与Redis开源版不同,Tair混合存储型整合了内存和磁盘二者的优势,在提供高速数据读写能力的同时满足了数据持久化的需求。
混合存储型已停止售卖,更多信息,请参见【通知】Redis混合存储型实例停止售卖。推荐选择持久内存型实例。
简介
图 1. 混合存储型架构图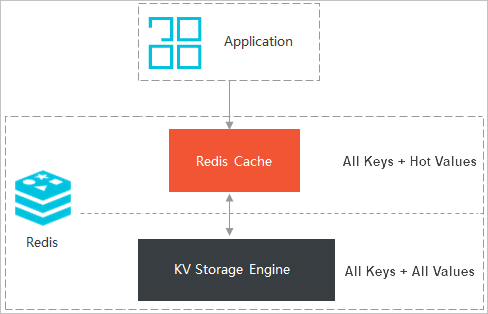
Tair(企业版)混合存储型(简称混合存储型)是阿里云自主研发的兼容Redis协议的混合存储产品,使用磁盘存储全量数据,将热数据保存到内存中供应用快速读写。在保证常用数据访问性能不下降的基础上,混合存储型能够大幅度降低用户成本,实现性能与成本的平衡,同时使单个Redis实例的数据量不再受内存大小的限制。
内存数据:内存中存放了热数据的Key和Value,同时为快速确认要操作的Key是否存在,内存中也会缓存所有的Key信息。
磁盘数据:磁盘中存放所有的Key和Value,Redis的数据结构(例如Hash)也会以一定的格式进行存储在磁盘。
适用场景
适用场景 | 说明 |
视频直播 | 视频直播类业务往往存在大量热点数据,大部分的请求都来自于热门的直播间。使用混合存储型,内存中保留热门直播间的数据,不活跃的直播间数据被自动存储到磁盘上,可以达到对有限内存的最佳利用效果。 |
电子商务 | 电商类应用往往有大量的商品数据。使用混合存储型可以轻松突破内存容量限制,将大量的商品数据都存储到混合存储型中。在正常业务请求中,活跃的商品数据会保留在内存,不活跃的商品数据会逐渐交换到磁盘上,从而解决内存不够的问题。 |
在线教育 | 在线教育类的场景有大量的课程、题库以及师生交流信息等数据,通常只有热门课程和最新题库会被频繁访问。使用混合存储型,将所有课程信息存储到磁盘,访问量大的课程和题库数据存储到内存并常驻内存,保证高频访问数据的读写性能,实现高性能与高性价比的有机结合。 |
典型业务场景的示例如下:
场景1:使用开源Redis集群存储了100GB的数据,但高峰期QPS不到2万,其中80%的数据的访问频率很低。
使用32GB内存加128GB磁盘的混合存储型实例后,节省了近70GB的内存空间,存储成本下降50%以上。
场景2:在IDC自建Pika实例来解决Redis存储成本高的问题。总数据量约400GB,其中访问频率高的数据仅占10%左右,并且集群的运维成本居高不下。
使用64GB内存加512GB磁盘的混合存储型实例后,既免除了繁重的运维工作,又保障了服务质量。