数据类型概述
Blob(Binary Large Object)数据类型是MaxCompute提供的一种用于在表中存储图片、音频、视频、文档等非结构化二进制大对象的数据类型。通过 Blob 类型,可以将多模态数据的原始文件、元信息和标注信息统一存储在同一张MaxCompute表中,使用 SQL 统一查询和维护,通过MaxFrame 和 SQL UDF 批量加工处理。
适用场景
AI 训练数据集管理:将图片、音频、视频与标注标签存储在同一张表中,通过 SQL 过滤所需样本数据集。
多模态数据处理流水线:视频切帧、音频转文本、内容打标等多步骤流水线的中间结果和最终产物统一存储。
多模态加工缓存层:作为对象存储等数据源的缓存层,提升 MaxFrame、SQL 大规模并行计算的吞吐性能,解决小文件批量请求的 QPS 限制。
非结构化数据入湖:将分散在外部存储中的文件统一导入 MaxCompute,扩展元信息建立企业非结构化资产库,获得事务保障和统一权限管控。
功能规格
特性 | 规格说明 |
大小限制 | 每个单元格 Blob 对象最大 5 GB |
存储格式 | 二进制格式 |
支持Blob的表格式 | Append Delta Table。Blob 列继承表格式特性,支持 ACID 事务、分层存储和 Snapshot。 |
Blob优化服务 |
|
使用限制
必须开启 MaxCompute 2.0 数据类型:
SET odps.sql.type.system.odps2=true;。Blob 类型不可嵌套在 ARRAY、MAP、STRUCT 等复杂类型中。
Blob 列不可作为主键列和分区键。
Blob 列不支持用于 ORDER BY、GROUP BY 和 JOIN ON 条件。
多模态混合存储
下图展示了传统分散存储架构与 MaxCompute 多模态统一存储架构的对比。
左侧为传统方案,原始文件存储在对象存储中,元信息和标注信息分散在不同的数据仓库和数据湖中,查询和处理需要跨多个系统协调。
右侧为 MaxCompute 方案,通过 Blob 列类型将图片、音频、视频等二进制文件与结构化元信息统一存储在同一张表中,支持 SQL 查询、MaxFrame 批处理和 SDK 数据导入等操作。

MaxCompute 通过原生支持 Blob 列类型,将所有数据统一存储在同一张表中,实现原始文件、元信息和标注信息的同表存储:
-- 多模态数据集表示例
CREATE TABLE multimodal_dataset (
id BIGINT NOT NULL,
image BLOB, -- 原始图片二进制
label STRING, -- 分类标签
bbox STRING, -- 标注边界框 (JSON)
resolution STRING, -- 分辨率元信息
created_at DATETIME -- 入库时间
) TBLPROPERTIES("table.format.version"="2");传统方案与 MaxCompute 多模态方案对比
在传统架构中,多模态数据的原始文件、元信息、标注信息分散在对象存储、数据仓库、数据湖等多个引擎中。MaxCompute 通过原生支持 Blob 列类型,将所有数据统一存储在同一张表中,解决了以下问题:
传统方案的问题 | MaxCompute 多模态方案 |
维护成本高:多引擎架构导致数据分散在各处,难以统一管理。 | 统一存储管理:原始文件、元信息、标注信息存储在同一张表中,无需维护多套系统。 |
跨引擎查询延迟高:例如根据标签筛选图片时,需先查数据库再去对象存储读文件,属于多跳查询。 | SQL 直接过滤:按标签、时间等条件查询数据,无需跨系统多跳访问。 |
缺乏统一 ACID 保障:数据一致性、访问权限和数据血缘无法集中管控。 | 完整 ACID 事务及统一权限管控:每次写入具有原子性和一致性保障,所有数据纳入 MaxCompute 权限体系管理。 |
处理流水线割裂:典型的多模态工作流(视频 → 音频提取 → 文本转写 → 切帧 → 内容打标 → 元信息提取)跨越多个系统,中间数据搬运频繁。 | 统一处理流水线:多步骤流水线的中间结果和最终产物集中在一张表中,消除跨系统数据搬运。 |
存储模式与性能收益
存储模式
MaxCompute Blob 采用引用-实体分离的存储模式,将结构化数据列与 Blob 大对象列拆分到不同的物理文件中。如下图所示,整体架构分为三层:
接入层提供 SQL、MaxFrame、ODPSCMD、SDK、StorageAPI 等多种访问方式;
服务层负责 Compaction、Blob Reference 路由、ACID 事务管理、分层存储(Storage Tier)和备份;
存储层将数据拆分为
Data File(结构化数据文件):存储表中的非 Blob 列数据(如 id、label、metadata 等)以及 Blob 列的引用指针(Reference)。这些文件采用标准列式存储,支持高效的谓词下推和列裁剪。
Blob File(大对象文件):存储 Blob 对象的原始二进制内容、数据校验信息和索引信息。根据每个 Blob 对象大小动态拆分或合并存储文件。
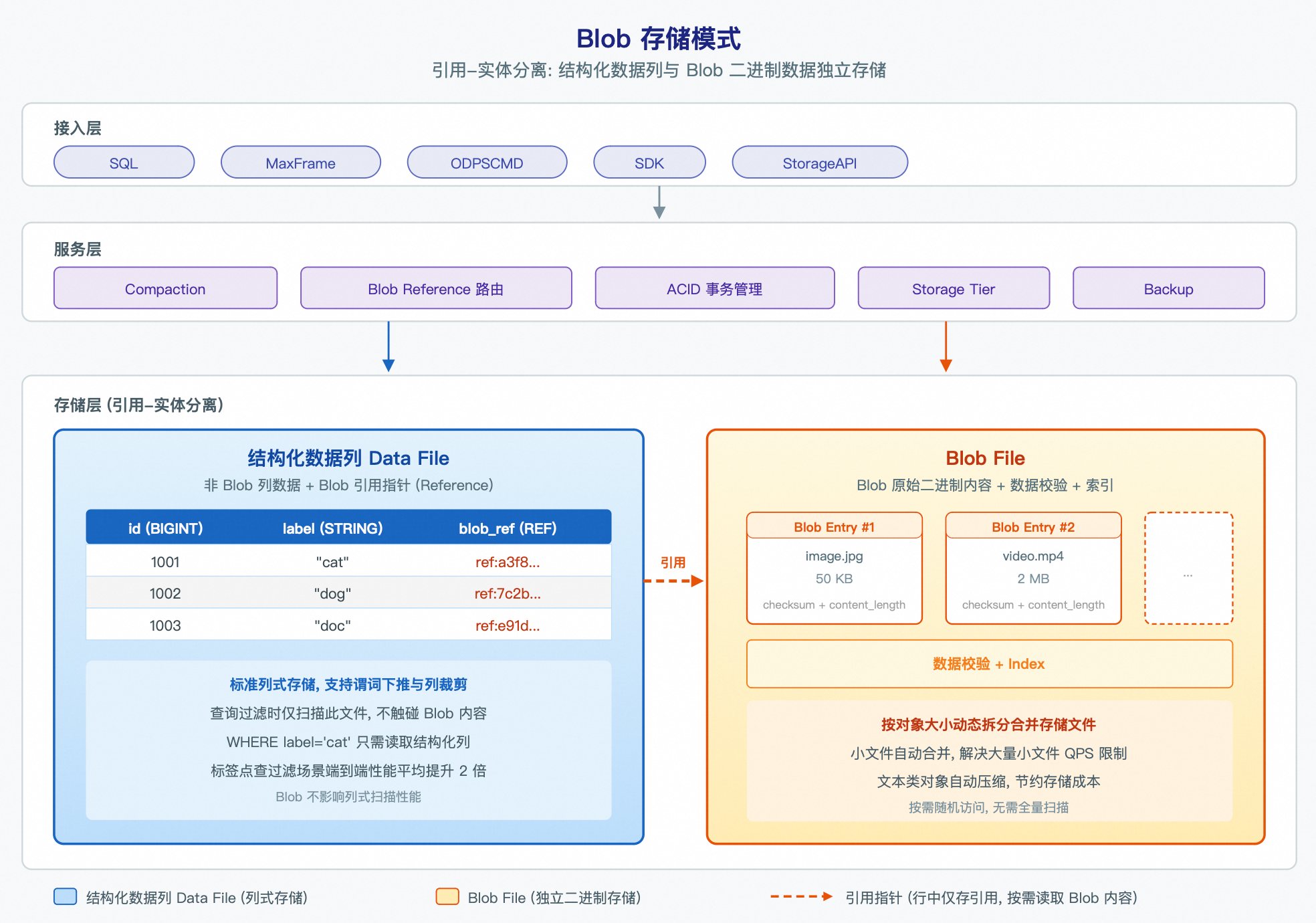
数据写入时,系统将二进制内容上传到 Blob File,并将引用指针写入结构化数据列Data File;读取时,先通过结构化列获取引用指针,再按需从 Blob File 加载二进制内容。Blob 上传和引用写入在同一个 Session Commit 中完成,读写操作会在 MaxCompute 内部完成事务管理,保证原子性。
上述逻辑对用户透明,日常使用中无需关注底层存储差异。
性能收益
小文件合并与压缩
Blob 存储会自动将大量小对象(图片、HTML 片段、JSON 会话日志等)合并成 Blob File,支持批量读写,解决大量小文件请求的 QPS 限制问题。
文本类对象写入时自动压缩,访问时自动解压。例如 HTML 片段和 JSON 文本,平均可节约约 2 倍存储空间,降低存储成本。
标签点查过滤数据集场景,文件对象不影响列式扫描性能
当根据元信息、标签列过滤数据时(如查找特定标签的样本),将对象存储成 Blob 类型相比用 String/Binary 类型存储二进制数据,端到端性能平均提升 2 倍(根据实际数据评估)。
例如,对 100 万张平均大小 1.4 MB 的图片建立数据集,对比将 image 存储为 Binary 和 Blob 类型的查询开销:
存储方式
标签过滤扫描数据量
image 存储为 BINARY 列
约 1,400 GB(全表扫描)
image 存储为 BLOB 列
约 30 GB(仅 Data File)
执行如下标签过滤查询,Binary类型表将执行全表扫描,TableScan 数量 1400 GB,Blob 表 TableScan 数量 30 GB,扫描数据量降低了 45 倍。
-- image存储为Binary类型 SELECT id, image FROM multimodal_dataset_binary Where label = "cat"; -- image存储为Blob类型 SELECT id, read_blob(image) FROM multimodal_dataset_blob Where label = "cat";
数据导入导出
方式一:通过 SDK 批量上传和下载
适用于大规模数据的高吞吐批量读写。使用MaxCompute Java SDK:0.57.1-public 及以上版本。
对于 1 MB 以下的 Blob 对象,推荐使用 Batch 批量上传接口,SDK 会自动组装成 64 MB 一批上传。
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-storage-api</artifactId>
<version>0.57.1-public</version>
</dependency>方式二:通过 Object Table 从对象存储批量导入
适用于将对象存储OSS中已有的大量非结构化文件(图片、音视频、文档等)批量导入 MaxCompute 包含 Blob 数据类型的表。通过创建 OBJECT TABLE获取对象存储OSS Bucket 中的对象和元信息,然后批量插入到 MaxCompute 多模态表,整个过程无需二次中转。
示例如下:
-- Step 1: 创建 Object Table 关联 OSS 数据
SET odps.namespace.schema=true;
SET odps.sql.type.system.odps2 = true;
CREATE OBJECT TABLE oss_images
LOCATION 'oss://<accessKeyId>:<accessKeySecret>@<endpoint>/<bucket>/<path>/';
-- 刷新元数据
ALTER TABLE oss_images REFRESH METADATA;
-- Step 2: 创建包含Blob类型的多模态表
CREATE TABLE ods_dataset_images (
key VARCHAR(2048) COMMENT '对象键',
size BIGINT COMMENT '对象大小',
type VARCHAR(32) COMMENT '对象类型',
last_modified TIMESTAMP_NTZ COMMENT '最后修改时间',
storage_class VARCHAR(32) COMMENT '存储类别',
etag VARCHAR(64) COMMENT 'ETag信息',
restore_info VARCHAR(256) COMMENT '恢复信息',
owner_id BIGINT COMMENT '所有者ID',
owner_display_name VARCHAR(256) COMMENT '所有者显示名称',
data_file BLOB COMMENT '数据文件'
) COMMENT '多模态表'
tblproperties ('table.format.version'='2') ;
-- Step 3: 批量导入到 Blob 表
INSERT OVERWRITE ods_dataset_images
SELECT key, size, type, last_modified, storage_class, etag, restore_info, owner_id, owner_display_name,
to_blob(get_data_from_oss('<project_name>.default.oss_images', key)) AS data_file
FROM oss_images;SQL语法
DDL
建表语句支持多 Blob 列。
CREATE TABLE video_dataset (
id BIGINT,
video BLOB,
thumbnail BLOB,
title STRING
) TBLPROPERTIES('table.format.version'='2');Blob 函数
to_blob() — 创建 Blob 对象
to_blob函数用于将字符串或二进制数据转换为 Blob 对象。
函数 | 说明 |
| 将字符串整体转为 Blob |
| 将二进制值整体转为 Blob |
| 从 |
| 从 |
| 从 |
| 从 |
-- 从字符串创建 Blob
SELECT to_blob('hello world'); -- 返回结果:Blob{reference=CAEQAxqqAgEAAAAJA...}
-- 从十六进制二进制创建 Blob
SELECT to_blob(X'89504E47'); -- PNG 文件头
-- 带偏移截取
SELECT to_blob('hello world', 6); -- 结果:'world'
SELECT to_blob('hello world', 0, 5); -- 结果:'hello'read_blob() — 读取 Blob 内容
read_blob函数用于将 Blob 对象内容以 STRING 或 BINARY 形式返回。
函数 | 说明 |
| 读取完整 Blob 内容为 STRING |
| 从 |
| 从 |
-- 读取 Blob 内容
SELECT id, read_blob(image) FROM image_dataset WHERE label = 'cat' LIMIT 10;
-- 读取部分内容(如文件头判断类型)
SELECT id, read_blob(content, 0, 4) AS file_header FROM media_library;
-- 嵌套使用
SELECT read_blob(to_blob('hello world')); -- 返回 'hello world'length() — 获取 Blob 字节长度
-- 获取 Blob 的字节长度
SELECT id, length(read_blob(video)) AS image_size FROM image_dataset;使用示例
-- 创建包含Blob类型的Table
CREATE TABLE blob_table (col1 BLOB)
TBLPROPERTIES (
"table.format.version"="2"
);
-- 数据写入
INSERT INTO blob_table VALUES (to_blob("hello world"));
-- 数据读取
SELECT read_blob(col1) FROM blob_table;