本文以ECS连接EMR Serverless Spark为例,介绍如何通过EMR Serverless spark-submit命令行工具进行Spark任务开发。
前提条件
已安装Java 1.8或以上版本。
如果使用RAM用户(子账号)提交Spark任务,需要将RAM用户(子账号)添加至Serverless Spark的工作空间中,并授予开发者或开发者以上的角色权限,操作请参见管理用户和角色。
操作流程
步骤一:下载并安装EMR Serverless spark-submit工具
将安装包上传至ECS实例,详情请参见上传或下载文件。
执行以下命令,解压并安装EMR Serverless spark-submit工具。
unzip emr-serverless-spark-tool-0.11.3-SNAPSHOT-bin.zip
步骤二:配置相关参数
在已安装Spark的环境中,如果系统中设置了SPARK_CONF_DIR 环境变量,则需将配置文件放置在SPARK_CONF_DIR所指定的目录下。例如,在EMR集群中,该目录通常为/etc/taihao-apps/spark-conf。否则,系统会报错。
执行以下命令,修改
connection.properties中的配置。vim emr-serverless-spark-tool-0.11.3-SNAPSHOT/conf/connection.properties推荐按照如下内容对文件进行配置,参数格式为
key=value,示例如下。accessKeyId=<ALIBABA_CLOUD_ACCESS_KEY_ID> accessKeySecret=<ALIBABA_CLOUD_ACCESS_KEY_SECRET> regionId=cn-hangzhou endpoint=emr-serverless-spark.cn-hangzhou.aliyuncs.com workspaceId=w-xxxxxxxxxxxx涉及参数说明如下表所示。
参数
是否必填
说明
accessKeyId
是
执行Spark任务使用的阿里云账号或RAM用户的AccessKey ID和AccessKey Secret。
重要在配置
accessKeyId和accessKeySecret参数时,请确保所使用的AccessKey所对应的用户具有对工作空间绑定的OSS Bucket的读写权限。工作空间绑定的OSS Bucket,您可以在Spark页面,单击工作空间操作列的详情进行查看。accessKeySecret
是
regionId
是
地域ID。本文以杭州地域为例。
endpoint
是
EMR Serverless Spark的Endpoint。地址详情参见服务接入点。
本文以杭州地域公网访问地址为例,参数值为
emr-serverless-spark.cn-hangzhou.aliyuncs.com。说明如果ECS实例没有公网访问能力,需要使用VPC地址。
workspaceId
是
EMR Serverless Spark工作空间ID。
步骤三:提交Spark任务
执行以下命令,进入EMR Serverless spark-submit工具目录。
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT请根据任务类型选择提交方式。
在提交任务时,需要指定任务依赖的文件资源(如JAR包或Python脚本)。这些文件资源可以存储在OSS上,也可以存储在本地,具体选择取决于您的使用场景和需求。本文均以OSS资源为例。
使用spark-submit方式
spark-submit是Spark提供的通用任务提交工具,适用于Java/Scala和PySpark类型的任务。Java/Scala类型任务
本文示例使用的spark-examples_2.12-3.5.2.jar,您可以单击spark-examples_2.12-3.5.2.jar,直接下载测试JAR包,然后上传JAR包至OSS。该JAR包是Spark自带的一个简单示例,用于计算圆周率π的值。
说明spark-examples_2.12-3.5.2.jar必须与esr-4.x引擎版本结合使用以提交任务。如果您使用esr-5.x引擎版本提交任务,请下载spark-examples_2.13-4.0.1.jar以便进行本文的验证。
./bin/spark-submit --name SparkPi \ --queue dev_queue \ --num-executors 5 \ --driver-memory 1g \ --executor-cores 2 \ --executor-memory 2g \ --class org.apache.spark.examples.SparkPi \ oss://<yourBucket>/path/to/spark-examples_2.12-3.5.2.jar \ 10000PySpark类型任务
本文示例使用的DataFrame.py和employee.csv,您可以单击DataFrame.py和employee.csv,直接下载测试文件,然后上传测试文件至OSS。
说明DataFrame.py文件是一段使用Apache Spark框架进行OSS上数据处理的代码。
employee.csv文件中定义了一个包含员工姓名、部门和薪水的数据列表。
./bin/spark-submit --name PySpark \ --queue dev_queue \ --num-executors 5 \ --driver-memory 1g \ --executor-cores 2 \ --executor-memory 2g \ --conf spark.tags.key=value \ oss://<yourBucket>/path/to/DataFrame.py \ oss://<yourBucket>/path/to/employee.csv相关参数说明如下:
兼容的开源参数
参数名称
示例值
说明
--name
SparkPi
指定Spark任务的应用名称,用于标识任务。
--class
org.apache.spark.examples.SparkPi
指定Spark任务的入口类名(Java或者Scala程序),Python程序无需此参数。
--num-executors
5
Spark任务的Executor数量。
--driver-cores
1
Spark任务的Driver核心数。
--driver-memory
1g
Spark任务的Driver内存大小。
--executor-cores
2
Spark任务的Executor核心数。
--executor-memory
2g
Spark任务的Executor内存大小。
--files
oss://<yourBucket>/file1,oss://<yourBucket>/file2
Spark任务需要引用的资源文件,可以是OSS资源,也可以是本地文件,多个文件使用逗号(,)分隔。
--py-files
oss://<yourBucket>/file1.py,oss://<yourBucket>/file2.py
Spark任务需要引用的Python脚本,可以是OSS资源,也可以是本地文件,多个文件使用逗号(,)分隔。该参数仅对PySpark程序生效。
--jars
oss://<yourBucket>/file1.jar,oss://<yourBucket>/file2.jar
Spark任务需要引用的JAR包资源,可以是OSS资源,也可以是本地文件,多个文件使用逗号(,)分隔。
--archives
oss://<yourBucket>/archive.tar.gz#env,oss://<yourBucket>/archive2.zip
Spark任务需要引用的archive包资源,可以是OSS资源,也可以是本地文件,多个文件使用逗号(,)分隔。
--queue
root_queue
Spark任务运行的队列名称,需与EMR Serverless Spark工作空间队列管理中的队列名称保持一致。
--proxy-user
test
设置的值将覆盖
HADOOP_USER_NAME环境变量,其行为与开源版本一致。--conf
spark.tags.key=value
Spark任务自定义参数。
--status
jr-8598aa9f459d****
查看Spark任务状态。
--kill
jr-8598aa9f459d****
终止Spark任务。
非开源增强参数
参数名称
示例值
说明
--detach
无需填充
使用此参数,spark-submit将在提交任务后立即退出,不再等待或查询任务状态。
--detail
jr-8598aa9f459d****
查看Spark任务详情。
--release-version
esr-4.1.1 (Spark 3.5.2, Scala 2.12)
指定Spark版本,请根据控制台展示的引擎版本号填写。
--enable-template
无需填充
启用模板功能,任务将使用工作空间的默认配置模板。
如果您在配置管理中创建了配置模板,可以通过在
--conf中指定spark.emr.serverless.templateId参数来指定模板ID,任务将直接应用指定的模板ID。有关创建模板的更多信息,请参见配置管理。仅指定
--enable-template,任务将自动应用工作空间的默认配置模板。仅通过
--conf指定模板ID:任务将直接应用指定的模板ID。同时指定
--enable-template和--conf:如果同时指定了--enable-template和--conf spark.emr.serverless.templateId,则--conf中的模板ID会覆盖默认模板。未指定任何参数:如果既未使用
--enable-template,也未指定--conf spark.emr.serverless.templateId,任务将不会应用任何模板配置。
--timeout
60
任务超时时间,单位为秒。
--workspace-id
w-4b4d7925a797****
任务级别指定工作空间ID,可以覆盖
connection.properties文件中的workspaceId参数。不支持的开源参数
--deploy-mode
--master
--repositories
--keytab
--principal
--total-executor-cores
--driver-library-path
--driver-class-path
--supervise
--verbose
使用spark-sql方式
spark-sql是专门用于运行SQL查询或脚本的工具,适用于直接执行SQL的场景。示例1:直接运行SQL语句
spark-sql -e "SHOW TABLES"该命令可以列出当前数据库中的所有表。
示例 2:运行SQL脚本文件
spark-sql -f oss://<yourBucketname>/path/to/your/example.sql本文示例使用的example.sql,您可以单击example.sql,直接下载测试文件,然后上传测试文件至OSS。
相关参数说明如下表所示。
参数名称
示例值
说明
-e "<sql>"-e "SELECT * FROM table"直接在命令行中内联执行SQL语句。
-f <path>-f oss://path/script.sql执行指定路径的SQL脚本文件。
步骤四:查询Spark任务
CLI方式
查询Spark任务状态
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT
./bin/spark-submit --status <jr-8598aa9f459d****>查询Spark任务详情
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT
./bin/spark-submit --detail <jr-8598aa9f459d****>UI方式
在EMR Serverless Spark页面,单击左侧导航栏中的任务历史。
在任务历史的开发任务页签,您可以查看提交的任务。
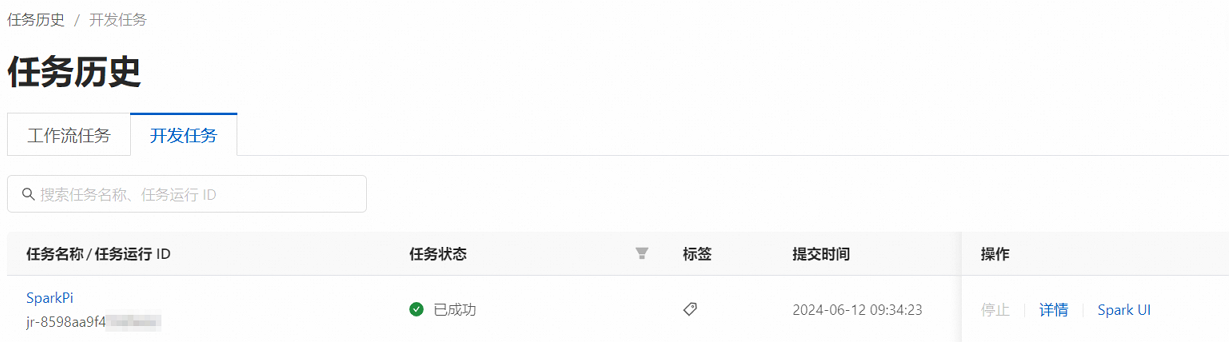
(可选)步骤五:终止Spark任务
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT
./bin/spark-submit --kill <jr-8598aa9f459d****>仅能终止处于运行状态(running)的任务。
常见问题
使用Spark-Submit工具提交批任务时,如何指定网络连接?
先准备网络连接,详情见新增网络连接。
在spark-submit命令中通过
--conf指定网络连接。--conf spark.emr.serverless.network.service.name=<networkname><networkname>替换为您的实际连接名称即可。