日志服务支持采集Nginx日志,并进行多维度分析。本文介绍分析网站访问情况、诊断及调优网站和重要场景告警的分析案例。
前提条件
已采集Nginx访问日志,详情请参见使用Nginx配置模式采集文本日志。
在日志采集配置向导中,已根据日志字段自动生成索引,如果您要修改索引,详情请参见创建索引。
背景信息
Nginx是一款主流的网站服务器,当您选用Nginx搭建网站时,Nginx日志是运维网站的重要信息。传统模式下,需使用CNZZ等方式,在前端页面插入JS,记录访问请求。或者利用流计算、离线计算分析Nginx访问日志,此方式还需要搭建环境,在实时性以及分析灵活性上难以平衡。
日志服务支持通过数据接入向导一站式采集Nginx日志,并为Nginx日志创建索引和仪表盘。nginx_Nginx访问日志仪表盘包括来源IP分布、请求状态占比、请求方法占比、访问PV/UV统计、流入流出流量统计、请求UA占比、前十访问来源、访问前十地址和请求时间前十地址等信息,全方位展示网站访问情况。您还可以使用日志服务的查询分析语句,分析网站的延时情况,及时调优网站。针对性能问题、服务器错误、流量变化等重要场景,您还可以设置告警,当满足告警条件时给您发送告警信息。
分析网站访问情况
登录日志服务控制台。
在Project列表区域,单击目标Project。

在中,单击目标LogStore左侧的>。
在可视化仪表盘中,单击nginx_Nginx访问日志。
nginx_Nginx访问日志仪表盘中的重要图表说明如下所示:
来源IP分布图展示最近一天访问IP地址的来源情况,所关联的查询分析语句如下所示:
* | select count(1) as c, ip_to_province(remote_addr) as address group by address limit 100请求状态占比图展示最近一天各HTTP状态码的占比情况,所关联的查询分析语句如下所示:
* | select count(1) as pv, status group by status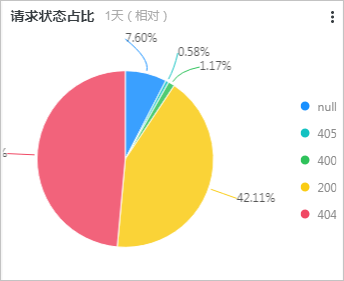
请求方法占比图展示最近一天各请求方法的占比情况,所关联的查询分析语句如下所示:
* | select count(1) as pv ,request_method group by request_method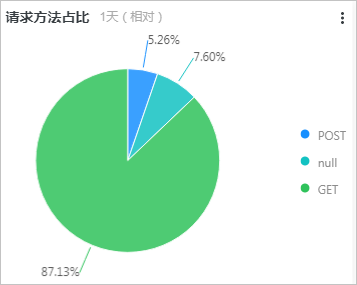
请求UA占比图展示最近一天各种浏览器的占比情况,所关联的查询分析语句如下所示:
* | select count(1) as pv, case when http_user_agent like '%Chrome%' then 'Chrome' when http_user_agent like '%Firefox%' then 'Firefox' when http_user_agent like '%Safari%' then 'Safari' else 'unKnown' end as http_user_agent group by case when http_user_agent like '%Chrome%' then 'Chrome' when http_user_agent like '%Firefox%' then 'Firefox' when http_user_agent like '%Safari%' then 'Safari' else 'unKnown' end order by pv desc limit 10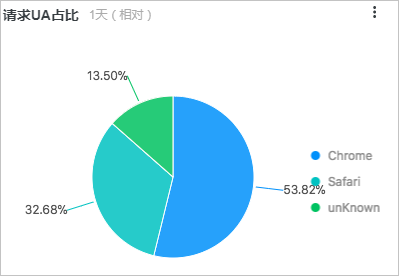
前十访问来源图展示最近一天PV数最多的前十个访问来源页面,所关联的查询分析语句如下所示:
* | select count(1) as pv , http_referer group by http_referer order by pv desc limit 10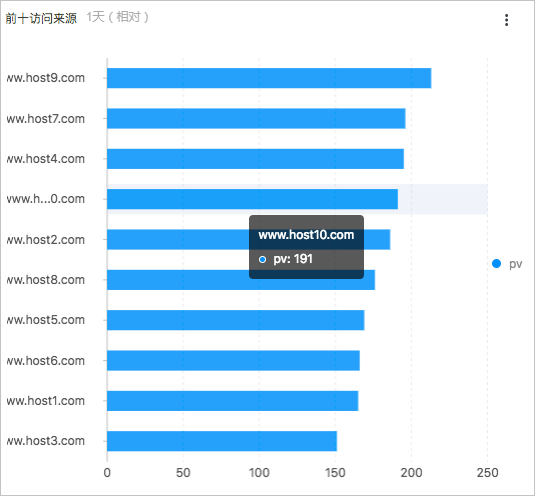
流入流出流量统计图展示最近一天流量的流入和流出情况,所关联的查询分析语句如下所示:
* | select sum(body_bytes_sent) as net_out, sum(request_length) as net_in ,date_format(date_trunc('hour', __time__), '%m-%d %H:%i') as time group by date_format(date_trunc('hour', __time__), '%m-%d %H:%i') order by time limit 10000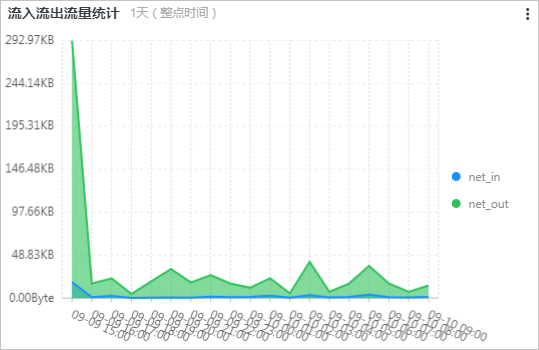
访问PV/UV统计图展示最近一天内的PV数和UV数,所关联的查询分析语句如下所示:
*| select approx_distinct(remote_addr) as uv ,count(1) as pv , date_format(date_trunc('hour', __time__), '%m-%d %H:%i') as time group by date_format(date_trunc('hour', __time__), '%m-%d %H:%i') order by time limit 1000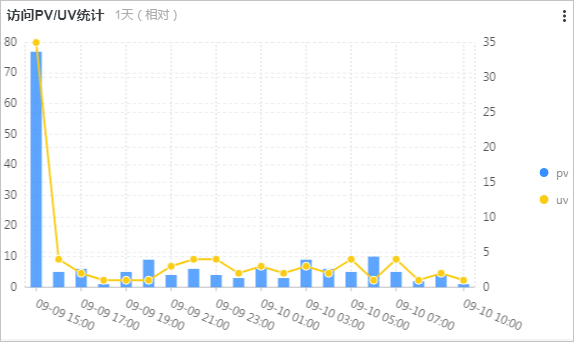
PV预测图预测未来4小时的PV数,所关联的查询分析语句如下所示:
* | select ts_predicate_simple(stamp, value, 6, 1, 'sum') from (select __time__ - __time__ % 60 as stamp, COUNT(1) as value from log GROUP BY stamp order by stamp) LIMIT 1000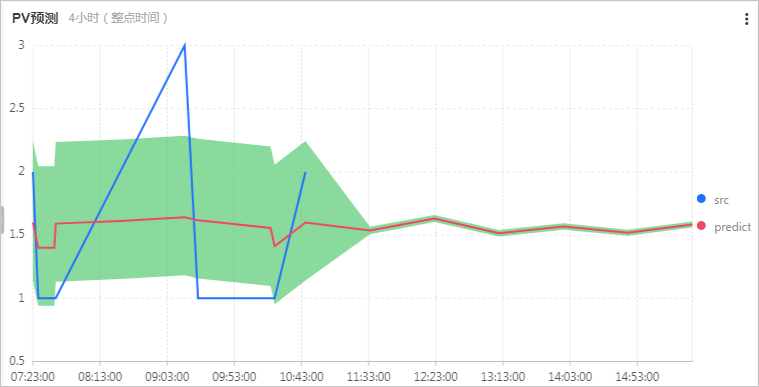
访问前十地址图展示最近一天PV数最多的前十个访问地址,所关联的查询分析语句如下所示:
* | select count(1) as pv, split_part(request_uri,'?',1) as path group by path order by pv desc limit 10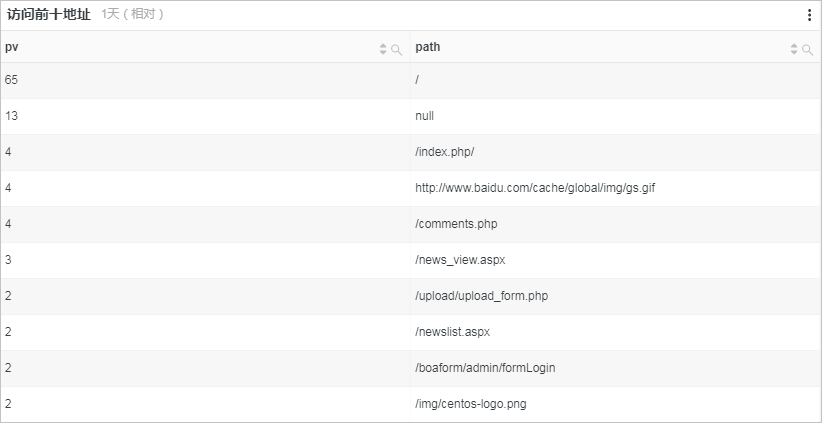
诊断及调优网站
在网站运行过程中,还需关注请求延时问题,例如处理请求延时情况如何、哪些页面的延时较大等。您可以自定义查询分析语句分析延迟情况,相关案例如下所示,操作步骤可参见查询与分析快速指引。
计算每5分钟请求的平均延时和最大延时,从整体了解延时情况。
* | select from_unixtime(__time__ -__time__% 300) as time, avg(request_time) as avg_latency , max(request_time) as max_latency group by __time__ -__time__% 300统计最大延时对应的请求页面,进一步优化页面响应。
* | select from_unixtime(__time__ - __time__% 60) , max_by(request_uri,request_time) group by __time__ - __time__%60统计分析网站所有请求的延时分布,将延时分布分成10个组,分析每个延时区间的请求个数。
* |select numeric_histogram(10,request_time)计算最大的十个延时及其对应值。
* | select max(request_time,10)对延时最大的页面进行调优。
例如/url2页面的访问延时最大,需要对/url2页面进行调优,则需计算/url2页面的访问PV、UV、各种请求方法次数、各种请求状态次数、各种浏览器次数、平均延时和最大延时。
request_uri:"/url2" | select count(1) as pv, approx_distinct(remote_addr) as uv, histogram(method) as method_pv, histogram(status) as status_pv, histogram(user_agent) as user_agent_pv, avg(request_time) as avg_latency, max(request_time) as max_latency* | select diff [1] as today, round((diff [3] -1.0) * 100, 2) as growth FROM ( SELECT compare(pv, 86400) as diff FROM ( SELECT COUNT(1) as pv FROM log ) )统计访问PV的昨日同比。
* | select t, diff [1] as today, diff [2] as yestoday, diff [3] as percentage from( select t, compare(pv, 86400) as diff from ( select count(1) as pv, date_format(from_unixtime(__time__), '%H:%i') as t from log group by t limit 10000 ) group by t order by t limit 10000 )
告警
针对性能问题、网站错误、流量急跌或暴涨等情况,您可以设置查询分析语句,并设置告警,操作步骤请参见设置告警。
错误告警
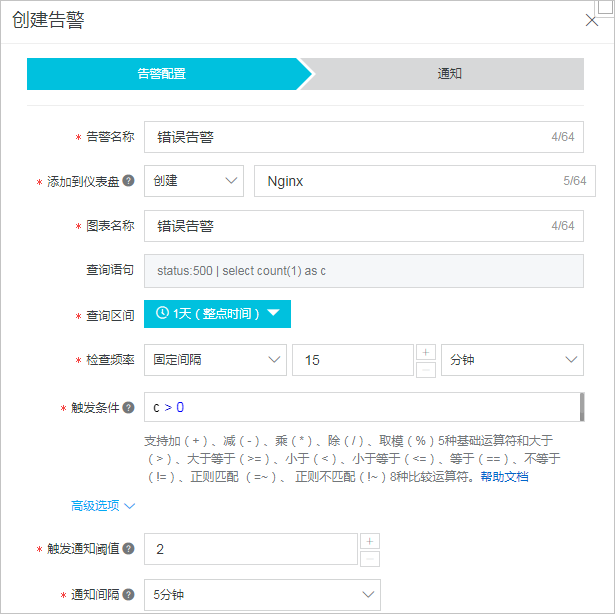
在网站运行过程中,一般需关注500错误,即服务器错误。您可以使用如下查询分析语句计算单位时间内的错误数c,并将告警触发条件设置为c > 0。
status:500 | select count(1) as c说明对于一些业务压力较大的服务,偶尔出现几个500错误是正常现象。针对此情况,您可以在创建告警时,设置触发通知阈值为2,即只有连续2次检查都符合条件才产生告警。
性能告警
如果在服务器运行过程出现延迟增大情况,您可以针对延迟创建告警。例如您可以使用如下查询分析语句分析
/adduser接口所有请求方法为Post的写请求延时,并将告警触发条件设置为 l > 300000,即当延时平均值超过300ms则产生告警。Method:Post and URL:"/adduser" | select avg(Latency) as l使用平均值创建告警的方式比较简单,但会造成一些个体请求延时被平均,无法反映真实情况。针对此问题,您可以使用数学统计中的百分数(例如99%最大延时)来作为告警触发条件,例如使用如下查询分析语句计算99%分位的延时大小。
Method:Post and URL:"/adduser" | select approx_percentile(Latency, 0.99) as p99在监控场景中,您可以使用如下查询分析语句计算一天窗口(1440分钟)内各分钟的平均延时大小、50%分位的延时大小和90%分位的延时大小。
* | select avg(Latency) as l, approx_percentile(Latency, 0.5) as p50, approx_percentile(Latency, 0.99) as p99, date_trunc('minute', time) as t group by t order by t desc limit 1440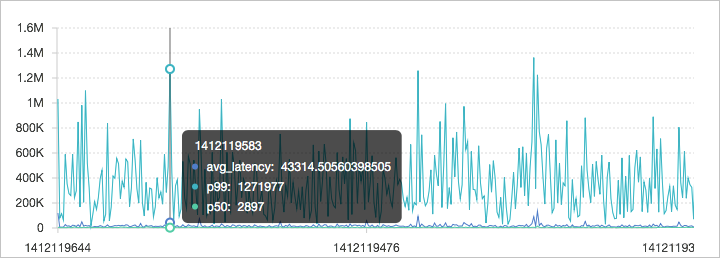
流量急跌或暴涨告警
如果在网站运行过程中出现流量急跌或暴涨情况,一般属于不正常现象。针对此问题,您可以计算流量大小,并设置告警。一般根据如下参考信息反映流量的急跌或暴涨情况:
上一个时间窗口:环比上一个时间段。
上一天该时间段的窗口:环比昨天。
上一周该时间段的窗口:环比上周。
本案例以第一种情况为例,计算流量大小的变动率,日志查询范围为5分钟。
定义一个计算窗口。
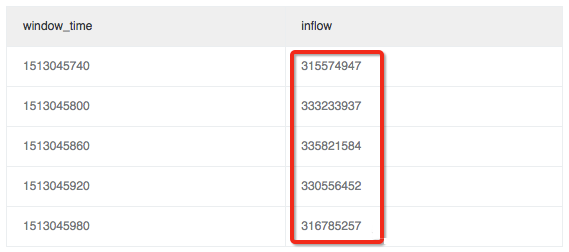
定义一个1分钟的窗口,计算该分钟内的流量大小。
* | select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15从分析结果中看,每个窗口内的平均流量是均匀的。
计算窗口内的差异值。
计算最大值或最小值与平均值的变化率,此处以最大值max_ratio为例。
本示例中计算结果max_ratio为1.02,您可以定义告警条件为max_ratio > 1.5(变化率超过50%)则告警。
* | select max(inflow)/avg(inflow) as max_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)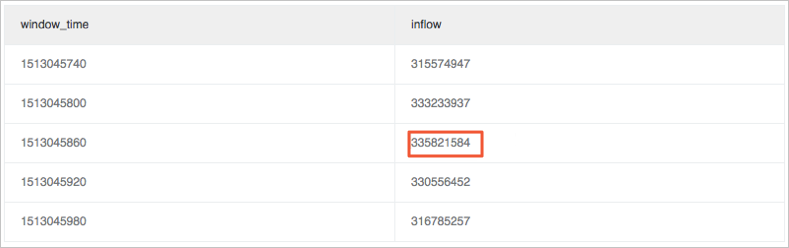
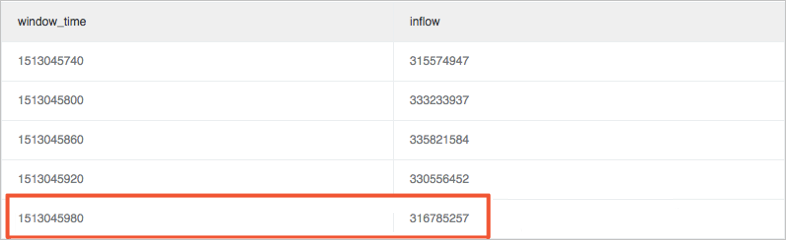
计算最近值变化率,查看最新的数值是否有波动或已恢复。
通过max_by方法获取窗口中的最大流量进行判断,本案例中的计算结果latest_ratio为0.97。
* | select max_by(inflow, window_time)/1.0/avg(inflow) as latest_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)说明max_by函数计算结果为字符类型,需强制转换成数字类型。 如果您要计算变化相对率,可以用(1.0-max_by(inflow, window_time)/1.0/avg(inflow)) as latest_ratio。
计算波动率,即计算当前窗口值与上个窗口值的变化值。
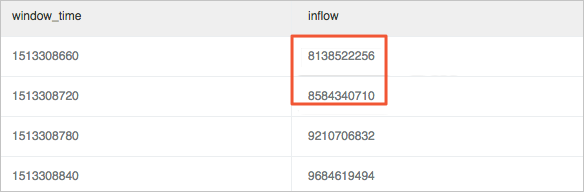
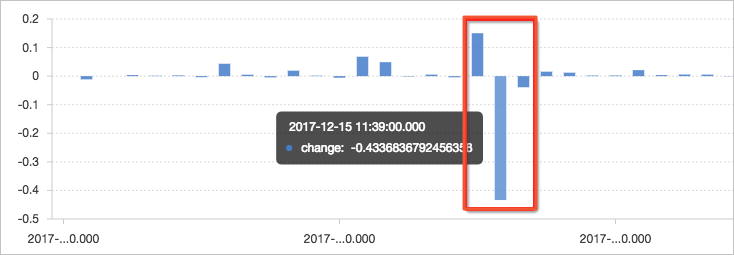
使用窗口函数lag提取当前流量inflow与上一个周期流量inflow "lag(inflow, 1, inflow)over() "进行差值计算,并除以当前流量inflow获取变化率。例如11点39分流量有一个较大的降低,窗口之间变化率为40%以上。
说明如果要定义一个绝对变化率,可以使用abs函数对计算结果进行统一。
* | select (inflow- lag(inflow, 1, inflow)over() )*1.0/inflow as diff, from_unixtime(window_time) from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)