Kafka是应用较为广泛的分布式、高吞吐量、高可扩展性消息队列服务,普遍用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,是大数据生态中不可或缺的产品之一。通过数据传输服务DTS(Data Transmission Service),您可以将RDS MySQL迁移至有公网IP的自建Kafka集群,扩展消息处理能力。
前提条件
已完成Kafka集群的搭建,且Kafka的版本为0.10.1.0-2.7.0版本。
Kafka集群的服务端口已开放至公网。
背景信息
由于数据同步功能对自建Kafka的部署位置要求如下:
ECS上的自建数据库
通过专线/VPN网关/智能接入网关接入的自建数据库
无公网IP:Port的数据库(通过数据库网关DG接入)
通过云企业网CEN接入的自建数据库
如果Kafka集群的部署位置为本地,且不符合上述场景,您可以将自建Kafka的服务端口开放至公网,然后通过本文介绍的方法来实现数据同步需求。
注意事项
DTS在执行全量数据迁移时将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升,在数据库性能较差、规格较低或业务量较大的情况下(例如源库有大量慢SQL、存在无主键表或目标库存在死锁等),可能会加重数据库压力,甚至导致数据库服务不可用。因此您需要在执行数据迁移前评估源库和目标库的性能,同时建议您在业务低峰期执行数据迁移(例如源库和目标库的CPU负载在30%以下)。
如果源数据库没有主键或唯一约束,且所有字段没有唯一性,可能会导致目标数据库中出现重复数据。
迁移对象仅支持数据表。
费用说明
迁移类型 | 链路配置费用 | 公网流量费用 |
结构迁移和全量数据迁移 | 不收费。 | 通过公网将数据迁移出阿里云时将收费,详情请参见计费概述。 |
增量数据迁移 | 收费,详情请参见计费概述。 |
操作步骤
登录数据传输控制台。
说明若数据传输控制台自动跳转至数据管理DMS控制台,您可以在右下角的
 中单击
中单击 ,返回至旧版数据传输控制台。
,返回至旧版数据传输控制台。在左侧导航栏,单击数据迁移。
在迁移任务列表页面顶部,选择迁移的目标集群所属地域。
单击页面右上角的创建迁移任务。
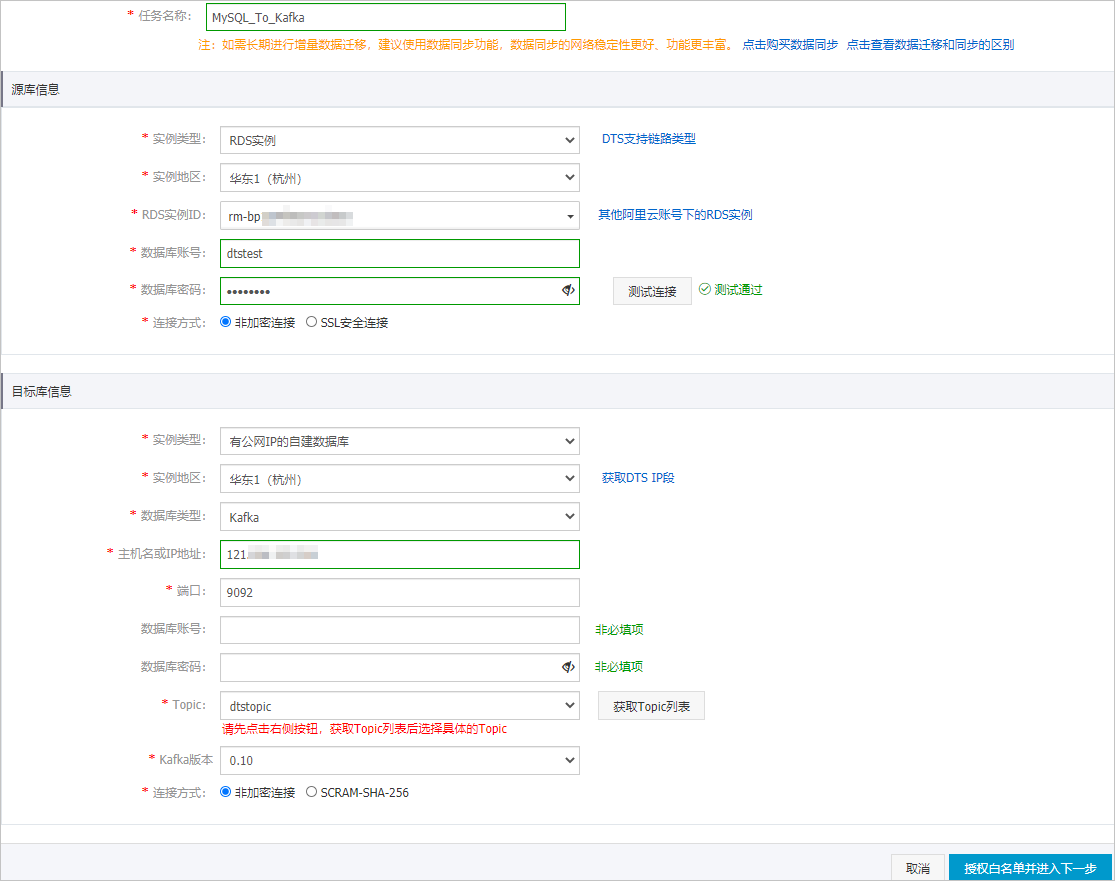
配置迁移任务的源库及目标库信息。
类别
配置
说明
无
任务名称
DTS会自动生成一个任务名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。
源库信息
实例类型
选择RDS。
实例地区
选择源RDS实例所属的地域。
实例ID
选择源RDS实例ID。
数据库账号
填入源RDS实例的数据库账号,需具备REPLICATION CLIENT、REPLICATION SLAVE、SHOW VIEW和所有迁移对象的SELECT权限。
数据库密码
填入该数据库账号的密码。
连接方式
根据需求选择非加密连接或SSL安全连接。如果设置为SSL安全连接,您需要提前开启RDS实例的SSL加密功能,详情请参见设置SSL加密。
重要目前仅中国内地及中国香港地域支持设置连接方式。
目标库信息
实例类型
选择有公网IP的自建数据库。
实例地区
无需设置。
数据库类型
选择Kafka。
主机名或IP地址
填入自建Kafka集群的访问地址,本案例中填入公网地址。
端口
填入Kafka集群提供服务的端口,默认为9092。
数据库账号
填入Kafka集群的用户名,如Kafka集群未开启验证可不填写。
数据库密码
填入Kafka集群用户名的密码,如Kafka集群未开启验证可不填写。
Topic
单击右侧的获取Topic列表,然后在下拉框中选择目标Topic。
Kafka版本
选择目标Kafka集群的版本。
连接方式
根据业务及安全需求,选择非加密连接或SCRAM-SHA-256。
配置完成后,单击页面右下角的授权白名单并进入下一步。
如果源或目标数据库是阿里云数据库实例(例如RDS MySQL、云数据库MongoDB版等),DTS会自动将对应地区DTS服务的IP地址添加到阿里云数据库实例的白名单;如果源或目标数据库是ECS上的自建数据库,DTS会自动将对应地区DTS服务的IP地址添到ECS的安全规则中,您还需确保自建数据库没有限制ECS的访问(若数据库是集群部署在多个ECS实例,您需要手动将DTS服务对应地区的IP地址添到其余每个ECS的安全规则中);如果源或目标数据库是IDC自建数据库或其他云数据库,则需要您手动添加对应地区DTS服务的IP地址,以允许来自DTS服务器的访问。DTS服务的IP地址,请参见DTS服务器的IP地址段。
警告DTS自动添加或您手动添加DTS服务的公网IP地址段可能会存在安全风险,一旦使用本产品代表您已理解和确认其中可能存在的安全风险,并且需要您做好基本的安全防护,包括但不限于加强账号密码强度防范、限制各网段开放的端口号、内部各API使用鉴权方式通信、定期检查并限制不需要的网段,或者使用通过内网(专线/VPN网关/智能网关)的方式接入。
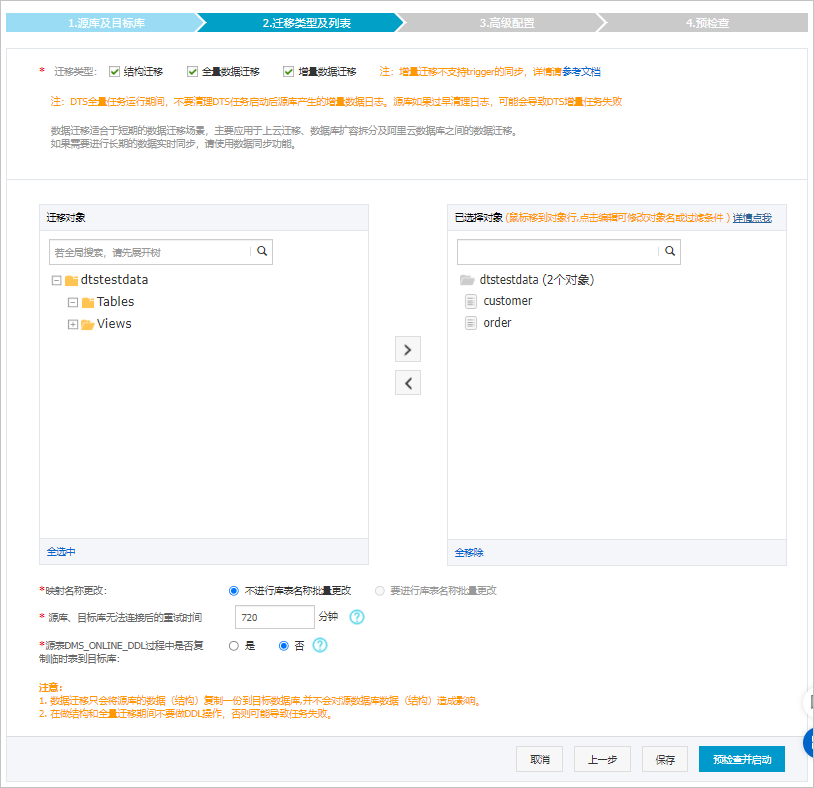
配置迁移类型、策略和对象信息。
配置
说明
迁移类型
同时选中结构迁移、全量数据迁移和增量数据迁移。
重要如果未选中增量数据迁移,为保障数据一致性,全量数据迁移期间请勿在源库中写入新的数据。
投递到kafka的数据格式
迁移到Kafka集群中的数据以avro格式或者Canal Json格式存储,定义详情请参见Kafka集群的数据存储格式。
迁移到Kafka Partition策略
根据业务需求选择迁移的策略,详细介绍请参见Kafka Partition同步策略说明。
迁移对象
在迁移对象框中单击待迁移的表,然后单击
 图标将其移动至已选择对象框。
图标将其移动至已选择对象框。映射名称更改
如需更改迁移对象在目标实例中的名称,请使用对象名映射功能,详情请参见库表列映射。
源、目标库无法连接重试时间
默认重试12小时,您也可以自定义重试时间。如果DTS在设置的时间内重新连接上源、目标库,迁移任务将自动恢复。否则,迁移任务将失败。
说明由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
源表DMS_ONLINE_DDL过程中是否复制临时表到目标库
如源库使用数据管理DMS(Data Management)执行Online DDL变更,您可以选择是否迁移Online DDL变更产生的临时表数据。
是:迁移Online DDL变更产生的临时表数据。
说明Online DDL变更产生的临时表数据过大,可能会导致迁移任务延迟。
否:不迁移Online DDL变更产生的临时表数据,只迁移源库的原始DDL数据。
说明该方案会导致目标库锁表。
上述配置完成后,单击页面右下角的预检查并启动。
说明在迁移任务正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动迁移任务。
如果预检查失败,单击具体检查项后的
 ,查看失败详情。
,查看失败详情。您可以根据提示修复后重新进行预检查。
如无需修复告警检测项,您也可以选择确认屏蔽、忽略告警项并重新进行预检查,跳过告警检测项重新进行预检查。
预检查通过后,单击下一步。
在弹出的购买配置确认对话框,选择链路规格并选中数据传输(按量付费)服务条款。
单击购买并启动,迁移任务正式开始。
结构迁移+全量数据迁移
请勿手动结束迁移任务,否则可能会导致数据不完整。您只需等待迁移任务完成即可,迁移任务会自动结束。
结构迁移+全量数据迁移+增量数据迁移
迁移任务不会自动结束,您需要手动结束迁移任务。
重要请选择合适的时间手动结束迁移任务,例如业务低峰期或准备将业务切换至目标集群时。
观察迁移任务的进度变更为增量迁移,并显示为无延迟状态时,将源库停写几分钟,此时增量迁移的状态可能会显示延迟的时间。
等待迁移任务的增量迁移再次进入无延迟状态后,手动结束迁移任务。