支持的数据模型架构
Quick BI支持以下类型的数据模型。以下模型范围对于逻辑层(关系模型)和物理层(物理模型)是一致的。
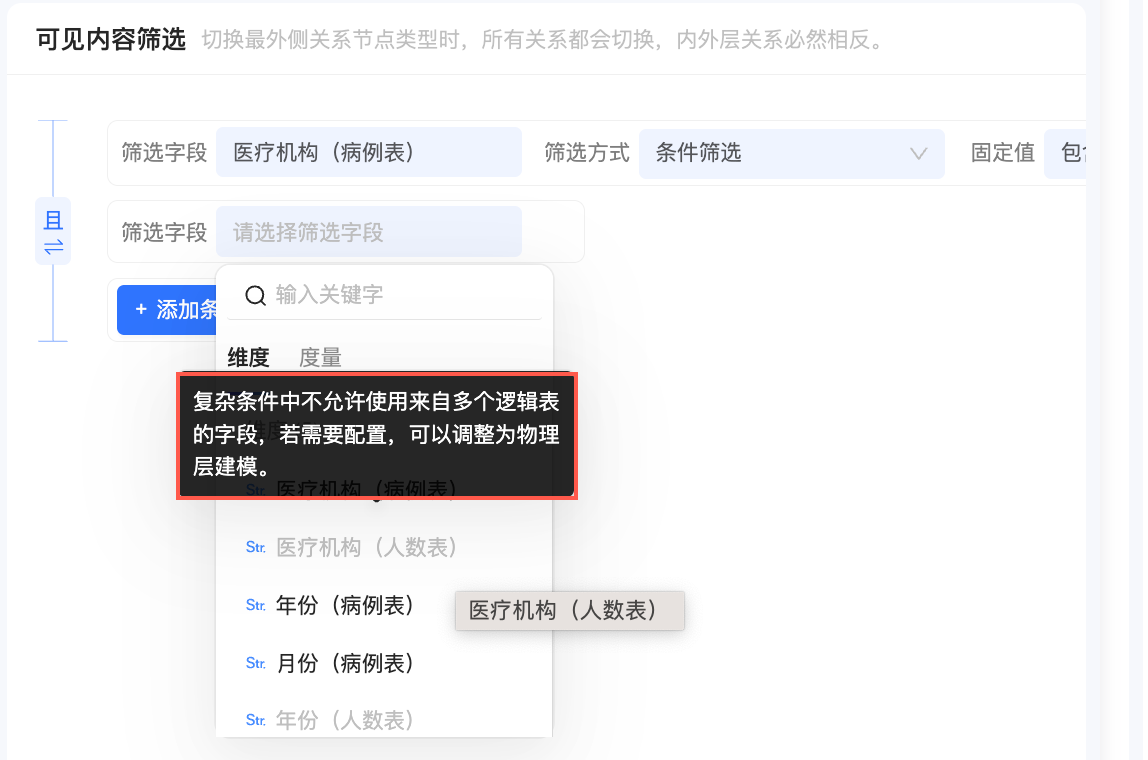
以下示意图中,蓝色区块代表维度,绿色区块代表度量;只有蓝色区块的表为维度表,包含绿色区块的表为事实表。
单表模型
拖入单张表进入画布中,即可构造单表模型。
除此之外,多张表的合并结果也被视为单表模型。

星型模型
星型模型是一种常见的数据模型,由一个事实表和多个维表组成,维表分别与事实表关联。
事实表是建模的核心,而维度表提供了与事实表相关的上下文信息,通过共同的关联键进行关联。这种结构让我们可以灵活地按照不同的维度对数据进行切片和分析,就像可以从不同的角度观察星星。星型模型设计简单易懂,同时查询性能也比较高。
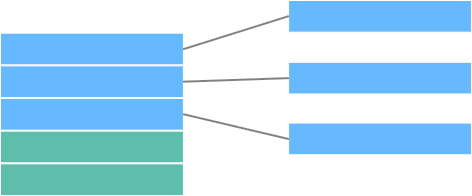
雪花模型
雪花模型也是常见的数据模型,同样的由一个事实表和多个维表组成。和星型模型不同的是,雪花模型中存在没有直接与事实表关联的维度表,这部分维度表被细化和拆分,形成了多个层级。

度量位于多个表中的星型模型和雪花模型
在传统的星型模型和雪花模型中,用于分析的所有度量都包含在事实表中。但是通常情况下,需要分析的度量和维度可能散布在多个表中。即使维度表不包含度量,在分析中,也可以通过计数或其他方式对维度表中的数据进行聚合。在这些情况下,事实表和维度表将没有明显的区分,形成度量位于多个表中的星型模型和雪花模型。
为了保证您的数据模型更加清晰,Quick BI建议您首先将最细粒度的表添加到数据集画布中,然后将所有其他表与第一个表相关联。
需注意,当多个表中都存在度量时,很容易因数据粒度不一致而导致数据膨胀,此时建议使用关系模型而不是物理模型。
在何时推荐使用关系模型
通过关系模型实现零基础建模
对于SQL能力、数据建模能力较弱的用户,建议直接使用关系模型进行建模。此时,用户只需要正确指定两表之间的关联键即可,其他的计算适配将由Quick BI自动完成,可有效避免因配置错误导致的数据膨胀等问题。
此时,建议用户不要修改“高级配置”,而是直接使用默认值。在使用默认值时,Quick BI将处理所有可能出现的数据膨胀,保证最终计算的正确。配置修改之后,可一定程度提升查询性能,但也存在因缺少部分处理导致的数据膨胀问题。只有当您对数据情况有非常清晰的把控,且能够确定未来也不会发生关联关系、数据匹配度的变化时,才建议您修改“高级配置”。
举例说明
HR部门为鼓励公司员工积极参与培训、课程等活动,制定了积分机制,可通过参加活动获取积分,积分可用来兑换礼品。数据库底层有2张表,分别为:
积分获取表:日期、员工ID、所在部门、参与活动名称、获取积分
积分兑换表:日期、员工ID、所在部门、兑换礼品名称、消耗积分
积分获取表和积分兑换表存在以下数据关系:
积分获取表 - 积分兑换表 | ||
关联关系 | N:N | 小王可以参与多个活动获取积分,也可以多次兑换礼品;在2张表中,“员工ID”都是不唯一的 |
数据匹配度 | 部分:全部 | 小王获取了积分,但从未兑换礼品,因此“积分获取表”里有小王,“积分兑换表”里没有 若某个员工从未获取过积分,自然也无法兑换礼品,因此不会出现“积分兑换表”有,但“积分获取表”里没有的情况 |
当前,HR需要进行自助分析,查看每个员工的剩余积分有多少。很自然地,HR直接通过“员工ID”字段将2张表进行了物理关联。但由于“员工ID”字段在2张表中都不唯一,直接关联会出现数据膨胀的问题。物理建模的正确做法是将2张表分别按照“员工ID”聚合,再进行关联,需要一定的数据预处理能力。
但如果HR直接使用“关系模型”进行建模,则可以直接使用“员工ID”进行关联,在实际计算中,Quick BI会自动进行数据的聚合处理,保证数据的正确性。
更多计算细节可参考:关系模型如何工作?
分析场景过多时,通过关系模型提升数据集可复用性
当同一个业务分析领域中的数据表数量较多时,使用关系模型可以直接将所有有关系的表拖入逻辑画布中,构造一份完整的关系模型。该模型可直接应用于该领域下的不同分析场景,业务用户直接需要选择所需分析场景的字段进行报表搭建即可。Quick BI会进行自动的处理,仅与当前查询相关的表会纳入计算,其他无关表不参与计算,从而有效避免了数据膨胀的问题。
通过关系模型,就不再需要针对每一个细分分析场景单独构造大宽表,可有效提高数据集的可复用性,减少数据集的数量,便于后期的维护和管理。
此时,数据模型往往会比较复杂,建议由具备一定SQL和数据库基础的用户来操作,并根据数据特性,对“关联关系”、“数据匹配度”进行准确调整,从而提升数据查询的性能,降低复杂建模对性能造成的影响。
举例说明
还是以HR部门的积分获取、积分兑换场景举例:
积分获取表:日期、员工ID、所在部门、参与活动名称、获取积分
积分兑换表:日期、员工ID、所在部门、兑换礼品名称、消耗积分
与上一个例子不同的是,该公司要求中心化的IT团队为所有分析师准备好数据集,因此HR同学向IT提出以下3个场景的数据需求;若IT同学通过物理建模的方式构造数据集,则必须为3个场景准备3个数据集。
场景 | 具体分析描述 | 物理建模处理 |
场景1 | 分析每场活动的参与人数、积分获得情况 | 积分获取表(单表建模) |
场景2 | 分析每种礼品的兑换人数、兑换次数等 | 积分兑换表(单表建模) |
场景3 | 分析每个员工的剩余积分,展示剩余积分排行榜 | 积分获取表和积分兑换表,分别根据“员工ID”聚合后,再进行关联 |
由于“积分获取表”和“积分兑换表”的数据粒度不一致,若直接进行物理关联会导致数据膨胀,无法保证数据正确性。但是在根据“员工ID”字段聚合后,又会丢失“参与活动名称”、“兑换礼品名称”等信息,无法实现“场景1”、“场景2”的分析。因此,在使用物理建模时,IT必须为HR准备3份数据集,以完成3个场景的分析。
但如果IT使用的是关系模型,则直接准备1份数据集即可,Quick BI会根据具体分析的字段自动选择合适的计算方式,以保证数据的正确性。
场景 | 具体分析描述 | 关系建模处理 | 拖入字段 | 关系模型处理 |
场景1 | 分析每场活动的参与人数、积分获得情况 | 关联键:员工ID N:N 部分:全部 | 维度:参与活动名称 度量:员工ID(去重计数)、获取积分(求和) | 单表查询 |
场景2 | 分析每种礼品的兑换人数、兑换次数等 | 维度:兑换礼品名称 度量:员工ID(去重计数)、消耗积分(求和) | 单表查询 | |
场景3 | 分析每个员工的剩余积分,展示剩余积分排行榜 | 维度:员工ID 度量:SUM(获取积分) - SUM(消耗积分) | 聚合后关联 |
更多计算细节可参考:关系模型如何工作?
在何时推荐使用物理模型
对查询性能要求较高时
直连模式
关系模型为避免数据膨胀,会对查询SQL进行特殊的处理,部分场景下会使SQL更加复杂,一定程度上会降低查询性能。
若用户对数据分布情况十分了解,可通过优化“关联关系”和“数据匹配度”来优化查询性能。一般情况下,各个配置的性能表现如下:
关联关系:1:1 > 1:N = N:1 > N:N
数据匹配度:全部:全部 > 全部:部分 = 部分:全部 > 部分:部分
当您不了解数据的具体分布,或者对“关联关系”、“数据匹配度”的概念不熟悉时,请不要修改默认配置,否则有可能会导致数据膨胀、数据丢失等错误。
只有当您对数据分布有清晰的把控,并且确定未来也不会有所变动时,您可以通过调整“关联关系”、“数据匹配度”的配置来优化关系模型的查询性能。
尽管如此,若您具有较好的数据处理能力,并且对查询性能要求非常高时,我们仍然建议您继续使用传统的物理建模方式,从而避免因关系模型复杂逻辑引入的额外计算。
抽取模式
关系模型对抽取加速的支持有限,当前版本仅单逻辑表的数据集支持抽取加速。若您需要对多表关联的数据集执行抽取加速,需要使用物理建模进行多表关联。
后续版本将支持对多逻辑表数据集的抽取加速能力,每个逻辑表将作为一个单独的表抽取至Quick引擎中,查询时在Quick引擎中执行关联。通过这种方式,关系模型可以有效节省加速存储空间,然而关系模型抽取单表的逻辑会导致关联计算在查询时进行,相比于物理建模抽取宽表的模式,查询SQL将会更复杂,性能一定程度上会比物理建模更差。
综上,若您对抽取加速后的性能要求较高,建议仍然使用物理建模的方式。
需要明细级别查询且数据量较大时
当度量来自于多个逻辑表时,QBI将以逻辑表为单位分别进行查询计算,之后再将多个结果关联,取得最终的结果。为保障查询效率和Quick BI整体服务的稳定性,每次查询将有1万行的数据量限制。具体细节可参考关系模型如何工作?
此处的1万行限制可以简单理解为:聚合后的数据限制1万行。比如:关联字段为“区域”,查询维度为“产品类型”,则在对逻辑表进行查询时,会按照“区域”和“产品类型”字段进行聚合,聚合后的结果取前1万行。
受关系模型计算复杂度的影响,无法通过分页的方式取到1万行之后的数据。若您需要执行更加“明细”粒度的数据查询,或者您的查询维度枚举值过多时,关系模型的处理可能会导致数据不完整。该场景下,我们建议您继续使用传统的物理关联进行建模。
需要复杂的“且”、“或”嵌套过滤时
由于关系模型“先聚合,后关联”的处理方式,当来自于多个逻辑表的字段进行复杂的“且”、“或”嵌套过滤时,将会无法计算。产品内在以下功能点均限制了“所选字段必须来自于同一个逻辑表”:
行级权限:包括条件组合授权、用户标签关联授权
仪表板 - 复合查询控件
监控告警 - 告警规则