数据集成
DataWorks支持在数据开发(Data Studio)模块中直接创建和管理数据集成任务。旨在为开发者提供统一的工作环境,将数据的抽取、转换和加载全链路整合在同一视图下,无需在不同功能模块间切换。
功能概述
DataWorks允许在数据开发模块中,以创建普通任务节点的方式,来定义和管理数据集成任务。旨在为开发者提供统一的工作环境,将数据的抽取、转换和加载(ETL/ELT)全链路整合在同一视图下,无需在不同功能模块间切换。

其中,单表离线同步任务可以作为节点加入工作流并设置依赖,而其他类型的集成任务则作为独立节点存在。
核心机制:
-
配置一致:无论是数据开发还是在数据集成模块中创建任务,其配置界面、参数设置和底层功能完全一致。
-
双向同步:在数据集成模块中创建的任务,会自动同步并显示在数据开发模块的
data_integration_jobs目录下。这些任务会按照源端类型-目的端类型的通道进行归类,便于统一管理。
准备工作
-
数据源准备
-
已创建来源与去向数据源,数据源配置详见:数据源管理。
-
确保数据源支持实时同步能力,参见:支持的数据源及同步方案。
-
部分数据源需要开启日志,如Hologres、Oracle等。不同的数据源开启方式不同,详见数据源配置:数据源列表。
-
-
资源组:已购买并配置Serverless资源组。
-
网络连通:资源组与数据源之间需完成网络连通配置。
在数据开发中创建集成任务
以下步骤将引导您在数据开发中创建一个数据集成任务(以“MySQL到MaxCompute的单表离线同步”为例):
-
新建节点
-
进入DataWorks工作空间列表页,在顶部切换至目标地域,找到已创建的工作空间,单击操作列的,进入Data Studio。
-
点击顶部的 + 图标,或在工作流顶部的工具栏中,选择 。
-
配置基本信息
根据时效性要求、数据规模及同步复杂度,确定应采用离线同步还是实时同步;同时,结合源端与目标端的数据库类型、网络环境及功能支持情况,选择兼容的数据源组合与对应的同步方案(如单表离线、整库实时或整库全增量等)。
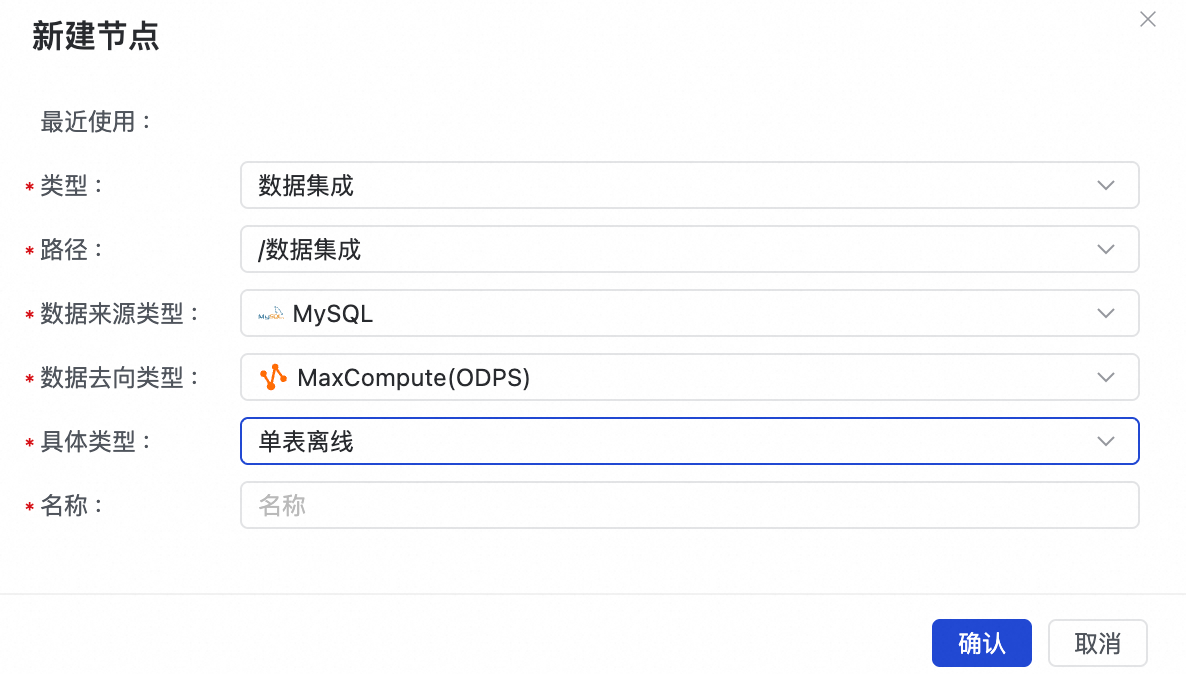
在弹出的新建节点对话框中,填写以下核心信息:
-
路径:选择该任务节点在数据开发目录树中的存放位置。
-
数据来源类型: 选择您的源数据源,例如
MySQL。 -
数据去向类型: 选择您的目标数据源,例如
MaxCompute(ODPS)。 -
具体类型:根据您的需求选择同步方案,如
整库实时、整库离线、整库全增量或单表离线。 -
名称:为您的任务节点命名,例如
mysql_to_mc_user_table。
-
-
点击确认,完成创建并自动跳转到其可视化配置页面。
-
-
配置任务详情
除配置入口和新建节点外,任务详情的配置方式与在数据集成中的使用完全一致,不再赘述。
-
配置调度(仅单表离线)
为节点配置调度时间、调度依赖及调度策略等属性,使其能够被调度系统周期性地自动执行。同时,通过设置调度参数,可为节点实例在运行时动态传递变量。
-
发布和运维
-
完成任务配置后,单击任务工具栏中的发布按钮,将集成任务提交至生产环境,并在运维中心中纳入统一调度与监控体系。
-
任务发布后,其运行状态、日志、告警及依赖关系均可在运维中心查看。关于集成任务的实例管理、失败重跑、性能调优、脏数据处理等运维操作,请参见任务运维和调优。
-
任务类型选择
创建数据集成节点时,您可以选择多种不同的同步模式。了解每种模式的适用场景和调度依赖特性,是构建高效、可靠工作流的关键。
单表离线同步
配置详情参见:向导模式配置、脚本模式配置。
-
描述:在两个数据存储之间,对单个源表和单个目标表进行周期性的批量数据同步。任务按设定的调度周期(如天、小时)运行。
-
适用场景:
-
每日T+1的业务数据同步,用于构建数据仓库的ODS层或DWD层。
-
定期将生产数据库的业务表归档至数据湖或数仓。
-
跨数据源进行周期性的报表数据迁移。
-
单表实时同步
配置详情参见:单表实时任务配置。
-
描述:基于日志变更数据捕获 (CDC) 或本身就是消息队列,对单个源表的数据变更(增、删、改)进行实时捕捉,并将其同步至目标表。
-
适用场景:
-
将业务数据库的实时变更数据同步至数据仓库(如MaxCompute、Hologres),用于构建实时数仓。
-
为实时监控大屏或实时推荐系统提供数据源。
-
在不同数据库实例间实现单表的实时数据复制。
-
整库离线同步
配置详情参见:整库离线同步任务。
-
描述:对源数据库中的全部或多个表进行一次性或周期性的批量数据同步。
-
适用场景:
-
首次将整个业务数据库完整迁移至云上数据仓库。
-
对整个数据库进行定期全量或增量备份。
-
初始化一个新的数据分析环境,需要一次性导入所有历史数据。
-
整库实时同步
配置详情参见:整库实时同步任务。
-
描述:实时捕捉整个源数据库中所有或指定表的结构变更(Schema Change)与数据变更(Data Change),并将其同步至目标端。
-
适用场景:
-
将整个生产OLTP数据库实时复制到分析型数据库中,实现读写分离和实时分析。
-
构建数据库的实时灾备或容灾方案。
-
保持数据湖或数据平台与上游多个业务系统的数据实时一致。
-
整库全增量同步
配置详情参见:整库全增量任务。
-
描述:实时同步捕获的CDC数据包含
Insert(插入)、Update(更新)和Delete(删除)三类操作。对于MaxCompute的非Delta Table类型表等原生不支持在物理层面执行Update/Delete的Append-Only(仅追加)存储系统,直接写入CDC流会导致数据状态不一致(例如,删除操作无法体现)。需通过在目标端创建Base表(全量快照)和Log表(增量日志)来解决此问题。 -
适用场景:
-
目的表为MaxCompute的非Delta Table类型,且源端表不具备自增字段条件,无法使用离线增量同步,可使用整库全增量任务,实现数据分钟级写入增量表,最终状态T+1合并可见。
-
差异说明
|
任务类型 |
可创建位置 |
是否支持工作流内部编排 |
是否支持调度配置 |
是否支持在数据开发中调试 |
是否支持数据源开发生产隔离 |
|
单表离线同步 |
仅数据开发 |
|
|
|
|
|
单表实时同步 |
数据开发 / 数据集成 |
(仅作为独立节点) |
|
(需发布至运维中心运行) |
|
|
整库离线同步 |
数据开发 / 数据集成 |
(仅作为独立节点) |
(可为子任务单独设置调度时间) |
(需发布至运维中心运行) |
|
|
整库实时同步 |
数据开发 / 数据集成 |
(仅作为独立节点) |
|
(需发布至运维中心运行) |
|
|
整库全增量 |
数据开发 / 数据集成 |
(仅作为独立节点) |
(可为子任务单独设置调度时间) |
(需发布至运维中心运行) |
|
常见问题
数据集成常见问题参见:数据集成常见问题。