向量检索插件是阿里云Elasticsearch团队自主开发的向量检索引擎插件,基于阿里巴巴达摩院proxima向量检索库实现,能够帮助您快速实现图像搜索、视频指纹采样、人脸识别、语音识别和商品推荐等向量检索场景的需求。本文介绍如何使用向量检索插件。
此文档仅供存量客户参考使用,Elasticsearch目前只有非常老的存量实例在用这个knn的插件。
后面新增的向量场景业务,建议购买8.15及以上的版本实例,直接使用Elasticsearch引擎内核中的原生向量检索能力。
背景信息
应用场景
阿里云Elasticsearch向量检索引擎已成熟应用于拍立淘、阿里云图像搜索服务、趣头条视频指纹采样、猜您喜欢、搜索个性化、CrossMedia搜索等大规模生产应用场景。
原理
阿里云Elasticsearch向量检索功能基于Elasticsearch插件扩展机制实现,能够完全兼容原生Elasticsearch版本,您无需额外的学习成本即可使用向量检索引擎。向量索引除了支持实时增量写入、近实时(Near Real Time,简称NRT)搜索查询,还具备了所有原生Elasticsearch的分布式能力,同时支持多副本、错误恢复等功能。
说明阿里云Elasticsearch向量检索插件不支持通过OSS快照、DataWorks等方式进行数据迁移,建议使用Logstash方式。
算法说明
在算法上,目前向量检索引擎已经支持了hnsw算法以及linear算法,适用于单机数据量小(全内存)的业务场景。两种算法性能对比如下。
表 1. hnsw算法和linear算法性能对比
表格中为阿里云Elasticsearch 6.7.0版本环境实测数据,测试环境配置如下:
机器配置:数据节点16核64 GB*2 + 100 GB SSD云盘。
数据集:sift128维float向量。
数据总量:2千万条。
索引配置:全部采用默认参数。
性能指标
hnsw
linear
top10召回率
98.6%
100%
top50召回率
97.9%
100%
top100召回率
97.4%
100%
延迟(p99)
0.093s
0.934s
延迟(p90)
0.018s
0.305s
说明表中的p表示百分比,例如延迟(p99)表示99%的查询能在多少秒返回。
前提条件
安装向量检索插件(英文名称为aliyun-knn)。插件的默认安装情况与阿里云Elasticsearch的实例版本和内核版本相关,具体说明如下。
Elasticsearch版本
内核版本
插件安装情况说明
6.7.0
1.2.0以下
需要在插件配置页面手动安装向量检索插件,安装方法请参见安装或卸载系统默认插件。
不支持使用script检索和索引预热等功能配置。如有需求,建议使用有AliES内核版本的实例,详细信息请参见内核版本发布记录。
创建向量索引时仅支持默认的
SquaredEuclidean,不支持通过distance_method参数指定具体的距离度量函数。
6.8
无
7.4
无
7.7
无
6.7.0
1.2.0及以上
向量检索插件默认集成在apack插件中(默认已安装),安装或卸载向量检索插件都需对apack插件进行操作。详细信息请参见使用apack插件的物理复制功能。
支持使用script检索、索引预热、扩展函数等扩展功能,但需要将内核版本升级至1.3.0及以上,具体操作请参见升级版本。
如果创建向量索引时遇到解析mapping报错,请升级内核版本至1.3.0及以上后再重试。
7.10.0
1.4.0及以上
向量检索插件默认集成在apack插件中(默认已安装),安装或卸载向量检索插件都需对apack插件进行操作。详细信息请参见使用apack插件的物理复制功能。
内核小版本大于等于1.4.0时,apack插件版本已为最新版本,无需更新。使用时,可通过GET _cat/plugins?v命令获取插件版本。
其他版本
无
不支持向量检索功能。
说明内核版本不等同于apack插件版本,使用时可通过GET _cat/plugins?v命令获取apack插件版本。
完成索引规划。
算法
适用场景
是否全内存
其他
hnsw
单机数据量小。
对延迟要求高。
对召回率要求高。
是
hnsw是基于“邻居的邻居可能是邻居”的核心思想,它在距离衡量算法上有一定的限制,需要满足三角形不等式,即三角形的两边之和大于第三边。例如,对于内积向量空间,由于不满足三角形不等式,需要转化为欧式空间或球面空间,才能使用hnsw检索方法。
建议写入结束后,在业务低峰期定期forceMerge,有助于降低查询延迟。
linear
暴力检索。
召回率100%。
延迟与数据量成正比。
效果对照。
是
无 。
完成集群规划。
规划项
说明
数据节点规格(必须)
16核64 GB及以上。
说明使用aliyun-knn插件构建索引时,需要消耗大量的计算资源。由于小规格集群极易达到瓶颈,严重时会影响集群稳定性,因此建议您使用16核64 GB及以上规格的集群。
节点类型
集群中需要有独立的专有主节点。
集群堆外内存
大于集群总向量数据*2。
示例: 索引中只有一个960维float字段,索引总文档数是400,float类型数据占4字节内存,此索引向量数据内存占用=960*400*4=1.5MB,内存空间中堆外内存>1.5*2=3MB。
说明如果存在forcemerge操作,考虑到新老数据会出现同时占用内存的情况,请在上面公式的基础上再乘以2。
64GB及以上内存规格,堆外大小≈总内存-32G。
写入限流
向量索引的构建属于CPU密集型任务,建议业务控制写入流量不要太高。以16核64 GB的数据节点为例,建议单节点写入峰值控制在5000tps以内。
同时,由于在向量索引的查询过程中,会把索引文件全部加载到系统内存,因此建议在业务查询期间,不要同时进行大批量的写入,避免因节点内存紧张导致分片重启的情况。
说明以上均为预估,以业务实际的应用情况为准,建议提前进行压测,并提供充足的内存空间。
使用限制
开启共享弹性存储功能的6.7版本实例不支持向量检索插件。
在安装向量检索插件前,需要确保阿里云Elasticsearch实例的数据节点规格为16核64 GB及以上。如果不满足,请先将数据节点规格升级至16核64 GB及以上,详细信息请参见升配集群。
使用向量检索插件的场景中,部分AliES内核的增强功能将不能使用。以物理复制功能为例,如果您使用了物理复制功能,使用向量检索插件前,需要先关闭该功能,具体操作请参见使用apack插件的物理复制功能。
阿里云Elasticsearch向量检索插件不支持通过OSS快照、DataWorks等方式进行数据迁移,建议使用Logstash方式。
创建向量索引
登录目标阿里云Elasticsearch实例的Kibana控制台,根据页面提示进入Kibana主页。
登录Kibana控制台的具体操作,请参见登录Kibana控制台。
说明本文以阿里云Elasticsearch 6.7.0版本为例,其他版本操作可能略有差别,请以实际界面为准。
在左侧导航栏,单击Dev Tools。
在Console中执行如下命令,创建向量索引结构。
PUT test { "settings": { "index.codec": "proxima", "index.vector.algorithm": "hnsw" }, "mappings": { "_doc": { "properties": { "feature": { "type": "proxima_vector", "dim": 2, "vector_type": "float", "distance_method": "SquaredEuclidean" } } } } }说明在向量索引结构的基础上,支持添加Elasticsearch支持的其他字段类型。
如果创建向量索引时遇到解析mapping报错:
"type": "mapper_parsing_exception", "reason": "Mapping definition for [feature] has unsupported parameters: [distance_method : SquaredEuclidean],请及时升级内核版本至最新后重试。
类型
参数
默认值
含义
setting
index.codec
proxima
是否需要底层构建proxima knn索引,可选值如下:
proxima(推荐):底层构建proxima knn索引,支持向量检索。
null:创建索引的时候,底层不构建proxima knn索引,只构建正排索引。此时,proxima_vector类型字段仅支持script检索,不支持hnsw或linear检索。
说明当数据量较大,且对查询延迟要求不高的场景,可以把该项配置去掉或设置为null,此时可使用script检索方式进行knn向量查询。支持script检索方式的版本:实例版本为6.7.0且apack插件版本≥1.2.1或实例版本为7.10.0且apack插件版本≥1.4.0。
index.vector.algorithm
hnsw
指定向量检索算法,可选值如下:
hnsw:hnsw算法。
linear:linear算法。
index.vector.general.builder.offline_mode
false
指定knn索引构建是否使用离线优化模式,可选值如下:
false: 不使用离线优化模式。
true: 使用离线优化模式,写入构建的segment碎片将会大幅度减少,提升整体写入吞吐能力。
说明开启离线优化模式需要保证:实例版本为6.7.0且apack插件版本≥1.2.1或实例版本为7.10.0且apack插件版本≥1.4.0;开启离线模式构建的索引,不支持使用script检索数据。
当一次性批量导入全量数据时,建议开启离线优化模式。
mapping
type
proxima_vector
向量字段类型。例如:将feature字段指定为proxima_vector,说明feature为向量字段。
dim
2
向量维度,必填,仅支持1~2048维。
vector_type
float
向量数据类型,可选值如下:
float:浮点型。
short:短整型。
binary:二进制类型。
其中binary类型为二进制类型,向量数据需要用无符号的32位十进制(uint32)数组表示,且dim必须为32的整数倍。
例如:业务数据为64位二进制1000100100100101111000001001111101000011010010011010011010000100,那么写入vector为[-1994006369, 1128900228]。
说明实例版本为6.7.0且apack插件版本≥1.2.1或实例版本为7.10.0且apack插件版本≥1.4.0,向量数据类型支持以上三种类型。否则,向量数据类型仅支持float类型。
distance_method
SquaredEuclidean(未开方)
距离度量函数,可选值如下:
SquaredEuclidean:欧氏距离(未开方)。
InnerProduct:内积。
Cosine:余弦相似度。
Hamming:汉明距离(仅支持binary类型)。
说明实例版本为6.7.0且apack插件版本≥1.2.1或实例版本为7.10.0且apack插件版本≥1.4.0时,支持以上四种距离度量函数。其他版本(6.8,7.4和7.7)实例创建向量时仅支持使用默认的SquaredEuclidean,不支持通过
distance_method参数指定其他距离度量函数。距离度量函数详细说明请参见距离度量函数。
因Hamming函数实现比较特殊,索引使用hnsw或linear时,不支持标准的knn查询方式,仅支持script方式,且查询语句兼容script_score。在不同的场景下,您需要根据具体业务测试查询语句的可用性。
执行如下命令,添加文档。
POST test/_doc { "feature": [1.0, 2.0] }说明除binary类型外,其他类型数组长度必须与dim保持一致,而binary类型的向量数据需要转换成无符号的32位十进制(uint32)数组表示,且dim必须为32的整数倍。
向量查询
标准检索
执行如下命令,对文档进行标准检索。
GET test/_search { "query": { "hnsw": { "feature": { "vector": [1.5, 2.5], "size": 10 } } } }常用参数说明如下。
参数
说明
hnsw
向量查询算法,与创建索引时指定的algorithm一致。
vector
查询的向量数据,数组长度必须与创建索引时,mapping指定的dim保持一致。
size
指定召回的文档数。
说明向量检索中的size参数与Elasticsearch自带的size参数存在区别,前者控制向量检索插件knn召回的文档数,后者控制整个查询的召回文档数。使用时,系统会先通过向量检索中的size参数召回topN的文档,然后再由Elasticsearch自带的size参数召回整个查询的文档,最终返回结果。
建议向量检索中的size参数值和Elasticsearch自带的size参数值(默认值为10)保持一致。
说明knn向量检索还提供高级查询参数,详细信息请参见高阶参数。
script检索
script向量检索仅支持在script_score方式下使用。例如使用script_score对查询返回的每个文档进行打分,该分数等于
1/(1+l2Squared(params.queryVector, doc['feature']))。示例命令如下。GET test/_search { "query": { "match_all": {} }, "rescore": { "query": { "rescore_query": { "function_score": { "functions": [{ "script_score": { "script": { "source": "1/(1+l2Squared(params.queryVector, doc['feature'])) ", "params": { "queryVector": [2.0, 2.0] } } } }] } } } } }knn向量script检索不支持X-Pack提供的函数,仅支持以下函数:
函数
说明
l2Squared(float[] queryVector, DocValues docValues)欧式算法函数。
hamming(float[] queryVector, DocValues docValues)汉明距离函数。
cosineSimilarity(float[] queryVector, DocValues docValues)cosine(float[] queryVector, DocValues docValues)
余弦相似度函数。
说明阿里云Elasticsearch 6.7版本请使用
cosineSimilarity(float[] queryVector, DocValues docValues)函数,7.10版本请使用cosine(float[] queryVector, DocValues docValues)函数。说明使用script检索功能,需要确保:实例版本为6.7.0且apack插件版本≥1.2.1版本或实例版本为7.10.0版本且apack插件版本≥1.4.0。您可以通过GET /_cat/plugins?v命令获取apack插件版本,如果apack插件版本不满足要求,可提交工单,由阿里云工程师帮您升级。
函数参数:
float[] queryVector:用于表示查询向量,可传入形参和实参。
DocValues docValues:用于指定文档向量。
script向量检索不支持处于离线模式(
index.vector.builder.offlineMode = true)下构建的索引。
索引预热(降低延迟)
knn索引由于需要进行全内存检索,所以在索引冷加载时会出现查询延迟较高的情况。因此knn插件提供了索引预热功能,可以在knn索引提供检索服务之前,提前对knn索引进行预热,加载到本地内存,从而大大降低冷启动时的查询延迟。
所有向量索引实现预热。
POST _vector/warmup特定向量索引实现预热能力。
POST _vector/{indexName}/warmup
说明使用索引预热功能,需要确保:实例版本为6.7.0且apack插件版本≥1.2.1或实例版本为7.10.0且apack插件版本≥1.4.0。您可以通过GET _cat/plugins?v命令获取apack插件版本,如果apack插件版本不满足要求,可提交工单,由阿里云工程师帮您升级。
如果集群中向量索引比较多且数据量比较大,业务只需要对特定索引实现向量检索,建议只对特定向量使用预热能力,提升内存检索能力。
向量打分
向量检索拥有统一的打分公式,而打分机制主要依赖距离度量函数。不同的距离函数直接性的影响检索排序。
打分公式:
分数= 1/(向量距离函数+1)
向量打分机制默认使用未开方的欧式距离。
在实际应用中,您可以通过查询分数反推向量间的距离,优化向量数据,提升打分。
距离度量函数
不同的距离度量函数对应不同的打分机制,下面是aliyun-knn插件支持的度量算法:
距离函数 | 定义 | 打分公式 | 应用场景 | 示例 |
SquaredEuclidean欧氏距离(未开方) | 欧几里得度量(euclidean metric)也称欧氏距离,是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。 | 以两个n维向量A = [A1, A2,…, An]和B= [B1, B2,…, Bn]为例:
说明 向量打分默认使用未开方的欧式距离计算。 | 欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,例如使用用户行为指标分析用户价值的相似度或差异。 | 例如:两个二维向量[0,0]和[1,2],未开方欧式距离= (1-0)² + (2-0)² = 5。 |
Cosine余弦相似度 | 余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角的余弦值来评估它们之间的相似性。 | 以两个n维向量A = [A1, A2,…, An]和B= [B1, B2,…, Bn]为例:
| 余弦相似度更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦相似度对绝对数值不敏感)。 | 例如两个二维向量[1,1]和[1,0],向量余弦相似度=0.707。 |
InnerProduct内积 | 以两个n维向量A = [A1, A2,…, An]和B= [B1, B2,…, Bn]为例:
| 内积同时考虑了两个向量的夹角及绝对长度。当向量归一化后,内积与余弦相似度计算公式等价。 | 例如两个二维向量[1,1]和[1,5],向量内积=1+5=6。 | |
Hamming汉明距离(仅支持binary类型) | 在信息理论中,Hamming Distance表示两个等长字符串在对应位置上不同字符的数量,我们以d(x, y)表示字符串x和y之间的汉明距离。从另外一个方面看,汉明距离度量了通过替换字符的方式将字符串x变成y所需要的最小的替换次数。 | 以两个n位的二进制编码x和y为例:
| 典型的用例包括数据通过计算机网络传输时的错误纠正或检测。它可以用来确定二进制字中不同字符的数目,作为估计误差的一种方法。 | 例如:1011101与1001001之间的汉明距离是2。 说明 在aliyun-knn插件使用中,binary类型的向量数据需要转换成无符号的32位十进制(uint32)数组表示,且 |
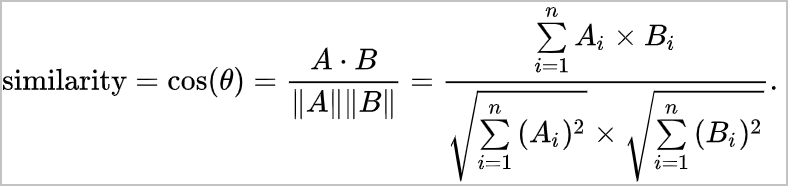
使用多种距离度量函数,需要确保:实例版本为6.7.0且apack插件版本≥1.2.1版本或实例版本为7.10.0版本且apack插件版本≥1.4.0。您可以通过GET _cat/plugins?v命令获取apack插件版本,如果apack插件版本不满足要求,则knn距离度量函数仅支持SquaredEuclidean欧氏距离(未开方)。如果您需要使用其他距离函数,可提交工单,由阿里云工程师帮您升级插件版本。
您可以在索引mapping中,通过distance_method参数指定不同的距离度量函数。
熔断参数
参数 | 描述 | 默认值 |
indices.breaker.vector.native.indexing.limit | 如果堆外内存使用超过该值,写入操作会被熔断;等待后台构建完成释放内存后,写入恢复正常。出现熔断错误表示当前系统内存消耗已经过高,建议业务上降低写入流量。 | 70% |
indices.breaker.vector.native.total.limit | 向量索引后台构建最多使用的堆外内存比例。如果实际使用的堆外内存超过了这个比例,可能会发生shard重启的情况。 | 80% |
向量熔断参数配置属于集群配置,可通过GET _cluster/settings命令查看,建议您不要调整熔断值。
高阶参数
表 2. 构建参数(hnsw)
参数 | 描述 | 默认值 |
index.vector.hnsw.builder.max_scan_num | 用于控制构图过程中的近邻考察范围,保证最坏情况的性能。 | 100000 |
index.vector.hnsw.builder.neighbor_cnt | hnsw 0层图每个节点的邻居数。建议配置为100。该值越大,离线索引存储消耗越大,图构建质量越高。 | 100 |
index.vector.hnsw.builder.upper_neighbor_cnt | hnsw上层图(除0层之外)中每个节点的邻居上限数。一般建议配置为neighbor_cnt的一半,最大不能超过255。 | 50 |
index.vector.hnsw.builder.efconstruction | 控制图构建过程中近邻扫描区域大小,该值越大,离线构图质量越好,索引构建越慢。建议初始值设置为400。 | 400 |
index.vector.hnsw.builder.max_level | hnsw总层数,包含0层图和上层图。例如总共1000万文档,scaling_factor为30,那么层数可以以max level=30为底,取1000万的对数向上取整,计算得5。 该值对效果影响不大,一般建议初始配置为6。 | 6 |
index.vector.hnsw.builder.scaling_factor | 下层图是上层图数据的多少倍,呈指数关系。通常设置在10~100之间。scaling_factor越大,实际生成的图层数越低。建议初始配置为50。 | 50 |
以上参数需在索引setting中设置使用,并且仅支持在hnsw算法模型中使用。
表 3. 查询参数(hnsw)
参数 | 描述 | 默认值 |
ef | 用于控制在线检索时,考察的子图范围大小。该值越大,召回越高,性能越差。建议取值[100,1000]。 | 100 |
查询示例如下。
GET test/_search
{
"query": {
"hnsw": {
"feature": {
"vector": [1.5, 2.5],
"size": 10,
"ef": 100
}
}
}
}常见问题
Q:如何评估查询的召回率?
A:可以同时创建两个索引,一个为hnsw算法,一个为linear算法,其他配置相同。客户端向两个索引同时推送相同的向量数据,刷新后,用同样的查询向量对比linear索引和hnsw索引召回的文档ID,交集的文档ID个数/召回总数,即为待测向量的召回率。
说明交集的文档ID个数是指两个索引召回的文档ID的交集。
Q:集群写入期间报错
circuitBreakingException,如何处理?A:这个错误表明此时系统的堆外内存使用率超过了indices.breaker.vector.native.indexing.limit指定的比例(默认为70%),触发了写入的熔断操作,一般等待后台的索引构建任务完成后会自动释放。建议客户端写入时添加错误重试机制。
Q:为什么写入任务已经停止了,CPU依然在工作?
A:向量索引的构建发生在refresh或flush期间,虽然写入流量已经停止,但后台的向量索引构建任务可能仍然在继续。等待最后一轮refresh结束后,计算资源就会被释放。
Q:使用aliyun-knn插件查询时报错
class_cast_exception: class org.apache.lucene.index.SoftDeletesDirectoryReaderWrapper$SoftDeletesFilterCodecReader cannot be cast to class org.apache.lucene.index.SegmentReader (org.apache.lucene.index.SoftDeletesDirectoryReaderWrapper$SoftDeletesFilterCodecReader and org.apache.lucene.index.SegmentReader are in unnamed module of loader 'app'),如何处理?A:关闭索引的物理复制功能,具体操作请参见使用apack插件的物理复制功能。
Q:使用aliyun-knn插件进行向量检索,速度过慢或出现内存熔断,怎么办?
A:aliyun-knn插件进行向量检索时,使用的是全内存型向量,非常消耗内存。当索引数据量较大时,由于需要将数据加载到内存,因此会出现速度慢或内存熔断的情况。建议索引数据量是机器内存的一半,在数据量无法变更的情况下,如果内存太小,建议您升配集群。
Q:关于aliyun-knn插件是否有提供最佳实践文档供参考?
A:您可以参见阿里云开发者社区提供的aliyun-knn插件业务场景和aliyun-knn最佳实践。
Q:knn场景使用
must_not exists无法过滤出feature字段为空的文档,如何编写语句过滤出feature字段为空的数据?A:knn数据存储比较特殊,可能会存在个别DSL查询不兼容的情况,您可以使用以下脚本进行过滤。
GET jx-similar-product-v1/_search { "query": { "bool": { "must": { "script": { "script": { "source": "doc['feature'].empty", "lang": "painless" } } } } } }