBC SELECT语句完成数据抽取工作,因此可以使用
SELECT…WHERE…进行增量数据抽取,方式如下:数据库在线应用写入数据库时,填充modify字段为更改时间戳,包括新增、更新、删除(逻辑删除)。对于该类应用,PostgreSQL Reader只需要where条件后跟上一同步阶段时间戳即可。
对于新增流水型数据,PostgreSQL Reader在where条件后跟上一阶段最大自增ID即可。
对于业务上无字段区分新增、修改数据的情况,PostgreSQL Reader无法进行增量数据同步,只能同步全量数据。
SQL安全性 。
PostgreSQL Reader提供querySql语句交给您自己实现SELECT抽取语句,PostgreSQL Reader本身对querySql不进行任何安全性校验。
附录一:脚本Demo与参数说明
离线任务脚本配置方式
如果您配置离线任务时使用脚本模式的方式进行配置,您需要按照统一的脚本格式要求,在任务脚本中编写相应的参数,详情请参见脚本模式配置,以下为您介绍脚本模式下数据源的参数配置详情。
Reader脚本Demo
配置一个从PostgreSQL数据库同步抽取数据作业,使用脚本开发的详情请参见脚本模式配置。
{
"type":"job",
"version":"2.0",//版本号。
"steps":[
{
"stepType":"postgresql",//插件名。
"parameter":{
"datasource":"",//数据源。
"column":[//字段。
"col1",
"col2"
],
"where":"",//筛选条件。
"splitPk":"",//用splitPk代表的字段进行数据分片,数据同步会启动并发任务进行数据同步。
"table":""//表名。
},
"name":"Reader",
"category":"reader"
},
{
"stepType":"stream",
"parameter":{},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//错误记录数。
},
"speed":{
"throttle":true, //当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,表示限流。
"concurrent":1, //作业并发数。
"mbps":"12"//限流,此处1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}Reader脚本参数
参数 | 描述 | 是否必选 | 默认值 |
datasource | 数据源名称,脚本模式支持添加数据源,此配置项填写的内容必须与添加的数据源名称保持一致。 | 是 | 无 |
table | 选取的需要同步的表名称。 | 是 | 无 |
column | 所配置的表中需要同步的列名集合,使用JSON的数组描述字段信息 。默认使用所有列配置,例如[ * ]。
| 是 | 无 |
splitFactor | 切分因子,可以配置同步数据的切分份数,如果配置了多并发,会按照并发数 * splitFactor份来切分。例如,并发数=5,splitFactor=5,则会按照5*5=25份来切分,在5个并发线程上执行。 说明 建议取值范围:1~100,过大会导致内存溢出。 | 否 | 5 |
splitPk | PostgreSQL Reader进行数据抽取时,如果指定splitPk,表示您希望使用splitPk代表的字段进行数据分片,数据同步会启动并发任务,以提高数据同步的效能:
| 否 | 无 |
where | 筛选条件,PostgreSQL Reader根据指定的column、table和where条件拼接SQL,并根据该SQL进行数据抽取。例如在测试时,您可以使用where条件指定实际业务场景,通常会选择当天的数据进行同步,指定where条件为
| 否 | 无 |
querySql(高级模式,向导模式不提供) | 在部分业务场景中,where配置项不足以描述所筛选的条件,您可以通过该配置项来自定义筛选SQL。当配置该项后,数据同步系统会忽略tables、columns和splitPk配置项,直接使用该配置的内容筛选数据。例如需要进行多表JOIN后同步数据,使用 | 否 | 无 |
fetchSize | 该配置项定义了插件和数据库服务器端每次批量数据获取条数,该值决定了数据集成和服务器端的网络交互次数,能够较大地提升数据抽取性能。 说明 fetchSize值过大(>2048)可能造成数据同步进程OOM。 | 否 | 512 |
Writer脚本Demo
脚本配置示例如下,详情请参见上述参数说明。
{
"type":"job",
"version":"2.0",//版本号。
"steps":[
{
"stepType":"stream",
"parameter":{},
"name":"Reader",
"category":"reader"
},
{
"stepType":"postgresql",//插件名。
"parameter":{
"datasource":"",//数据源。
"column":[// 字段。
"col1",
"col2"
],
"table":"",//表名。
"preSql":[],//执行数据同步任务之前率先执行的SQL语句。
"postSql":[],//执行数据同步任务之后率先执行的SQL语句。
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//错误记录数
},
"speed":{
"throttle":true,//当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,表示限流。
"concurrent":1, //作业并发数。
"mbps":"12"//限流,此处1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}Writer脚本参数
参数 | 描述 | 是否必选 | 默认值 |
datasource | 数据源名称,脚本模式支持添加数据源,该配置项填写的内容必须要与添加的数据源名称保持一致。 | 是 | 无 |
table | 选取的需要同步的表名称。 | 是 | 无 |
writeMode | 选择导入模式,目前支持insert和copy两种方式:
| 否 | insert |
column | 目标表需要写入数据的字段,字段之间用英文逗号分隔。例如 | 是 | 无 |
preSql | 执行数据同步任务之前,需率先执行的SQL语句。目前向导模式仅允许执行一条SQL语句,脚本模式可以支持多条SQL语句,例如清除旧数据。 | 否 | 无 |
postSql | 执行数据同步任务之后执行的SQL语句。目前向导模式仅允许执行一条SQL语句,脚本模式可以支持多条SQL语句,例如加上某个时间戳。 | 否 | 无 |
batchSize | 一次性批量提交的记录数大小,该值可以极大减少数据集成与PostgreSQL的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成数据集成运行进程OOM情况。 | 否 | 1,024 |
pgType | PostgreSQL特有类型的转化配置,支持bigint[]、double[]、text[]、Jsonb和JSON类型。配置示例如下。 | 否 | 无 |
附录二:PostgreSQL数据源增加SSL认证
PostgreSQL SSL认证文件说明
在DataWorks上创建或修改PostgreSQL数据源连接方式,支持配置SSL认证方式,SSL认证相关的配置项说明,具体如下。
PostgreSQL数据库 | DataWorks的PostgreSQL数据源配置 | |||
SSL链路加密 | 客户端加密 | 配置ACL | 配置项 | 说明 |
开启 | 不启用 | 不涉及 | Truststore证书文件 | 可选,客户端使用该证书来认证服务器。
|
启用 | 配置ACL为prefer |
| Keystore证书文件和私钥文件均可选,配置ACL为prefer表示服务端不强制校验客户端。
| |
配置ACL为verify-ca |
| |||
ACL配置设置为prefer时,不会强制校验客户端内容。
如果SSL认证时不配置任何文件,走普通链路。
如果SSL认证时添加了认证文件,可参考以上表格中相应描述。
ACL配置设置为verify-ca时,保证Keystore证书文件、私钥文件以及私钥密码三个配置项配置,即可创建数据源。
获取PostgreSQL SSL认证文件
本文将以RDS PostgreSQL实例为例生成SSL认证证书。
Truststore证书文件获取方式。
Truststore 证书文件获取的具体信息可以参考使用云端证书快速开启SSL加密。
进入RDS实例列表,单击查看对应区域的RDS实例,并点击目标实例ID,进入实例信息页面。
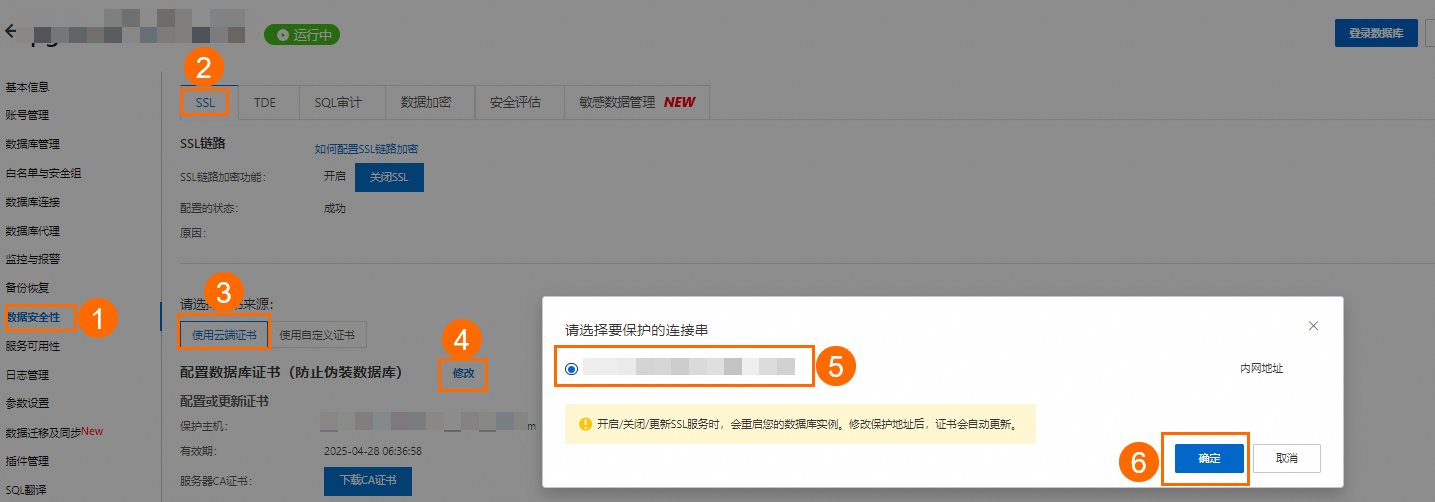
选择需要保护的连接串,具体操作如下图所示:
 说明
说明如果已开启外网地址,系统将同时显示内网和外网两个连接地址。云端证书只能对一个连接地址进行保护,而内网连接地址相对更安全,推荐您对外网连接地址进行保护。查看内网和外网地址的具体方法。请参考查看内外网地址。
如果您需要同时对内网和外网连接地址进行保护,可以参考使用自定义证书开启SSL加密。
配置云端证书后,实例的运行状态将会变成修改SSL中,该状态持续三分钟左右,请耐心等待运行状态变更为运行中后再进行后续操作。
c. 单击下载CA证书,即可获取到Truststore证书文件。
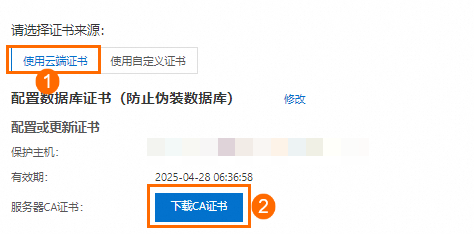
下载的CA证书包含3个文件,在DataWorks配置PostgreSQL数据源时,将后缀为
.pem的文件或后缀为.p7b文件上传到Truststore 证书文件配置项中。Keystore证书文件、私钥文件、私钥密码的获取与配置。
前提条件:已完成使用云端证书快速开启SSL加密或使用自定义证书开启SSL加密以及拥有OpenSSL工具。
说明如果您使用的是Linux系统,则系统已自带OpenSSL工具,无需进行安装。如果您使用Windows系统,请获取OpenSSL软件包并安装。
Keystore证书文件、私钥文件、私钥密码获取与配置的具体信息可以参考配置客户端CA证书。
在Linux系统上的OpenSSL工具或在Windows系统上安装OpenSSL软件,生成自签名证书(ca1.crt)和自签名证书密钥(ca1.key)。
openssl req -new -x509 -days 3650 -nodes -out ca1.crt -keyout ca1.key -subj "/CN=root-ca1"生成客户端证书请求文件(client.csr)和客户端证书私钥(client.key)。
openssl req -new -nodes -text -out client.csr -keyout client.key -subj "/CN=<客户端用户名>"该命令中
-subj参数后的CN取值请配置为客户端访问数据库的用户名。生成客户端证书(client.crt)。
openssl x509 -req -in client.csr -text -days 365 -CA ca1.crt -CAkey ca1.key -CAcreateserial -out client.crt如果您的RDS PostgreSQL服务器需要验证客户端CA证书,那么您需要打开生成的客户端自签名证书ca1.crt文件,复制证书内容粘贴在请填写客户端证书授权机构公钥内容对话框内,作为客户端CA证书。
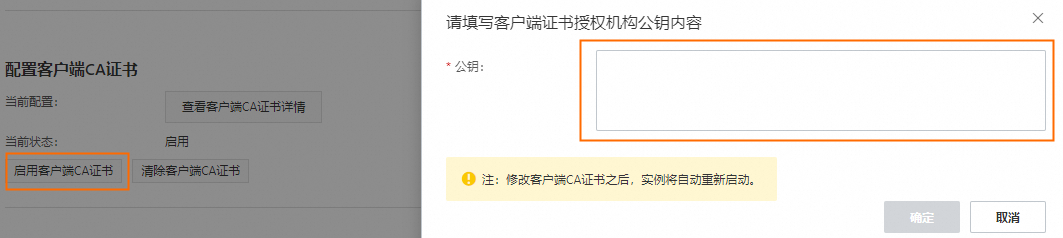
在RDS侧配置好客户端CA证书后,在DataWorks上配置PostgreSQL数据源时,需要将客户端证书私钥client.key转换为client.pk8文件,并将client.pk8上传至DataWorks的PostgreSQL数据源配置的私钥文件配置项中。
cp client.key client.pk8配置私钥密码。
openssl pkcs8 -topk8 -inform PEM -in client.key -outform der -out client.pk8 -v1 PBE-MD5-DES说明在执行配置私钥密码命令时,必须输入密码。如果您设置了密码,则在DataWorks的PostgreSQL数据源配置中的私钥密码也需要使用相同的密码。
配置 PostgreSQL SSL 认证文件
在将获取到的证书文件上传到DataWorks的PostgreSQL配置项时,其对应操作如下:
Truststore 证书文件:上传Truststore证书文件获取步骤获取到的后缀为
.pem的文件或后缀为.p7b文件。Keystore 证书文件:上传生成客户端证书步骤获取到的客户端证书文件client.crt。
私钥文件:上传转换私钥文件步骤获取到的客户端证书私钥文件转换成的client.pk8文件。
私钥密码:指的是配置私钥密码步骤配置的密码。

配置ACL:进入RDS实例列表,单击查看对应区域的RDS实例,并点击目标实例ID,进入实例信息页面后,点击进行修改,您可以选择不同SSL认证方法,可参考强制客户端开启SSL连接。
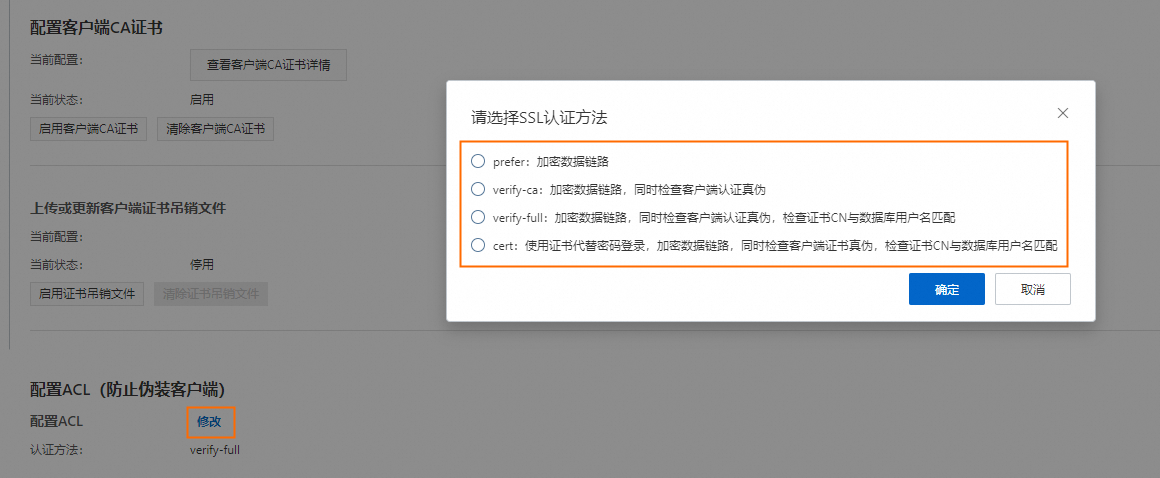
若ACL认证方法为prefer,则PostgreSQL服务器不会对客户端证书进行强制校验。
若在RDS PostgreSQL中配置了ACL认证方法为verify-ca,则在配置DataWorks的PostgreSQL数据源时,需要上传正确的客户端证书,保证服务器能够检查客户端认证真伪。