MaxCompute支持您通过Azkaban实现作业调度,帮助您高效地完成高频数据分析工作。本文以通过MaxCompute客户端执行命令(Command)的方式为例为您介绍如何使用Azkaban调度SQL作业。
背景信息
Azkaban是一套作业调度系统,可以调度Command、Hadoop MapReduce、Hive、Spark、Pig等类型作业,而且支持自定义Plugin,其中最简单而且最常用的是Command类型。更多Azkaban信息,请参见Azkaban。
您需要将待调度作业依赖的源数据、建表及导入数据脚本、查询数据脚本等以文件形式压缩后上传至Azkaban才可进一步实现调度操作。
本文中假设您需要在Azkaban上通过调度功能实现创建表、导入数据、查询数据这一套SQL处理逻辑。基于此场景,您可以设计作业、作业调度流程、各作业对应的作业文件及脚本文件如下。

前提条件
- 已下载并安装MaxCompute客户端。
更多安装并配置MaxCompute客户端操作,请参见安装并配置MaxCompute客户端。
- 已下载并安装Azkaban。
更多下载并安装Azkaban操作,请参见安装Azkaban。
操作流程
步骤一:准备作业相关文件并压缩为ZIP包
- 将上述文件整体压缩为ZIP包。例如压缩为demo1.zip,压缩包内的文件列表如下图所示。

步骤二:将ZIP压缩包上传至Azkaban
- 在新创建的Azkaban项目中上传步骤一中生成的压缩包。
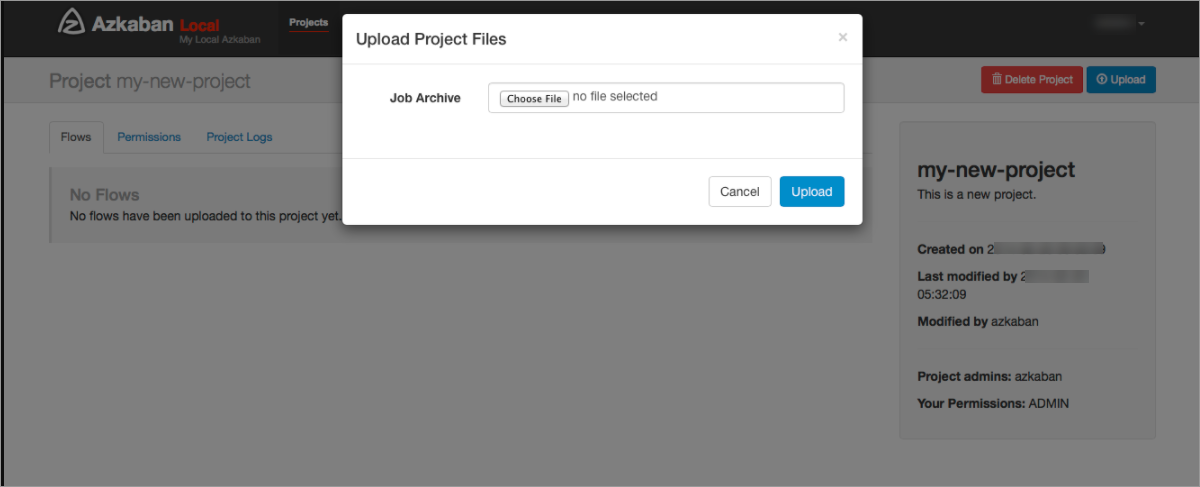 压缩包上传成功后,即可在
压缩包上传成功后,即可在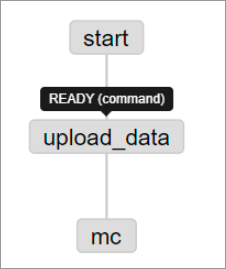
步骤三:运行Flow View
导入调度流程后,您可以在界面右上角单击Schedule/Execute Flow进入运行调度作业对话框,在Flow View页签,您可以单击右下角的Execute启动作业调度。
更多运行Flow View操作,请参见Executing Flow View。
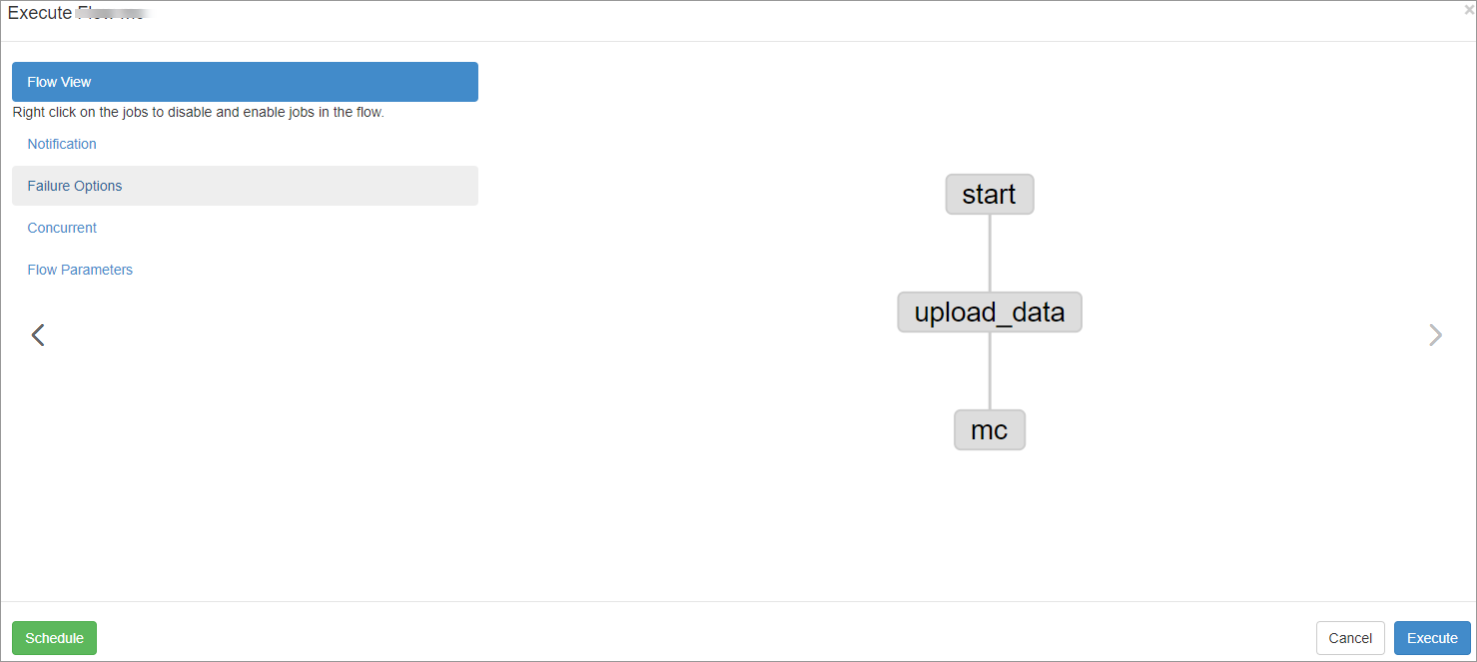
步骤四:查看Flow View运行结果
运行结束后,您可以在Execution界面的Job List页签查看各个作业的运行结果,还可以单击作业右侧的Details查看详细运行信息。
更多查看作业运行结果操作,请参见Execution。
