DataWorks数据开发(DataStudio)模块用于定义周期调度任务的开发及调度属性,与运维中心配合使用,面向各引擎(MaxCompute、Hologres、EMR等)提供可视化开发主界面,支持智能代码开发、多引擎混编工作流、规范化任务发布等能力,帮助您轻松构建离线数仓、实时数仓与即席分析系统,保证数据生产的高效稳定。本文为您介绍数据开发(DataStudio)的相关概念、能力以及开发前准备工作。
进入数据开发
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
数据开发仅支持在PC端Chrome浏览器69以上版本使用。
模块介绍
能力概览
数据开发(DataStudio)的主要功能介绍如下。您可参考数据开发相关概念辅助理解。

类型 | 描述 |
对象组织及管理 | DataWorks数据开发提供的对象组织与管理机制如下:
说明 在数据开发(DataStudio)中,每个工作空间支持创建的业务流程及对象数量限制如下:
若当前工作空间的业务流程及对象数量达到上限,您将无法再执行新建操作。 |
任务开发 |
DataWorks支持的节点类型,详情请参见支持的节点类型。 |
任务调度 |
|
任务调试 | 提供单任务调试机制与基于业务流程的工作流调试机制。详情请参见任务调试流程。 |
流程管控 | 提供规范化任务发布机制,及多种方式的流程管控机制。包括但不限于以下场景: |
其他 |
界面认识
通过DataStudio功能引导了解数据开发操作界面,以及各模块功能如何使用。
开发流程
DataWorks数据开发支持创建多种类型引擎的实时同步任务、离线调度任务(包括离线同步任务、离线加工任务)、手动触发任务。其中,数据同步相关能力您可前往数据集成模块了解;实际开发调度任务时,不同引擎任务的配置要求存在差异,您需先了解不同引擎基于DataWorks开发的注意事项及相关说明,再根据待开发的任务类型开始数据开发工作。
各引擎开发说明:DataWorks支持创建各种数据源并进行引擎开发任务,不同引擎任务所需的配置存在差异,其中主要引擎任务的开发说明请参见:
通用开发流程:DataWorks的工作空间分为标准模式和简单模式,不同模式工作空间下调度任务的开发流程存在一定差异,具体如下。
标准模式工作空间开发流程。

简单模式工作空间开发流程。
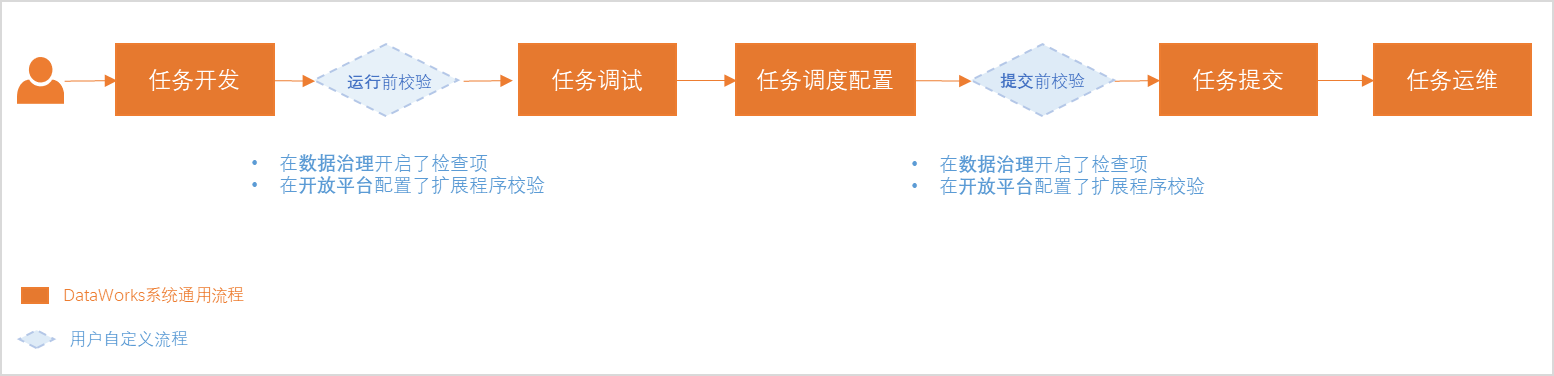
管理方式
DataWorks数据开发的业务流程是具体代码开发、资源组织的单位,是业务的抽象实体,帮助您使用业务视角来组织数据代码开发。工作空间之间的业务流程、任务节点为独立开发,互不影响。更多关于业务流程的使用,详情请参见创建业务流程。
业务流程的呈现包括目录树及操作面板两种方式,帮助您基于业务视角组织代码,使资源类别更明确,业务逻辑更清晰。
目录树结构:提供基于任务类型的代码组织方式。
业务流程面板:提供流程化的业务逻辑展现方式。
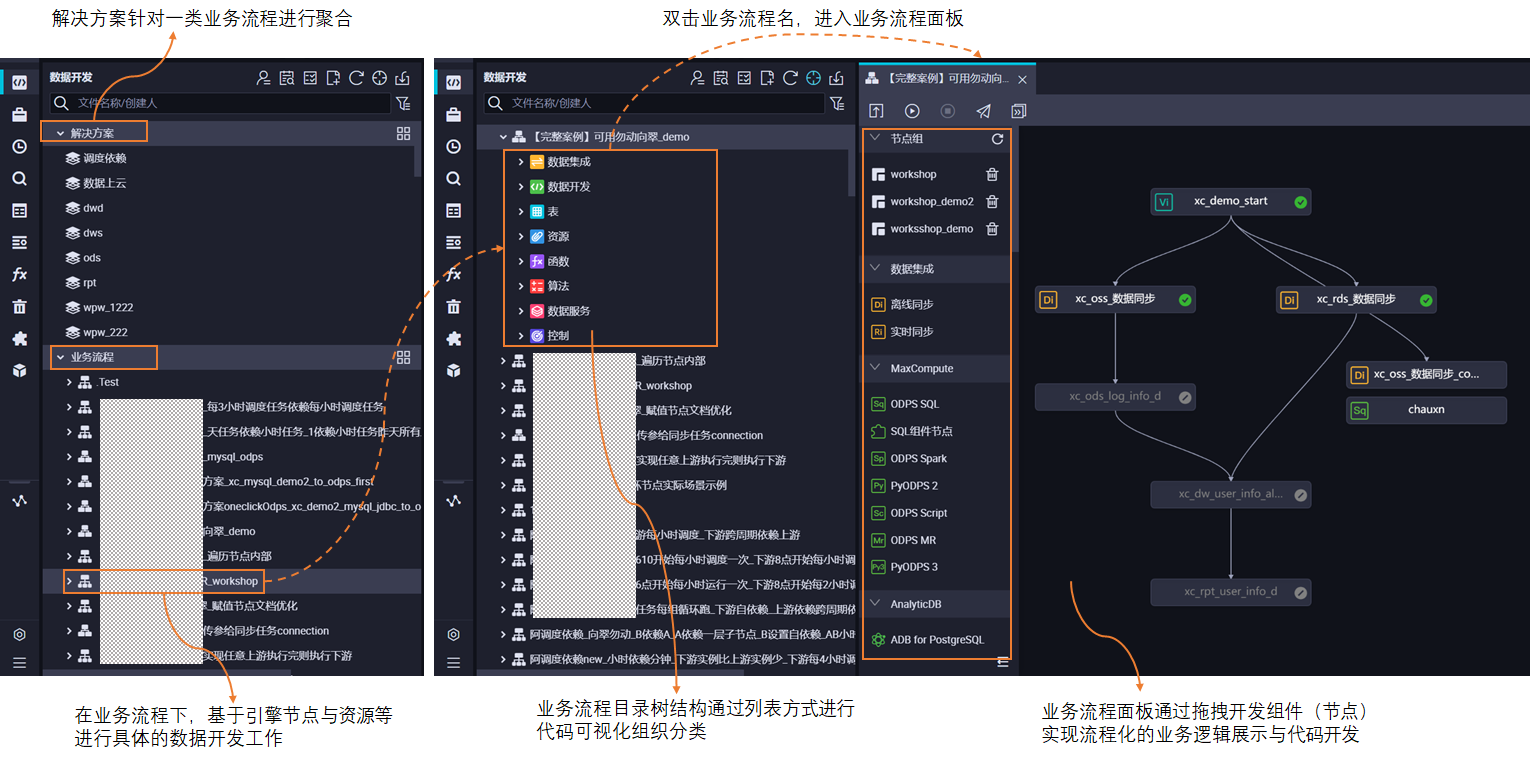
开始使用
环境准备
若您要在DataWorks中进行数据建模、数据开发或使用运维中心周期性调度任务,必须将已创建的数据源或集群在数据开发(DataStudio)模块绑定为计算资源。绑定后才可读取数据源或集群中的数据,并进行相关开发操作,否则将无法创建数据开发节点。
您需根据后续要开发和调度的任务类型,提前创建好对应的数据源或集群。
数据源或集群
说明
首次创建MaxCompute数据源后,DataWorks会自动将数据源绑定至数据开发(DataStudio),您无需按本文手动绑定。但后续创建的MaxCompute数据源需要手动绑定至数据开发(DataStudio)。
创建这些数据源后,需要参照本文指导手动绑定。
注册集群后,DataWorks会将集群绑定至数据开发(DataStudio),您无需按本文手动绑定。
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
在左侧导航栏单击计算资源,进入计算资源新建页面。
若左侧导航栏未显示计算资源模块,则您需进入个人设置页面,设置该模块显示至左侧导航栏中。操作详情请参见模块管理。
绑定计算资源。
在计算资源新建页面,您可通过计算资源名称或计算资源类型搜索找到目标数据源或集群进行绑定操作。绑定后,便可基于数据源的连接信息读取该数据源的数据,进行相关开发操作。
说明当数据源信息发生变更时,若当前界面数据更新不及时,请刷新当前页面更新缓存数据。

部分场景可能导致数据源或集群无法绑定至DataStudio(数据开发):
部分数据源或集群是否可在DataStudio绑定,与数据源或集群的配置有关。例如,不支持在DataStudio绑定AccessKey及AccessSecret模式创建的数据源。更多绑定限制,请参见产品绑定界面提示说明。
数据源缺失开发环境或生产环境。
一个MaxCompute计算资源不能同时被多个DataWorks工作空间绑定。
说明不同数据源或集群无法绑定至DataStudio(数据开发)的原因存在差异,平台会自动展示不支持绑定的原因,您可基于具体原因进行排查处理。
当前仅支持绑定MaxCompute、E-MapReduce、Hologres、AnalyticDB for MySQL、ClickHouse、CDH/CDP、AnalyticDB for PostgreSQL至DataStudio(数据开发)。
不同DataWorks版本,支持绑定的数据源或集群类型及数量限制存在差异。详情请参见DataWorks各版本功能详情。
入门教程
您可以参考数据开发入门,快速了解并掌握数据开发的基本操作及开发流程,详情请参见数据开发入门。
支持的节点类型
DataWorks的数据开发(DataStudio)模块提供多种类型节点,同时,多种类型节点支持周期性任务调度,您可基于业务需要选择合适的节点进行相关开发操作。DataWorks支持的节点合集,详情请参见支持的节点类型。
附录:数据开发相关概念
任务开发相关。
概念
描述
解决方案
业务流程的集合。您可将一类业务流程划分为一个解决方案进行统筹管理。一个业务流程可被多个解决方案复用。进行数据开发时,其他用户可在其它解决方案中,直接编辑您解决方案中引用的业务流程,进行协同开发。
业务流程
面向某一特定业务需求的任务、表、资源、函数的集合,是业务的抽象实体。该类业务流程中的任务可按计划定时触发运行。
手动业务流程
面向某一特定业务需求的任务、表、资源、函数的集合。
手动业务流程与业务流程的区别为:手动业务流程中的任务需手动触发运行,而业务流程中的任务是按计划来定时触发运行。
DAG
英文
Directed Acyclic Graph的缩写,即有向无环图。用于展示节点及其依赖关系。在数据开发(DataStudio)中,业务流程下的所有任务会展示在同一个DAG中,方便您进行任务开发及依赖关系配置。任务
任务是DataWorks的基本执行单元。DataWorks根据任务间的依赖关系依次执行各个任务。
节点
节点用于指代DAG中的一个任务。DataWorks根据节点间的依赖关系依次运行各个节点。
任务调度相关。
概念
描述
依赖关系
任务间通过依赖关系定义任务的运行顺序。如果节点A运行后,节点B才能运行,我们称A是B的上游依赖,或者B依赖A。在DAG中,依赖关系用节点间的箭头表示。
输出名
用于区分本节点与其他节点的标识符。输出名全局唯一,一个节点可包含多个输出名。DataWorks通过输出名设置节点调度依赖关系。
输出表名
输出表名建议配置为当前任务的产出表,正确填写输出表名可以方便下游设置依赖时确认数据是否来自期望的上游表。自动解析生成输出表名时不建议手动修改,输出表名仅作为标识,修改输出表名不会影响SQL脚本实际产出的表名,实际产出表名以SQL逻辑为准。
说明节点的输出名需要全局唯一,而输出表名无此限制。
调度资源组
指用于任务调度的资源组。资源组介绍详情请参见DataWorks资源组概述。
调度参数
调度参数是代码中用于调度运行时动态取值的变量。代码在重复运行时若希望获取到运行环境的一些信息,例如日期、时间等,可根据DataWorks调度系统的调度参数定义,动态为代码中的变量赋值。
业务日期
指昨天,在离线计算场景下,交易日期为业务发生的日期。DataWorks默认取调度时间内,任务预期调度运行时间的前一天(即昨天)的日期为业务日期,精确到天。例如,今天统计前一天的营业额,此处的前一天,指交易发生的日期,也就是业务日期。
定时时间
指今天,即某业务数据加工任务的预期执行时间。DataWorks默认取调度时间内,任务预期调度运行的时间点(即今天)为定时时间,精确到秒。任务预期执行时间,与实际开始执行时间并非完全一致。任务实际开始执行时间受多方因素影响。