分布式系统存在高度复杂性的特点,在基础设施、应用逻辑、运维流程等环节都可能存在稳定性风险而导致业务系统的失效。因此构建一个具有容错能力的分布式系统非常重要。本文介绍如何通过ASM设置超时、重试、隔板和熔断机制构建分布式系统的容错能力。
背景信息
容错能力是指系统在部分故障期间,仍然能够继续运行的能力。创建一个可靠的弹性系统会对其中的所有服务提出容错要求。云环境的动态性质要求服务能预见这些失败,并能优雅地响应意外情况。
任何一个服务都有可能存在请求失败的情况,在请求失败的情况下,能够使用适当的后备操作非常重要。一个服务中断可能会引起连锁反应从而导致严重的业务后果,因此构建、运行和测试系统的弹性能力非常必要。ASM提供了超时处理、重试机制、隔板模式和熔断机制容错解决方案,在不修改应用程序任何代码的情况下为应用程序带来了容错能力。
超时处理
原理介绍
当请求上游服务的时候,存在上游服务一直没有响应的现象。您可以设置一个等待时间,到达一个等待时间后,如果上游服务还是没有响应,直接请求失败,不再去等待上游服务。
通过设置超时,可以确保应用程序在后端服务无响应时可以收到错误返回,从而使其能够以适当的回退行为进行处理。超时更改的是发出请求的客户端等待响应的时间,对目标服务的处理行为没有影响。因此这并不意味着请求的操作失败。
解决方案
ASM支持在虚拟服务中为路由设置超时策略来更改超时值,如果Sidecar代理在设置的时间内未收到响应,则该请求将失败。通过这种方式调整超时,所有使用路由的请求都将使用该超时设置。
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
timeout: 5stimeout:设置超时时间,如果在设置的时间内请求的服务没有响应,则直接返回错误结果,不再等待。
重试机制
原理介绍
如果某个服务请求另一个服务失败,例如请求超时、连接超时、服务宕机等错误,您可以通过配置重试机制,重新请求该服务。
请勿频繁地重试或重试过长时间,避免出现级联的系统故障。
解决方案
ASM支持使用虚拟服务定义HTTP请求重试策略。以下示例定义网格中的服务请求httpbin应用时,如果httpbin应用无响应或与httpbin应用建立连接失败,会重新请求httpbin应用3次,每次的请求时间为5秒。
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
retries:
attempts: 3
perTryTimeout: 5s
retryOn: connect-failure,reset您可以在retries结构中配置如下字段,自定义Sidecar对请求进行重试的行为。
字段 | 说明 |
attempts | 一个请求的最大重试次数。如果在配置重试机制的同时,为服务路由配置了超时时间,则实际的重试次数取决于超时时间的设置。例如,如果一次请求未达到最大重试次数,但所有重试花费的总时间已经超过了超时时间,则Sidecar代理会停止请求重试并进行超时返回。 |
perTryTimeout | 每次重试的超时时间,单位为毫秒(ms)、秒(s)、分钟(m)或小时(h)。 |
retryOn | 指定在何种条件下进行重试。多个重试条件需使用英文半角逗号(,)分隔。更多信息,请参见常见的HTTP请求重试条件和常见的gRPC请求重试条件。 |
常见的HTTP请求重试条件如下:
重试条件 | 说明 |
connect-failure | 如果由于与上游服务建立连接失败(连接超时等)导致请求失败,进行重试。 |
refused-stream | 如果上游服务返回REFUSED_STREAM帧来重置流,进行重试。 |
reset | 如果上游服务未响应就发生了连接断开、重置、读取超时事件,进行重试。 |
5xx | 如果上游服务返回任何5XX的响应码(例如500、503等),或上游服务无响应,进行重试。 说明 5XX包含connect-failure和refused-stream的条件。 |
gateway-error | 当上游服务返回502、503或504状态码时,进行重试。 |
envoy-ratelimited | 当请求中存在x-envoy-ratelimited Header时,将进行重试。 |
retriable-4xx | 当上游服务返回409状态码时,进行重试。 |
retriable-status-codes | 当上游服务返回的状态码被判定为可以重试时,进行重试。 说明 您可以直接在retryOn字段中加入合法的状态码,这些状态码将被判定为可以重试的状态码。例如 |
retriable-headers | 当上游服务返回的响应Header中包含可以重试的Header时,进行重试。 说明 您可以在发往上游服务的请求中加入 |
gRPC请求基于HTTP/2,因此您也可以在HTTP请求重试策略的retryOn字段中设定gRPC协议的重试条件。常见的gRPC请求重试条件如下:
重试条件 | 说明 |
cancelled | 如果上游gRPC服务的响应头部中的gRPC状态码为cancelled(1),进行重试。 |
unavailable | 如果上游gRPC服务的响应头部中的gRPC状态码为unavailable(14),进行重试。 |
deadline-exceeded | 如果上游gRPC服务的响应头部中的gRPC状态码为deadline-exceeded(4),进行重试。 |
internal | 如果上游gRPC服务的响应头部中的gRPC状态码为internal(13),进行重试。 |
resource-exhausted | 如果上游gRPC服务的响应头部中的gRPC状态码为resource-exhausted(8),进行重试。 |
配置默认HTTP请求重试策略
在默认情况下,即使不通过虚拟服务定义HTTP请求重试策略,网格内的服务在访问其它HTTP服务时仍然会应用一个默认的HTTP请求重试策略。该默认重试策略的重试次数为2次,没有重试超时时间设置,重试条件默认为connect-failure、refused-stream、unavailable、cancelled和retriable-status-codes。您可以ASM控制台的基本信息页面对默认的HTTP请求重试策略进行配置。配置后,新的HTTP请求重试策略将会覆盖默认的重试策略。
该功能仅支持ASM实例为1.15.3.120及以上版本。关于升级实例的具体操作,请参见升级ASM实例。
登录ASM控制台,在左侧导航栏,选择。
在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择。
在基本信息页面的配置信息区域,单击默认HTTP请求重试策略右侧的编辑。
在默认HTTP请求重试策略对话框,配置相关信息,然后单击确定。
配置项
说明
重试次数
对应上文的attempts。在默认HTTP请求重试策略中,该字段可以配置为0,表示默认禁用HTTP请求重试。
重试超时
对应上文的perTryTimeout。
重试条件
对应上文的retryOn。
隔板模式
原理介绍
隔板模式指限制某个客户端对目标服务的连接数、访问请求数等,避免对一个服务的过量访问,如果超过配置的阈值,则会断开请求。隔板模式有助于隔离用于服务的资源,并避免级联故障。其中,最大连接数和连接超时时间是对TCP和HTTP都有效的通用连接设置,而每个连接最大请求数和最大请求重试次数仅针对HTTP1.1、HTTP2、GRPC协议的连接生效。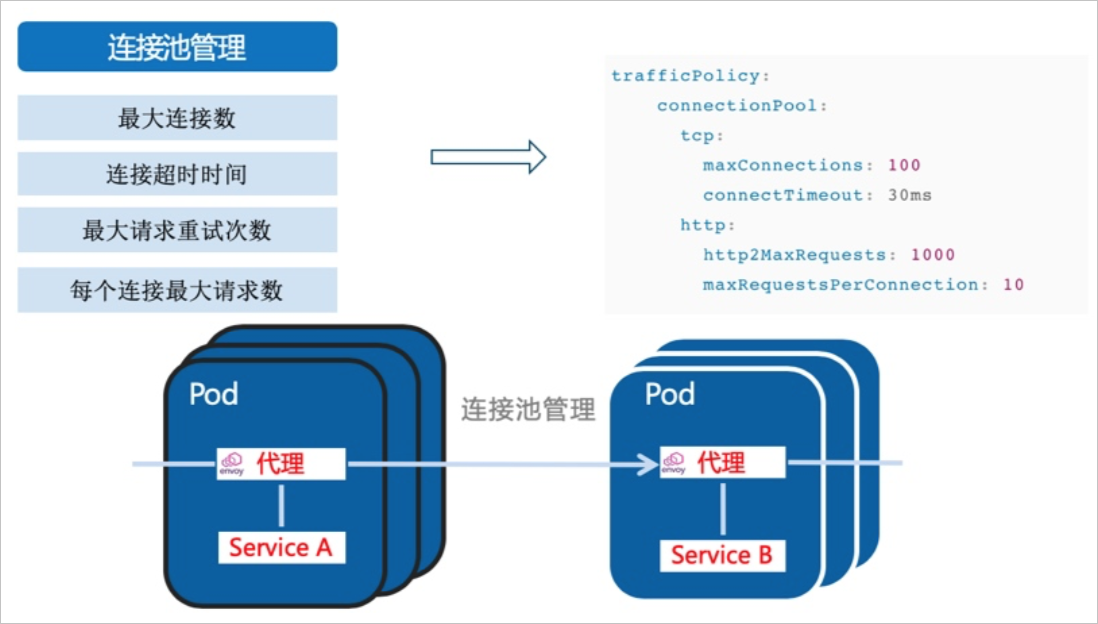
解决方案
ASM支持通过目标规则设置隔板模式,以下目标规则定义了其他服务请求httpbin应用时,最大并发连接数限制为1,每个连接最大请求数为1,最大请求重试次数为1,并且不能在10秒内建立连接的服务会得到503响应。
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
tcp:
connectTimeout: 10s
maxConnections: 1http1MaxPendingRequests:最大请求重试次数。
maxRequestsPerConnection:每个连接最大请求数。
connectTimeout:连接超时时间。
maxConnections:最大连接数。
熔断机制
原理介绍
熔断机制指不会重复向无响应的服务发出请求,而是观察在给定时间段内发生的故障数。如果错误率超过阈值,则熔断器将断开请求,并且所有后续请求都将失败,直到熔断器被关闭为止。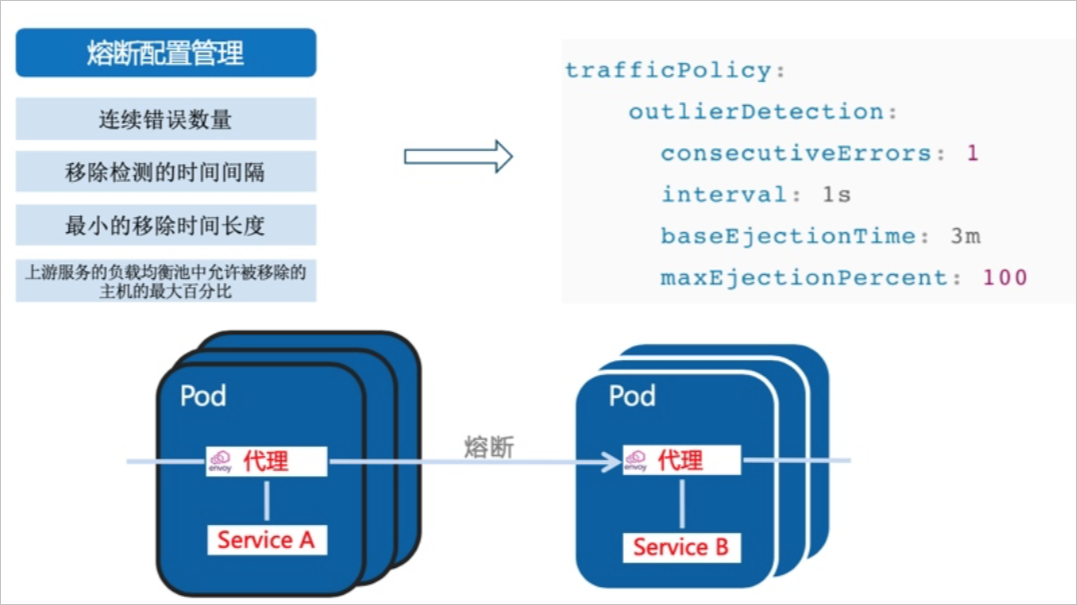
解决方案
ASM支持通过目标规则设置主机级熔断机制,以下目标规则定义了如果其他服务请求httpbin应用时,在5秒内连续3次访问失败,则将在5分钟内断开请求。
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
outlierDetection:
consecutiveErrors: 3
interval: 5s
baseEjectionTime: 5m
maxEjectionPercent: 100consecutiveErrors:连续错误数量。
interval:驱逐检测的时间间隔。
baseEjectionTime:最小的驱逐时间长度。
maxEjectionPercent:负载均衡池中允许被驱逐的主机的最大百分比。
查看主机级熔断相关指标
和ASMCircuitBreaker不同,主机级别的熔断机制下,客户端的Sidecar代理会单独检测每个上游服务主机的错误率,并在主机连续发生错误时将主机从服务的负载均衡池中驱逐。
主机级熔断可以产生一系列相关指标,以帮助判断熔断是否发生,部分指标的说明如下:
指标 | 指标类型 | 描述 |
envoy_cluster_outlier_detection_ejections_active | Gauge | 当前被驱逐的主机的数量。 |
envoy_cluster_outlier_detection_ejections_enforced_total | Counter | 发生主机被驱逐事件的次数。 |
envoy_cluster_outlier_detection_ejections_overflow | Counter | 因超过最大驱逐百分比而放弃驱逐主机的次数。 |
ejections_detected_consecutive_5xx | Counter | 检测到主机连续产生5xx错误的次数。 |
您可以通过配置Sidecar代理的proxyStatsMatcher使Sidecar代理上报相关指标,然后使用Prometheus采集并查看熔断相关指标。
通过proxyStatsMatcher配置Sidecar代理上报熔断指标。在配置proxyStatsMatcher时,选中正则匹配,配置为
.*outlier_detection.*。具体操作,请参见proxyStatsMatcher。重新部署httpbin无状态工作负载。具体操作,请参见重新部署工作负载。
配置主机级熔断指标采集及告警
配置完成上报主机级别的熔断指标后,您可以配置采集相关指标到Prometheus,并基于关键指标配置告警规则,实现熔断发生时的及时告警。以下以可观测监控Prometheus版为例说明如何配置主机级熔断指标采集和告警。
在可观测监控Prometheus版中,为数据面集群接入阿里云ASM组件或升级至最新版,以保证可观测监控Prometheus版可以采集到暴露的熔断指标。有关更新接入组件的具体操作,参考接入组件管理。(如果参考集成自建Prometheus实现网格监控配置了通过自建Prometheus采集服务网格指标,则无需操作。)
创建针对主机级熔断的告警规则。具体操作,请参见通过自定义PromQL创建Prometheus告警规则。配置告警规则的关键参数的填写示例如下,其余参数可参考上述文档根据自身需求填写。
参数
示例
说明
自定义PromQL语句
(sum (envoy_cluster_outlier_detection_ejections_active) by (cluster_name, namespace)) > 0
示例通过查询envoy_cluster_outlier_detection_ejections_active指标来判断当前集群中是否有正在被驱逐的主机,并将查询结果按照服务所在命名空间和服务名称进行分组。
告警内容
触发级熔断,有工作负载连续发生错误,从服务负载均衡池中被驱逐!命名空间:{{$labels.namespace}},驱逐发生的服务:{{$labels.cluster_name}}。驱逐数量:{{ $value }}
示例的告警信息展示了触发熔断的服务所在命名空间以及服务名称,以及当前该服务被驱逐的数量。