在EMR任务开发中,通过创建EMR(E-MapReduce) MR节点,可将大规模数据集分为多个Map任务并行处理,加速数据集的并行运算。本文将以创建EMR MR节点实现从OSS中读取文本,并统计文本中的单词数为例,为您展示EMR MR节点的作业开发流程。
前提条件
已注册EMR集群至DataWorks,详情请参见旧版数据开发:绑定EMR计算资源。
(可选,RAM账号需要)进行任务开发的RAM账号已被添加至对应工作空间中,并具有开发或空间管理员(权限较大,谨慎添加)角色权限,添加成员的操作详情请参见为工作空间添加空间成员。
已购买Serverless资源组并完成资源组配置,包括绑定工作空间、网络配置等,详情请参见新增和使用Serverless资源组。
数据开发(DataStudio)中已创建业务流程,操作详情请参见创建业务流程。
使用EMR MR节点进行作业开发时,如果需要引用开源代码资源,您需先将开源代码作为资源上传至EMR JAR资源节点中,详情请参见创建和使用EMR资源。
使用EMR MR节点进行作业开发时,如果需要引用自定义函数,您需要先将自定义函数作为资源上传至EMR JAR资源节点中,新建注册此函数,详情请参见创建EMR函数。
如果您使用本文的作业开发示例执行相关作业流程,则还需要创建好OSS的存储空间Bucket。创建OSS的存储空间Bucket,详情请参见控制台创建存储空间。
使用限制
仅支持使用Serverless资源组(推荐)或独享调度资源组运行该类型任务。
DataLake或自定义集群若要在DataWorks管理元数据,需先在集群侧配置EMR-HOOK。若未配置,则无法在DataWorks中实时展示元数据、生成审计日志、展示血缘关系、开展EMR相关治理任务。配置EMR-HOOK,详情请参见配置Hive的EMR-HOOK。
准备初始数据及JAR资源包
准备初始数据
创建示例文件input01.txt,文件内容如下。
hadoop emr hadoop dw
hive hadoop
dw emr上传初始数据文件
登录OSS管理控制台,单击左侧导航栏的Bucket列表。
单击目标Bucket名称,进入文件管理页面。
本文示例使用的Bucket为onaliyun-bucket-2。
单击新建目录,创建初始数据及JAR资源的存放目录。
配置目录名为emr/datas/wordcount02/inputs,创建初始数据的存放目录。
配置目录名为emr/jars,创建JAR资源的存放目录。
上传初始数据文件至初始数据的存放目录。
进入/emr/datas/wordcount02/inputs路径,单击上传文件。
在待上传文件区域单击扫描文件,添加input01.txt文件至Bucket,单击上传文件。
使用MapReduce读取OSS文件并生成JAR包
打开已创建的IDEA项目,添加pom依赖。
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.8.5</version> <!--因为EMR-MR用的是2.8.5--> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.8.5</version> </dependency>在MapReduce中读写OSS文件,需要配置如下参数。
重要风险提示: 阿里云账号AccessKey拥有所有API的访问权限,建议您使用RAM用户进行API访问或日常运维。强烈建议不要将AccessKey ID和AccessKey Secret保存到工程代码里或者任何容易被泄露的地方,AccessKey泄露会威胁您账号下所有资源的安全。以下代码示例仅供参考,请妥善保管好您的AccessKey信息。
conf.set("fs.oss.accessKeyId", "${accessKeyId}"); conf.set("fs.oss.accessKeySecret", "${accessKeySecret}"); conf.set("fs.oss.endpoint","${endpoint}");参数说明如下:
${accessKeyId}:阿里云账号的AccessKey ID。${accessKeySecret}:阿里云账号的AccessKey Secret。${endpoint}:OSS对外服务的访问域名。由您集群所在的地域决定,对应的OSS也需要是在集群对应的地域,详情请参见OSS地域和访问域名
以Java代码为例,修改Hadoop官网WordCount示例,即在代码中添加AccessKey ID和AccessKey Secret的配置,以便作业有权限访问OSS文件。
将代码打包成JAR文件。
编辑保存Java代码后,将Java代码打包成JAR文件。示例生成的JAR包为onaliyun_mr_wordcount-1.0-SNAPSHOT.jar。
步骤一:创建EMR MR节点
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
新建EMR MR节点。
右键单击目标业务流程,选择。
说明您也可以鼠标悬停至新建,选择。
在新建节点对话框中,输入名称,并选择引擎实例、节点类型及路径。单击确认,进入EMR MR节点编辑页面。
说明节点名称支持大小写字母、中文、数字、下划线(_)和小数点(.)。
步骤二:开发EMR MR任务
在EMR MR节点编辑页面双击已创建的节点,进入任务开发页面,您可以根据不同场景需求选择适合您的操作方案:
(推荐)先从本地上传资源至DataStudio,再引用资源,详情请参见方案一:上传资源方式引用资源。
使用OSS REF方式引用OSS资源,详情请参见方案二:OSS REF方式引用资源。
方案一:上传资源方式引用资源
DataWorks也支持您从本地先上传资源至DataStudio,再引用资源。若EMR MR节点依赖的资源较大,则无法通过DataWorks页面上传。您可将资源存放至HDFS上,然后在代码中进行引用。
创建EMR JAR资源。
详情请参见创建和使用EMR资源。示例将本文《准备初始数据及JAR资源包》中生成的JAR包存储在JAR资源的存放目录emr/jars下。首次使用需要进行一键授权,然后单击点击上传按钮,上传JAR资源。
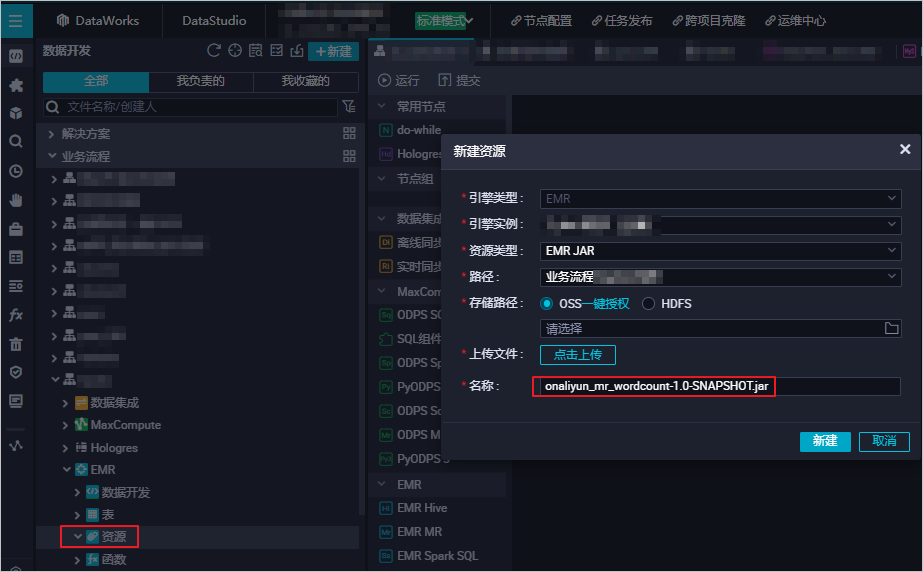
引用EMR JAR资源。
打开创建的EMR MR节点,停留在代码编辑页面。
在节点下,找到待引用资源(示例为
onaliyun_mr_wordcount-1.0-SNAPSHOT.jar),右键选择引用资源。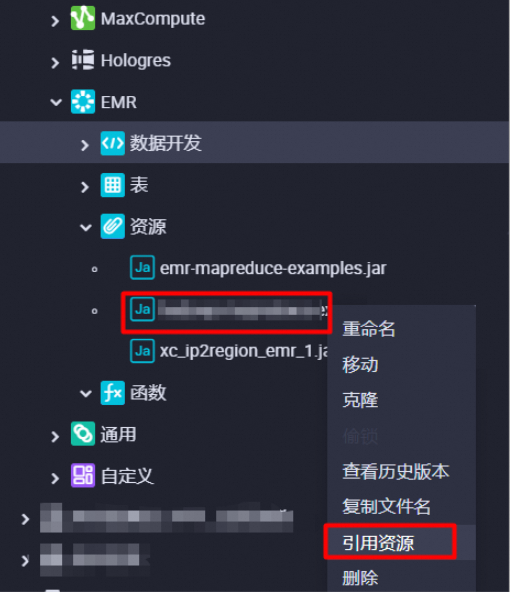
选择引用后,当EMR MR节点的代码编辑页面出现如下引用成功提示时,表明已成功引用代码资源。此时,需要执行下述命令。如下命令涉及的资源包、Bucket名称、路径信息等为本文示例的内容,使用时,您需要替换为实际使用信息。
##@resource_reference{"onaliyun_mr_wordcount-1.0-SNAPSHOT.jar"} onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs说明EMR MR节点编辑代码时不支持注释语句。
方案二:OSS REF方式引用资源
当前节点可通过OSS REF的方式直接引用OSS资源,在运行EMR节点时,DataWorks会自动加载代码中的OSS资源至本地使用。该方式常用于“需要在EMR任务中运行JAR依赖”、“EMR任务需依赖脚本”等场景。
上传JAR资源。
完成代码开发后,您需登录OSS管理控制台,单击所在地域左侧导航栏的Bucket列表。
单击目标Bucket名称,进入文件管理页面。
本文示例使用的Bucket为
onaliyun-bucket-2。上传JAR资源至JAR资源的存放目录。
进入存放目录
emr/jars,单击上传文件,在待上传文件区域单击扫描文件,添加onaliyun_mr_wordcount-1.0-SNAPSHOT.jar文件至Bucket,单击上传文件。
引用JAR资源。
编辑引用JAR资源代码。
在已创建的EMR MR节点编辑页面,编辑引用JAR资源代码。
hadoop jar ossref://onaliyun-bucket-2/emr/jars/onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs说明上述命令行格式为
hadoop jar <引用运行JAR存储路径> <运行的主类全名称> <读入文件存储目录> <写出结果存储目录>。引用运行JAR存储路径参数说明:
参数
参数说明
引用运行JAR存储路径
格式为
ossref://{endpoint}/{bucket}/{object}endpoint:OSS对外服务的访问域名。Endpoint为空时,仅支持使用与当前访问的EMR集群同地域的OSS,即OSS的Bucket需要与EMR集群所在地域相同。
Bucket:OSS用于存储对象的容器,每一个Bucket有唯一的名称,登录OSS管理控制台,可查看当前登录账号下所有Bucket。
object:存储在Bucket中的一个具体的对象(文件名称或路径)。
(可选)配置高级参数
您可在节点高级设置处配置特有属性参数。更多属性参数设置,请参考Spark Configuration。不同类型EMR集群可配置的高级参数存在部分差异,具体如下表。
DataLake集群/自定义集群:EMR on ECS
高级参数 | 配置说明 |
queue | 提交作业的调度队列,默认为default队列。关于EMR YARN说明,详情请参见队列基础配置。 |
priority | 优先级,默认为1。 |
其他 | 您也可以直接在高级配置里追加自定义MR任务参数。提交代码时DataWorks会自动在命令中通过 |
Hadoop集群:EMR on ECS
高级参数 | 配置说明 |
queue | 提交作业的调度队列,默认为default队列。关于EMR YARN说明,详情请参见队列基础配置。 |
priority | 优先级,默认为1。 |
USE_GATEWAY | 设置本节点提交作业时,是否通过Gateway集群提交。取值如下:
说明 如果本节点所在的集群未关联Gateway集群,此处手动设置参数取值为 |
执行SQL任务
步骤三:配置节点调度
如您需要周期性执行创建的节点任务,可单击节点编辑页面右侧的调度配置,根据业务需求配置该节点任务的调度信息。配置详情请参见任务调度属性配置概述。
您需要设置节点的重跑属性和依赖的上游节点,才可以提交节点。
步骤四:发布节点任务
节点任务配置完成后,需执行提交发布操作,提交发布后节点即会根据调度配置内容进行周期性运行。
单击工具栏中的
 图标,保存节点。
图标,保存节点。单击工具栏中的
 图标,提交节点任务。
图标,提交节点任务。提交时需在提交对话框中输入变更描述,并根据需要选择是否在节点提交后执行代码评审。
说明您需设置节点的重跑属性和依赖的上游节点,才可提交节点。
代码评审可对任务的代码质量进行把控,防止由于任务代码有误,未经审核直接发布上线后出现任务报错。如进行代码评审,则提交的节点代码必须通过评审人员的审核才可发布,详情请参见代码评审。
如您使用的是标准模式的工作空间,任务提交成功后,需单击节点编辑页面右上方的发布,将该任务发布至生产环境执行,操作请参见发布任务。
后续步骤
任务提交发布后,会基于节点的配置周期性运行,您可单击节点编辑界面右上角的运维,进入运维中心查看周期任务的调度运行情况。详情请参见管理周期任务。
查看结果
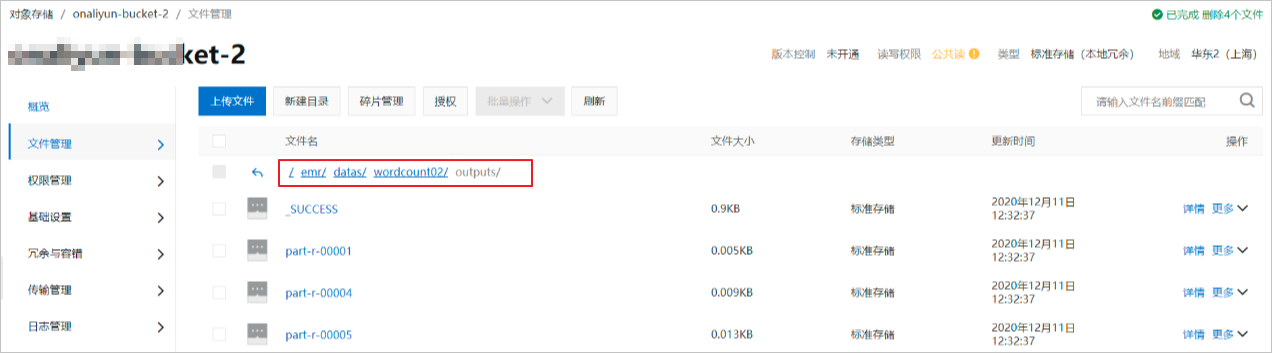
登录OSS管理控制台,您可以在目标Bucket的初始数据存放目录下查看写入结果。示例路径为emr/datas/wordcount02/outputs。
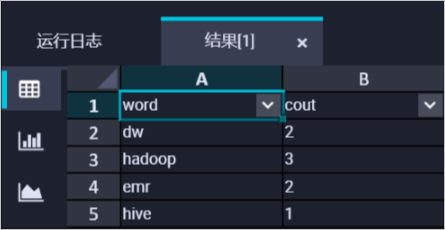
在DataWorks读取统计结果。
新建EMR Hive节点,详情请参见创建EMR Hive节点。
在EMR Hive节点中创建挂载在OSS上的Hive外表,读取表数据。代码示例如下。
CREATE EXTERNAL TABLE IF NOT EXISTS wordcount02_result_tb ( `word` STRING COMMENT '单词', `cout` STRING COMMENT '计数' ) ROW FORMAT delimited fields terminated by '\t' location 'oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs/'; SELECT * FROM wordcount02_result_tb;运行结果如下图。