通过本快速入门,可在30分钟内从零开始,使用日志服务(SLS)的LoongCollector数据采集器采集一台ECS服务器上的Nginx日志。内容包括配置日志采集、通过SQL查询分析数据、查看可视化仪表盘、设置告警,以及在体验结束后清理资源以避免产生费用。

前置准备
开通服务与准备账号
开通日志服务:首次使用时,请登录日志服务控制台,根据页面提示开通服务。
准备账号:
准备ECS实例
确保ECS实例的安全组配置满足出口方向开放80(HTTP)端口和443(HTTPS)端口。
生成模拟日志
创建脚本文件
generate_nginx_logs.sh并粘贴以下内容。该脚本向/var/log/nginx/access.log文件中每5秒写入一条标准的Nginx访问日志。授予执行权限:
chmod +x generate_nginx_logs.sh。在后台运行脚本:
nohup ./generate_nginx_logs.sh &。
创建Project和LogStore
Project是日志服务的资源管理单元,用于隔离不同项目的数据;LogStore是日志数据的存储单元。
安装LoongCollector
在创建LogStore成功的弹窗中,单击确定,打开快速数据接入面板。
单击Nginx - 文本日志卡片的立即接入。
机器组配置:
使用场景:主机场景
安装环境:ECS
单击创建机器组,在弹出面板中,选择目标ECS实例。
单击安装并创建为机器组,安装成功后,配置机器组名称(例如
my-nginx-server),单击确定。说明如果安装失败或一直处于等待中,请检查ECS地域是否与Project相同。
单击下一步,检测机器组心跳状态。
首次新建机器组,如果心跳为FAIL,单击自动重试,等待两分钟左右心跳会变为OK。
创建采集配置
心跳状态为OK后,单击下一步,进入Logtail配置页面:
:填写配置名称,如:
nginx-access-log-config。:日志采集的路径,第一个输入框填写文件夹路径:
/var/log/nginx,第二个输入框填写文件名access.log。处理配置:
日志样例:单击添加日志样例,粘贴一行示例日志:
192.168.*.* - - [15/Apr/2025:16:40:00 +0800] "GET /nginx-logo.png HTTP/1.1" 0.000 514 200 368 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.*.* Safari/537.36"处理模式:单击NGINX模式解析插件,在NGINX日志配置中配置log_format,复制并粘贴如下内容,单击确认。
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $request_time $request_length';生产环境中,此处的
log_format必须与Nginx配置文件(通常位于 /etc/nginx/nginx.conf文件中)中的定义保持一致。日志解析示例:
原始日志
结构化解析日志
192.168.*.* - - [15/Apr/2025:16:40:00 +0800] "GET /nginx-logo.png HTTP/1.1" 0.000 514 200 368 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.*.* Safari/537.36"body_bytes_sent: 368 http_referer: - http_user_agent : Mozi11a/5.0 (Nindows NT 10.0; Win64; x64) AppleMebKit/537.36 (KHTML, like Gecko) Chrome/131.0.x.x Safari/537.36 remote_addr:192.168.*.* remote_user: - request_length: 514 request_method: GET request_time: 0.000 request_uri: /nginx-logo.png status: 200 time_local: 15/Apr/2025:16:40:00
单击下一步,进入查询分析配置页面,采集配置生效需要1分钟左右,单击自动刷新,出现预览数据,说明采集配置已生效。
查询与分析日志
单击下一步,进入结束页面。单击查询日志,系统将自动跳转到目标LogStore的查询分析页面,编写SQL分析语句,从结构化日志中提取关键业务与运维指标。指定时间范围为最近15分钟:
如果出现错误弹窗,原因是索引还未配置完成,关闭后等待1分钟,即可查看access.log文件中的日志内容。
示例1:网站总访问量(PV)
统计指定时间范围内的日志总条数。
* | SELECT count(*) AS pv示例2:按分钟统计请求量与错误率
计算每分钟的总请求数、错误请求数(HTTP状态码≥400)以及错误率。
* | SELECT date_trunc('minute', __time__) as time, count(1) as total_requests, count_if(status >= 400) as error_requests, round(count_if(status >= 400) * 100.0 / count(1), 2) as error_rate GROUP BY time ORDER BY time DESC LIMIT 100示例3:统计不同请求方法(GET, POST等)的PV
按分钟和请求方法(GET/POST等)对访问量进行分组统计。
* | SELECT date_format(minute, '%m-%d %H:%i') AS time, request_method, pv FROM ( SELECT date_trunc('minute', __time__) AS minute, request_method, count(*) AS pv FROM log GROUP BY minute, request_method ) ORDER BY minute ASC LIMIT 10000
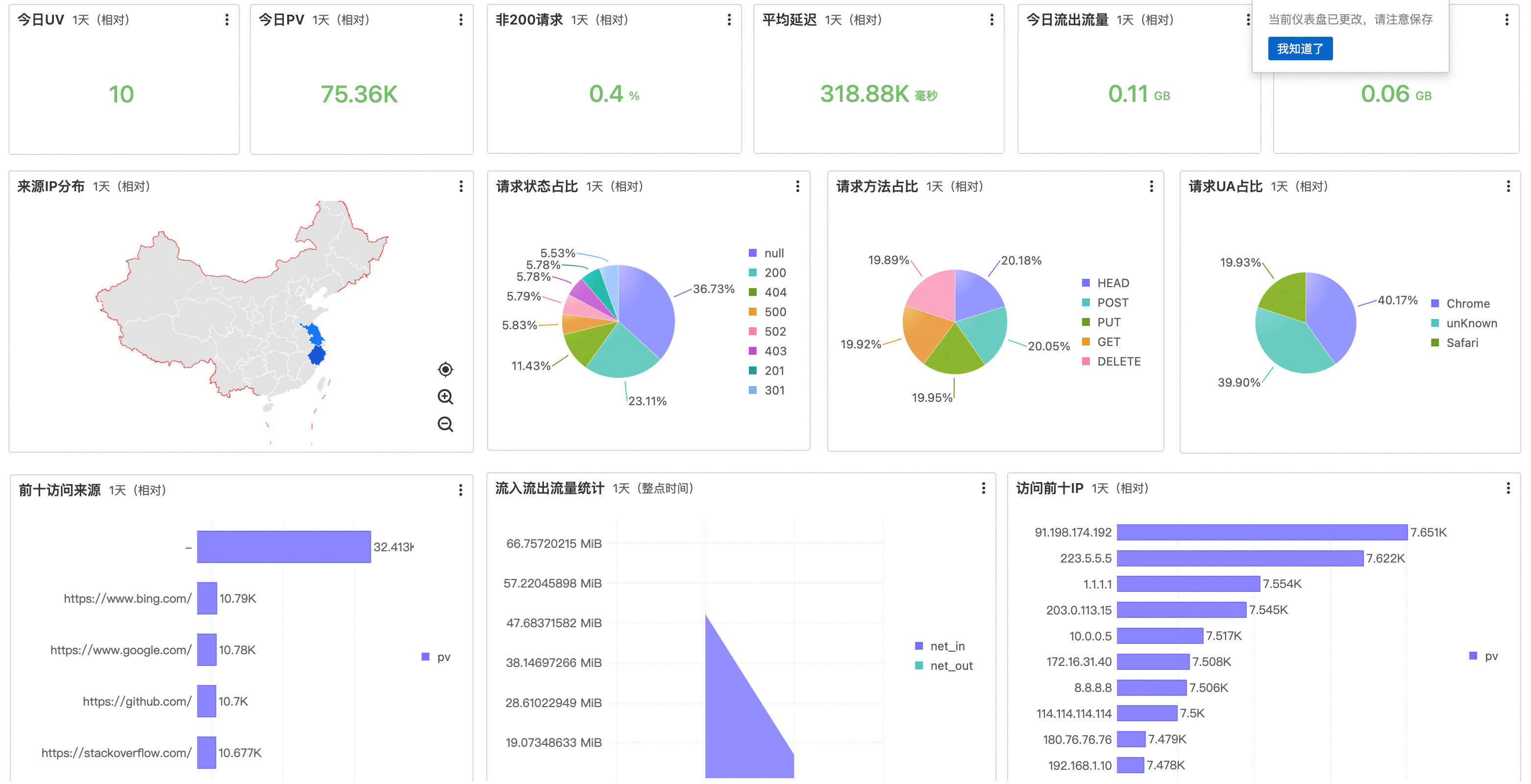
可视化数据仪表盘
配置Nginx解析插件后,日志服务会自动创建一个名为nginx-access-log_Nginx访问日志的预设仪表盘。
在左侧导航栏中,单击
 。
。找到并单击该仪表盘名称,查看包含PV、UV、错误率、请求方法分布等多个核心指标的可视化图表。
所有图表均可根据业务需求自定义修改。
配置监控告警
配置一条告警规则,当服务出现异常(例如错误数激增)时,自动发送通知。
在左侧导航栏中,单击
 告警。
告警。创建行动策略:
在页签下,单击创建。
配置标识符和名称(例如
send-notification-to-admin)。在第一行动列表中,单击
 行动组。
行动组。选择渠道(例如短信),并配置接收人,选择内容模板。
单击 确认 。
创建告警规则:
切换到告警规则页签,单击新建告警。
规则名称:输入描述性名称,例如
服务器5xx错误数过多。查询统计:单击添加,配置查询条件。
日志库:选择已创建的
nginx-access-log。查询区间:15分钟(相对)。
:输入
status >= 500 | SELECT *。单击预览,确认可以查询到数据,单击确定。
触发条件:配置为当:有特定条数据>100条时,触发严重告警。
该配置表示15分钟内出现超过100个5xx错误时触发告警。
:选择SLS通知并开启。
行动策略:选择上一步创建的行动策略。
重复等待:设置为15分钟,避免过多的重复通知。
单击确定,保存告警规则。
验证:告警条件满足时,配置的通知渠道将收到告警信息。可在 告警历史 页面查看所有已触发的告警记录。
资源清理
为避免产生不必要的费用,完成操作后,务必按照以下步骤清理所有已创建的资源。
停止日志生成脚本
登录ECS实例,执行以下命令停止后台运行的日志生成脚本。
kill $(ps aux | grep '[g]enerate_nginx_logs.sh' | awk '{print $2}')卸载LoongCollector(可选)
示例代码中
${region_id}可使用cn-hangzhou替换,若想加快执行速度,请将${region_id}替换为ECS所属地域。wget https://aliyun-observability-release-${region_id}.oss-${region_id}.aliyuncs.com/loongcollector/linux64/latest/loongcollector.sh -O loongcollector.sh;执行卸载命令。
chmod +x loongcollector.sh; sudo ./loongcollector.sh uninstall;
删除Project。
在日志服务控制台Project列表页面,找到已创建的Project(例如
nginx-quickstart-xxx)。在右侧操作列单击删除。
在删除面板中,输入Project名称,选择删除原因。
单击确定,删除Project将同时删除其下的LogStore、采集配置、仪表盘、告警规则等所有关联资源。
警告删除Project后,其管理的所有日志数据及配置信息都会被释放且不可恢复。删除前请慎重确认,避免数据丢失。
后续步骤
通过本教程,您已成功完成日志采集、查询分析、可视化仪表盘和告警配置的全流程操作。建议您继续阅读以下文档,深入理解核心概念,并结合业务需求合理规划日志资源体系:
熟悉数据采集方式,根据实际业务场景选择合适的采集方式。
了解存储资源层级关系说明并规划资源周期,合理分配Shard数量。
常见问题
采集日志后,显示时间与原始日志时间不一致怎么办?
默认情况下,日志服务的时间字段(__time__)使用的是日志到达服务器的时间。若要使用日志原文中的时间,需要在采集配置中添加时间解析插件。
仅创建Project和LogStore,会产生费用吗?
当您在创建LogStore时,日志服务默认预留Shard资源,因此可能产生活跃Shard租用费用。更多信息,请参见为什么会产生活跃Shard租用费用?
日志采集失败,如何排查?
使用Logtail采集日志失败,可能是因为Logtail心跳异常、采集错误、Logtail采集配置错误等原因。如何排查,请参见Logtail采集日志失败的排查思路。
为什么可以查询到日志,但无法进行分析?
分析日志需要为相关字段配置字段索引并开启统计功能,请检查LogStore的索引配置。
如何停止日志服务计费?
日志服务开通后无法关闭,如果不再使用日志服务,可以删除账号下的所有Project即可停止计费。