为了满足特定业务需求,您可以在DataWorks中创建EMR Shell节点。通过编辑自定义Shell脚本,对数据处理、调用Hadoop组件、操作文件等高级功能进行使用。本文介绍了在DataWorks里配置和使用EMR Shell节点,以便您编辑和运行Shell任务。
前提条件
开始进行节点开发前,若您需要定制组件环境,此时即可基于官方镜像
dataworks_emr_base_task_pod创建自定义镜像,并在数据开发中使用镜像。例如:在创建自定义镜像时替换Spark Jar包或是依赖特定的
库、文件或jar包。已创建阿里云EMR集群,并注册EMR集群至DataWorks。操作详情请参见旧版数据开发:绑定EMR计算资源。
(可选,RAM账号需要)进行任务开发的RAM账号已被添加至对应工作空间中,并具有开发或空间管理员(权限较大,谨慎添加)角色权限,添加成员的操作详情请参见为工作空间添加空间成员。
已购买Serverless资源组并完成资源组配置,包括绑定工作空间、网络配置等,详情请参见新增和使用Serverless资源组。
数据开发(DataStudio)中已创建业务流程。
数据开发(DataStudio)基于业务流程对不同开发引擎进行具体开发操作,所以您创建节点前需要先新建业务流程,操作详情请参见创建业务流程。
在DataWorks资源组本地运行Python脚本时,代码需要调用第三方包,需要根据任务使用的资源组不同,采用不同方式在资源组上准备第三方包环境:
使用限制
仅支持使用Serverless资源组(推荐)或独享调度资源组运行该类型任务,若在数据开发时需使用镜像,则必须使用Serverless资源组。
DataLake或自定义集群若要在DataWorks管理元数据,需先在集群侧配置EMR-HOOK。若未配置,则无法在DataWorks中实时展示元数据、生成审计日志、展示血缘关系、开展EMR相关治理任务。配置EMR-HOOK,详情请参见配置Hive的EMR-HOOK。
spark-submit方式提交的任务,deploy-mode推荐使用cluster模式,不建议使用client模式。
EMR Shell节点是运行在DataWorks调度资源组,而非EMR集群的,您可以使用一些EMR组件命令,但无法直接读取EMR上资源情况。如果要引用资源,则需要先上传DataWorks资源。详情请参见上传EMR资源。
EMR Shell节点不支持运行Python文件,请使用Shell节点运行。
一、创建EMR Shell节点
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
新建EMR Shell节点。
右键单击目标业务流程,选择。
说明您也可以鼠标悬停至新建,选择。
在新建节点对话框中,输入名称,并选择引擎实例、节点类型及路径。单击确认,进入EMR Shell节点编辑页面。
说明节点名称支持大小写字母、中文、数字、下划线(_)和小数点(.)。
二、开发EMR Shell任务
在EMR Shell节点编辑页面双击已创建的节点,您可以根据不同场景需求选择适合您的操作方案:
(推荐)先从本地上传资源至DataStudio,再引用资源,详情请参见方案一:先上传资源后引用EMR JAR资源。
使用OSS REF方式引用OSS资源,详情请参见方案二:直接引用OSS资源。
方案一:先上传资源后引用EMR JAR资源
DataWorks也支持您从本地先上传资源至DataStudio,再引用资源。如果您使用的是DataLake(新版数据湖)集群,则可通过如下步骤引用EMR JAR资源,若EMR Shell节点依赖的资源较大,则无法通过DataWorks页面上传。您可将资源存放至HDFS上,然后在代码中进行引用。
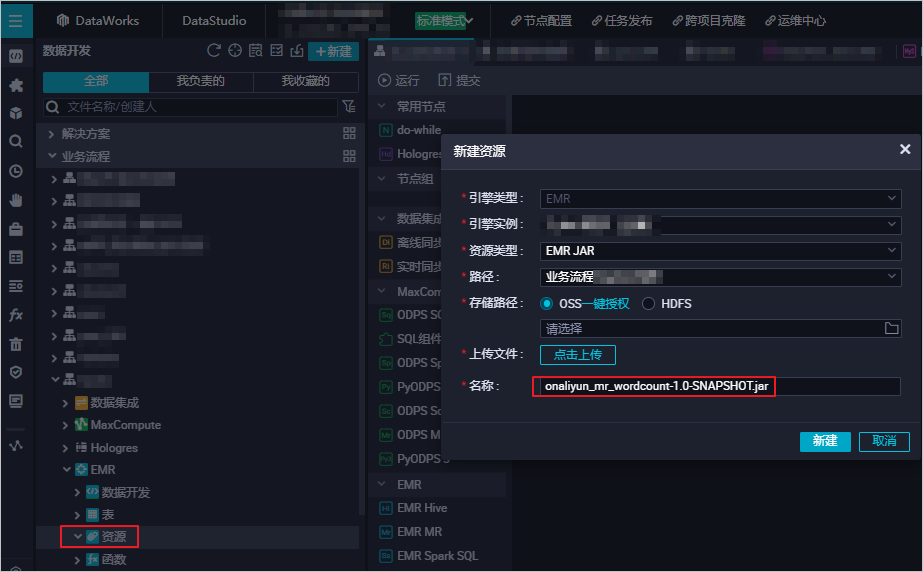
创建EMR JAR资源。
创建EMR JAR资源,详情请参见创建和使用EMR资源。示例将本文《准备初始数据及JAR资源包》中生成的JAR包存储在JAR资源的存放目录emr/jars下。首次使用需要选择一键授权,然后单击点击上传按钮,上传JAR资源。
引用EMR JAR资源。
打开创建的EMR Shell节点,停留在代码编辑页面。
在节点下,找到待引用资源(示例为
onaliyun_mr_wordcount-1.0-SNAPSHOT.jar),右键选择引用资源。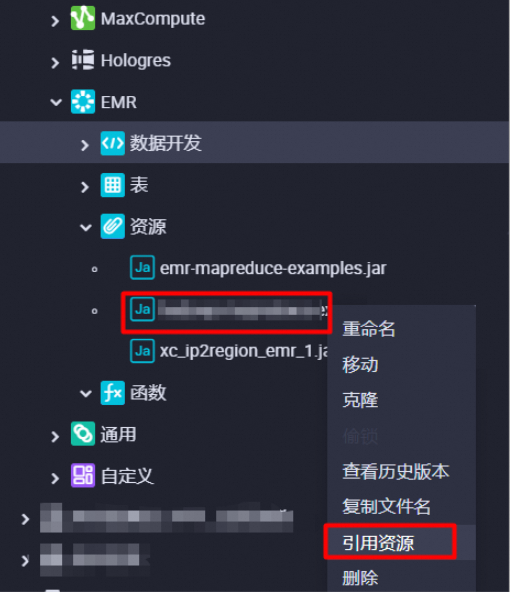
选择引用后,当EMR Shell节点的代码编辑页面显示
##@resource_reference{""}格式的语句,表明已成功引用代码资源。此时,需要执行下述命令。如下命令涉及的资源包、Bucket名称、路径信息等为本文示例的内容,使用时,您需要替换为实际使用的信息。##@resource_reference{"onaliyun_mr_wordcount-1.0-SNAPSHOT.jar"} onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs说明EMR Shell节点编辑代码时不支持注释语句。
方案二:直接引用OSS资源
配置EMR Shell调度参数
在节点编辑区域开发任务代码,您可在代码中使用${变量名}的方式定义变量,并在节点编辑页面右侧导航栏的调度配置>调度参数中为该变量赋值。实现调度场景下代码的动态传参,调度参数使用详情,请参考调度参数支持的格式,示例如下。
DD=`date`;
echo "hello world, $DD"
##可以结合调度参数使用
echo ${var};如果您使用的是DataLake(新版数据湖)集群,则还支持如下命令行。
Shell命令:
/usr/bin及/bin下的Shell命令。例如,ls、echo等。Yarn组件:hadoop、hdfs、yarn。
Spark组件:spark-submit。
Sqoop组件:sqoop-export、sqoop-import、sqoop-import-all-tables等。
使用该组件时,您需要在RDS白名单中添加资源组的IP信息。
执行EMR Shell任务
三、配置节点调度
如您需要周期性执行创建的节点任务,可单击节点编辑页面右侧的调度配置,根据业务需求配置该节点任务的调度信息。配置详情请参见任务调度属性配置概述。
四、发布节点任务
节点任务配置完成后,需执行提交发布操作,提交发布后节点即会根据调度配置内容进行周期性运行。
单击工具栏中的
 图标,保存节点。
图标,保存节点。单击工具栏中的
 图标,提交节点任务。
图标,提交节点任务。提交时需在提交对话框中输入变更描述,并根据需要选择是否在节点提交后执行代码评审。
说明您需设置节点的重跑属性和依赖的上游节点,才可提交节点。
代码评审可对任务的代码质量进行把控,防止由于任务代码有误,未经审核直接发布上线后出现任务报错。如进行代码评审,则提交的节点代码必须通过评审人员的审核才可发布,详情请参见代码评审。
如您使用的是标准模式的工作空间,任务提交成功后,需单击节点编辑页面右上方的发布,将该任务发布至生产环境执行,操作请参见发布任务。
后续步骤
任务提交发布后,会基于节点的配置周期性运行,您可单击节点编辑界面右上角的运维,进入运维中心查看周期任务的调度运行情况。详情请参见管理周期任务。
相关文档
了解如何在EMR Shell节点使用Python 2或Python 3命令运行Python脚本:详情请参见Shell类型节点运行Python脚本。
了解如何在EMR Shell节点使用OSSUtils工具:详情请参见Shell类型节点使用ossutil工具。