本文为您介绍实时计算Flink版产品有关的基础背景知识。
什么是实时计算?
数据的业务价值会随着时间的流失而迅速降低,因此在数据发生后必须尽快对其进行计算和处理。目前,对于信息的高时效性和可操作性要求越来越高,这就要求软件系统能够在更短的时间内处理更多的数据。而传统的大数据处理模型将在线事务处理和离线分析从时序上完全分开,对于数据加工均遵循传统的日清日毕模式,即以小时甚至以天为计算周期对当前数据进行累计并处理。显然,传统的大数据处理方式无法满足数据实时计算的需求。数据处理时延造成的影响对要求苛刻的业务场景会非常明显,例如实时大数据分析、风控预警、实时预测和金融交易等领域。
实时计算可以有效地缩短全链路数据流时延、实时化计算业务逻辑、平摊计算成本,最终有效满足实时处理大数据的业务需求。实时计算具备三大特点:
实时(Realtime)且无界(Unbounded)的数据流
实时计算面对的数据是实时且流式的,这些数据按照时间发生顺序被实时计算订阅和消费。例如网站的访问单击日志流,只要网站不关闭,其单击日志流将不停产生并进入实时计算系统。
持续(Continuous)且高效的计算
实时计算是一种事件触发的计算模式,触发源为无界流式数据。一旦有新的流数据进入实时计算系统,它就立刻发起并进行一次计算任务,因此整个过程是持续进行的。
流式(Streaming)且实时的数据集成
被流数据触发的计算结果,可以被直接写入目的数据存储。例如将计算后的报表数据直接写入阿里云关系型数据库RDS(Relational Database Service)进行报表展示。因此流数据的计算结果可以同流式数据一样,持续被写入目的数据存储。
什么是流数据?
所有大数据的产生均可以看作是一系列离散事件,这些离散事件是一条条事件流或数据流。相对于离线数据,流数据的规模普遍较小。流数据是由数据源持续产生的数据,示例如下:
使用移动或Web应用程序生成的日志文件。
网购数据。
游戏内玩家活动信息。
社交网站信息。
金融交易大厅或地理空间服务数据中心内所连接设备或仪器的遥测数据。
地理空间服务信息。
设备或仪器的遥测数据。
实时计算与批量计算相比存在哪些差异?
下面从用户和产品层面来理解两类计算方式的区别。
批量计算
批量计算是一种批量、高时延、主动发起的计算。目前绝大部分传统数据计算和数据分析服务均基于批量数据处理模型,即使用ETL系统或者OLTP系统进行构造数据存储,在线的数据服务(包括Ad-Hoc查询、DashBoard等)通过构造SQL语言访问上述数据存储并取得分析结果。传统的批量数据处理模型如下图所示。
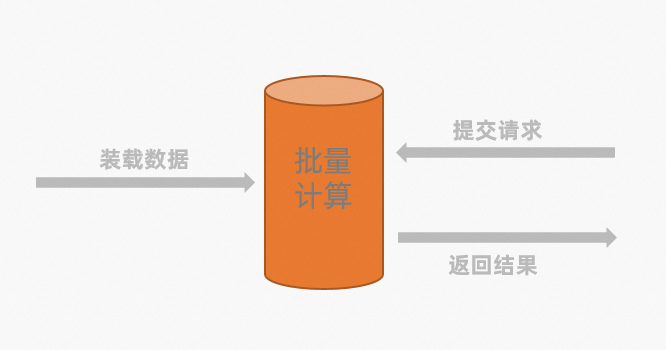
传统的批量数据处理流程如下:
装载数据
对于批量计算,需要预先将数据加载到计算系统,您可以使用ETL系统或者OLTP系统装载原始数据。系统将根据自己的存储和计算情况,对于装载的数据进行一系列查询优化、分析和计算。
提交请求
系统主动发起一个计算作业(例如MaxCompute的SQL作业,或Hive的SQL作业)并向上述数据系统进行请求。此时计算系统开始调度(启动)计算节点进行大量数据计算,该过程的计算量可能非常大,耗时长达数分钟乃至于数小时。由于数据累计处理不及时,上述计算过程中可能就会存在一些历史数据,导致数据不新鲜。
说明对于批量计算,您可以根据业务需求,随时调整SQL语句,也可以使用AdHoc查询做到即时修改和即时查询。
返回结果
计算作业完成后将数据以结果集形式返回给用户,由于保存在数据计算系统中的计算结果数据量巨大,需要用户再次集成数据到其他系统。一旦数据结果巨大,整体的数据集成过程就会漫长,耗时可能长达数分钟乃至于数小时。
实时计算
实时计算是一种持续、低时延、事件触发的计算作业。由于当前实时计算的计算模型较为简单,所以在大部分大数据计算场景下,实时计算可以看做是批量计算的增值服务,实时计算更强调计算数据流和低时延。实时计算数据处理模型如下。
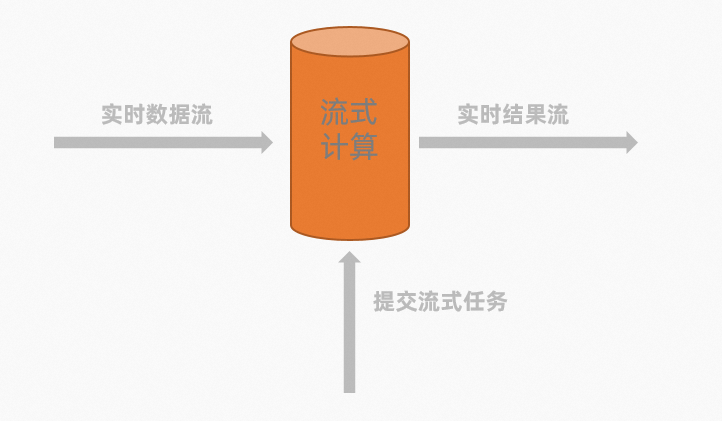
实时数据流
使用实时数据集成工具,将实时变化的数据传输到流式数据存储(例如消息队列、DataHub)。此时数据的传输实时化,将长时间累积的大量数据平摊到每个时间点,不停地小批量实时传输,因此数据集成的时延得以保证。
源源不断的数据被写入流数据存储,不需要预先加载。同时,实时计算对于流式数据不提供存储服务,数据持续流动,在计算完成后就被立刻丢弃。
提交流式任务
批量计算要等待数据集成全部就绪后才能启动计算作业,而流式计算作业是一种常驻计算服务。实时计算作业启动后,一旦有小批量数据进入流式数据存储,实时计算会立刻计算并得出结果。同时,阿里云实时计算还使用了增量计算模型,将大批量数据分批进行增量计算,进一步减少单次运算规模并有效降低整体运算时延。从用户角度,对于流式作业,必须预先定义计算逻辑,并提交到流式计算系统中。
说明对于实时计算,在作业运行期间,可以修改作业逻辑后但无法实时生效,需要重启作业。而且,已经计算完成的数据无法重新再次被计算。
实时结果流
批量计算的结果数据需等待数据计算结果完成后,批量将数据传输到在线系统。不同于批量计算,流式计算作业在每次小批量数据计算后,无需等待整体的数据计算结果,会立刻将数据结果投递到在线/批量系统,实现计算结果的实时化展现。
使用实时计算的顺序如下:
提交实时计算作业。
等待流式数据触发实时计算作业。
计算结果持续不断对外写出。
计算模型差别对比,详情内容如下表所示。
对比指标 | 批量计算 | 实时计算 |
数据集成方式 | 预先加载数据。 | 实时加载数据到实时计算。 |
使用方式 | 业务逻辑可以修改,数据可重新计算。 | 业务逻辑一旦修改,之前的数据不可重新计算(流数据易逝性)。 |
数据范围 | 对加载的所有或大部分数据进行查询或处理。 | 对滚动时间窗口内的数据或仅对最近的数据记录进行查询或处理。 |
数据大小 | 大批量数据。 | 单条记录或几条记录的微批量数据。 |
性能 | 几分钟至几小时的延迟。 | 大约几秒或几毫秒的延迟。 |
分析 | 复杂分析。 | 简单的响应函数、聚合和滚动指标。 |