日志服务提供定时SQL功能,用于定时分析数据、存储聚合数据、投影与过滤数据。本文介绍定时SQL功能的背景信息、功能简介、基本概念、调度与执行场景、使用建议等信息。
背景信息
基于时间的数据(日志、指标)在日积月累后的数量是惊人的。例如每天产生1000万条数据,则一年为36亿条数据。一方面,长时间的数据存储需要巨大的存储空间,而通过减少存储周期的方式减少存储空间,虽然降低了存储成本,但也丢失了有价值的数据。另一方面,大量的数据将造成分析上的性能压力。
数据的存储和分析具备以下特征:
大部分时序数据具有时效性特征。历史数据可以为分钟或小时级别的精度,而新产生的数据需要更高的精度。
数据使用者(例如数据运营人员、数据科学家)需要存储全量的数据以备分析。
在数据分析阶段,需同时兼顾全量数据和快速查询响应。
针对上述特征,日志服务推出定时SQL功能,用于将高精度的历史数据压缩为低精度数据后,长期存储。使用定时SQL功能后,您可以根据业务需求为源库设置较低的存储周期(例如15天),将目标库的存储周期设置为永久保存。实现长时间范围数据的低延迟分析、低成本存储。
功能简介
定时SQL支持标准SQL92语法、日志服务查询和分析语法,按照调度规则周期性执行,并将运行结果写入到目标库(Logstore或Metricstore)中。
定时分析数据:根据业务需求设置SQL语句或查询分析语句,定时执行数据分析,并将分析结果存储到目标库中。
全局聚合:对全量、细粒度的数据进行聚合存储,汇总为存储大小、精度适合的数据,相当于一定程度的有损压缩数据。例如:
按照秒级别对36亿条数据进行聚合存储,存储结果为3150万条数据,存储大小为全量数据的0.875%。
按照分钟级别对36亿条数据进行聚合存储,存储结果为52.5万条数据,存储大小为全量数据的0.015%。

投影与过滤:对原始数据的字段进行筛选,按照一定条件过滤数据并存储到目标Logstore中。
该功能还可以通过数据加工实现,数据加工的DSL语法比SQL语法具备更强的ETL表达能力。更多信息,请参见加工原理。
基本概念
任务:一个定时SQL任务配置包括计算配置、调度配置等信息。
实例:一个定时SQL任务按照调度配置按时生成实例。每一个实例对原始数据进行SQL计算并将计算结果写入目标库。
实例ID:实例的唯一标识。
创建时间:实例的创建时间。一般是按照您配置的调度规则生成,在补运行或追赶延迟时会立即生成实例。
执行时间:实例开始执行的时间。如果重试任务,则表示最后一次开始执行的时间。
结束时间:实例执行结束的时间。如果重试任务,则表示最后一次执行结束的时间。
调度时间:由调度规则决定,不会受到上一个实例执行超时、延迟、补运行等情况的影响。
大部分场景下,连续生成的实例的调度时间是连续的,可处理完整的数据集。
SQL时间窗口:定时SQL任务运行时,日志服务仅分析该时间范围内的数据。SQL时间窗口基于调度时间计算而得,左闭右开格式,且与实例的创建时间、执行时间无关。例如调度时间为2021/01/01 10:00:00,SQL时间窗口的表达式为[@m - 10m, @m),则实际的SQL时间窗口为[2021/01/01 09:50:00, 2021/01/01 10:00:00)。
执行状态:定时SQL执行实例的执行状态,包括运行中(RUNNING)、重试中(STARTING)、成功(SUCCEEDED)、失败(FAILED)。
延迟执行:定时SQL任务中的配置参数,表示在实例的调度时间点上,往后延迟N秒才真正开始执行实例。主要用于避免数据延迟等情况导致计算结果不精确问题。如果不需要使用延迟时间来保证结果正确性,您可以将延迟执行设置为0秒。
例如,您设置调度间隔为每小时、延迟执行为30秒,那么一天生成24个实例,其中某实例的调度时间为2021/4/6 12:00:00,执行时间为2021/4/6 12:00:30。
调度与执行场景
一个任务可生成多个实例,无论是正常被调度还是您触发异常实例重试的情况,同时只有一个实例处于运行中,不存在多个实例并发执行的情况。主要的调度与执行场景如下:
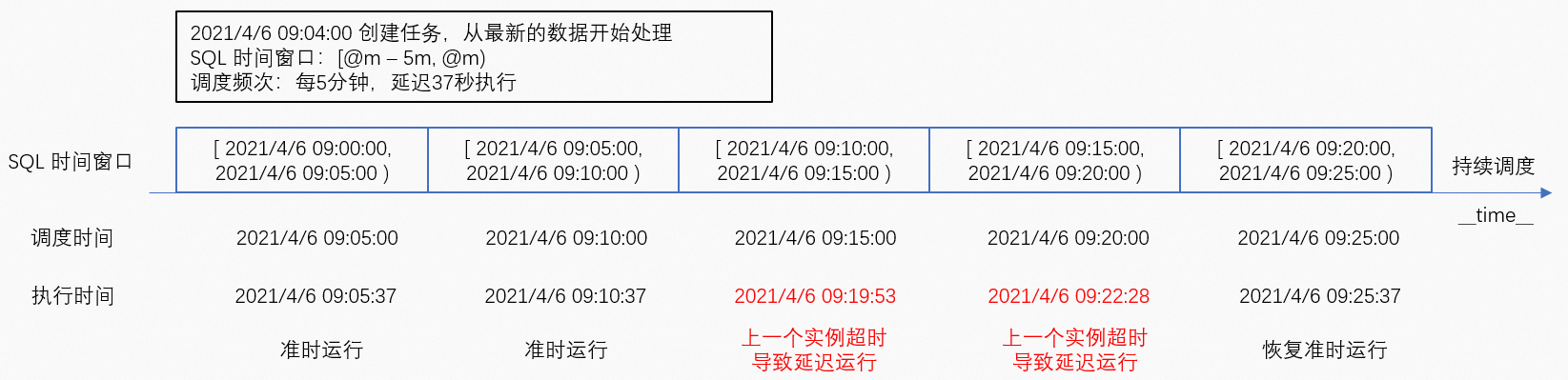
场景一:实例延迟执行
无论实例是否延迟执行,实例的调度时间都是根据调度规则预先生成的。虽然前面的实例发生延迟时,可能导致后面的实例也延迟执行,但通过追赶执行进度,可逐渐减少延迟,直到恢复准时运行。
场景二:从某个历史时间点开始执行定时SQL任务
在当前时间点创建定时SQL任务后,按照调度规则对历史数据进行处理,从调度的开始时间创建补运行的实例,补运行的实例依次执行直到追上数据处理进度后,再按照预定计划执行新实例。

场景三:固定时间内执行定时SQL任务
如果需要对指定时间段的日志做调度,则可设置调度的时间范围。如果设置了调度的结束时间,则最后一个实例(调度时间小于调度结束时间)执行完成后,不再产生新的实例。

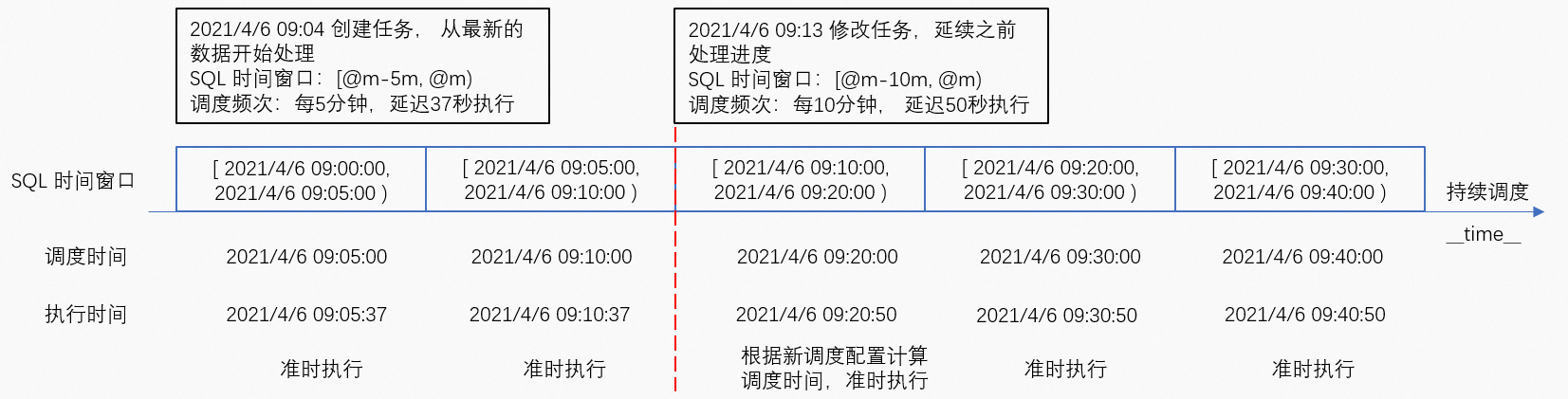
场景四:修改调度配置对生成实例的影响
修改调度配置后,下一个实例按照新配置生成。一般建议同步修改SQL时间窗口、调度频率等配置,使得实例之间的SQL时间范围可以连续。
场景五:重试失败的实例
正常情况下,一个定时SQL任务按照调度时间的递增顺序生成执行实例。如果实例执行失败(例如权限不足、源库不存在、目标库不存在、SQL语法不合法),系统支持自动重试,当重试次数超过您配置的最大重试次数或重试时间超过您配置的最大运行时间时,重试结束,该实例状态被置为失败,然后系统继续执行下一个实例。
您可以对失败的实例设置告警通知并进行手动重试。您可以对最近7天内创建的实例进行查看、重试操作。调度执行完成后,系统会根据实际执行情况变更实例状态为成功或失败。如何重试,请参见重试定时SQL任务实例。
使用建议
使用定时SQL时,建议根据业务情况,同时兼顾数据实时性和准确性。
考虑数据上传日志服务存在延迟情况,您可以结合数据采集延迟以及业务能够容忍的最大结果可见延迟,设置执行延迟和SQL时间窗口(结束时间往前一点),避免实例执行时SQL时间窗口内的数据未全部到达。
建议SQL时间窗口按分钟对齐(例如整分钟、整小时),以保证上传局部乱序数据时的数据准确度。