DLA Spark基于云原生架构,提供面向数据湖场景的数据分析和计算功能。开通DLA服务后,您只需简单的配置,就可以提交Spark作业,无需关心Spark集群部署。
云原生数据湖分析(DLA)产品已退市,云原生数据仓库 AnalyticDB MySQL 版湖仓版支持DLA已有功能,并提供更多的功能和更好的性能。AnalyticDB for MySQL相关使用文档,请参见Spark应用开发。
传统开源Spark集群版面临的挑战
Spark是大数据领域十分流行的引擎,面向数据湖场景,Spark本身内置的数据源连接器,可以很方便的扩展接口。Spark既支持使用SQL,又支持编写多种语言的DataFrame代码,兼具易用性和灵活性。Spark一站式的引擎能力,可以同时提供SQL、流、机器学习、图计算的能力。
但是对于传统Spark集群版,用户首先需要部署一套开源大数据基础组件:Yarn、HDFS、Zookeeper等,可能会存在以下问题:
使用门槛高:开发者需要同时熟悉多种大数据组件,才能完成开发与运维相关工作,如果遇到疑难问题,还要去深入研究社区源码。
运维成本高:企业往往需要一个运维团队,以运维多套开源组件。运维团队的职责包括配置资源节点、配置和部署开源软件、监控开源组件、开源组件升级、集群扩缩容等。典型的,为了满足企业级需求,比如权限隔离、监控报警等,还需要做定制化开发。
资源成本高:Spark作业负载往往具备波峰波谷的特点,在低峰期,Spark集群的空闲资源是浪费的;Spark集群的管控组件(比如,集群Master节点,Zookeeper、Hadoop等后台进程的资源开销等),是不会对用户产生价值的,属于额外开销。
弹性能力不足:在业务高峰期,企业往往需要能够准确预估资源需求,并及时扩容机器。如果扩容过多,则会存在资源浪费,如果扩容过少,则会影响业务。而且集群扩容过程较复杂,时间也会较长,并且云上容易出现资源库存不足的问题。
解决方案
Serverless Spark是云原生数据湖团队基于Apache Spark打造的服务化的大数据分析与计算服务。方案架构图如下所示: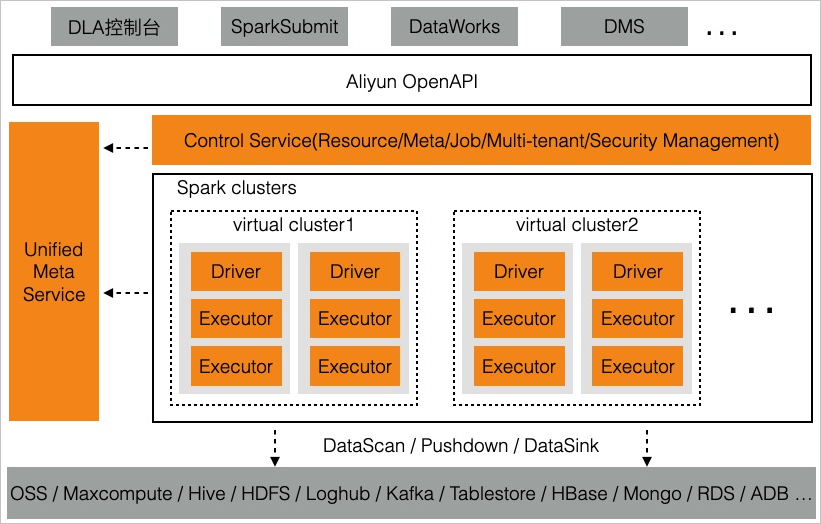
Serverless Spark将Spark、Serverless、云原生技术,深度整合到一起,相对于传统开源Spark集群版方案,具体以下优势:
入门门槛低:Serverless Spark屏蔽掉了底层的基础组件,提供简单的API、脚本以及控制台使用方式。开发者只需要了解开源Spark的使用方式就可以进行大数据业务开发。
0运维:用户只需通过产品接口管理Spark作业即可,无需关心服务器配置以及Hadoop集群配置,无需扩缩容等运维操作。
作业级细粒度的弹性能力:Serverless Spark按照Driver和Executor的粒度创建资源,相比于集群版的计算节点,粒度要细很多,粒度细的好处是库存不足的问题会大大降低。支持秒级拉起,目前每分钟可以拉起500~1000个计算节点,可以快速响应业务资源需求。
更低成本:每作业,每账单,不使用不收费。用户无需为管控资源付费,无需为低峰期空闲的计算资源付费。
良好的性能:云原生数据湖团队对Spark引擎做了深度定制和优化,特别是针对云产品,比如OSS,典型场景下,性能可以提升3~5倍。
说明关于进一步的性价比对比数据,您可以参考性价比白皮书中的测试结果。
企业级能力:Serverless Spark跟Serverless Presto共用元数据,可以通过GRANT、REVOKE语句对子用户进行权限管理。提供服务化的UI服务,相较于社区HistoryServer方式,无论作业多复杂,运行时间多长,都可以秒级打开。
基本概念
虚拟集群(Virtual Cluster)
Serverless Spark采用多租户模式,Spark进程运行在安全隔离的环境中,虚拟集群是资源隔离和安全隔离的单元。区别于传统实体集群,虚拟集群中没有固定的计算资源,您无需配置和维护计算节点,只需根据实际业务需要分配资源额度和配置待访问目标数据所在的网络环境。同时,虚拟集群也可以配置默认的Spark作业参数,方便您统一管理Spark作业。
计算单元CU(Compute Unit)
CU主要是Serverless Spark计量的基本单元,1CU=1 vCPU 4GB Memory。作业结束后,DLA会按照Driver和Executor实际使用的总和CU * 时,进行计量。具体的计费信息,请参考计费概述。
资源规格(Resource Specification)
Serverless Spark底层采用阿里云轻量虚拟机ECI,ECI跟ECS类似,都具备规格,DLA平台对具体的ECI规格进行了屏蔽、简化,用户只需要配置small、medium、large这样的简单配置即可,平台在调度的时候会优先使用高性能计算资源。
资源规格
计算资源
消耗的CU数
c.small
1Core 2GB
0.8CU
small
1Core 4GB
1CU
m.small
1Core 8GB
1.5CU
c.medium
2Core 4GB
1.6CU
medium
2Core 8GB
2CU
m.medium
2Core 16GB
3CU
c.large
4Core 8GB
3.2CU
large
4Core 16GB
4CU
m.large
4Core 32GB
6CU
c.xlarge
8Core 16GB
6.4CU
xlarge
8Core 32GB
8CU
m.xlarge
8Core 64GB
12CU
c.2xlarge
16Core 32GB
12.8CU
2xlarge
16Core 64GB
16CU
m.2xlarge
16Core 128GB
24CU
开始使用Serverless Spark
您可以参考DLA Spark快速入门来提交您的第一个Spark作业。
如果您需要访问数据源,请参考连接数据源目录下面的文档。
如果您对时空计算有需求,请参考数据湖时空引擎Ganos。
如果您想联系我们做进一步交流,请参考专家服务。