本文为您介绍分区的相关概念。
分区介绍
分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。分类的标准就是分区字段,可以是一个,也可以是多个。
MaxCompute将分区列的每个值作为一个分区(目录),您可以指定多级分区,即将表的多个字段作为表的分区,分区之间类似多级目录的关系。
分区表的意义在于优化查询。查询表时通过WHERE子句查询指定所需查询的分区,避免全表扫描,提高处理效率,降低计算费用。使用数据时,如果指定需要访问的分区名称,则只会读取相应的分区。合理设计和使用分区,可以提高查询性能、简化数据管理,并支持更灵活的数据访问和操作。分区表的相关介绍请参见分区表概述。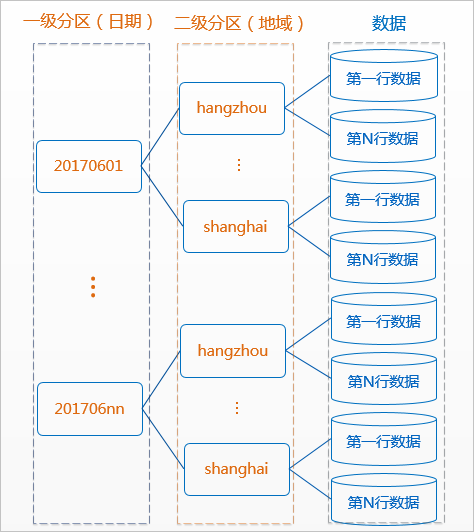
分区操作
对已有表的分区执行添加分区、修改分区值等操作,详情请参见分区操作。
部分对分区操作的SQL运行效率较低,会给您带来较高的费用,例如插入或覆写动态分区数据(DYNAMIC PARTITION)。
分区表
分区表是指拥有分区空间的表,即将表数据按照某个列或多个列进行划分,从而将表中的数据分散存储在不同的物理位置上。分区表的相关介绍及其使用方式,请参见:
对于部分操作MaxCompute的命令,处理分区表和非分区表时语法有差异,详情请参见创建和删除表、修改和查看表和插入或覆写数据(INSERT INTO | INSERT OVERWRITE)。