模型训练完成后,通常会被部署为推理服务。推理服务的调用量会随着业务需求动态变化,因此需要服务器具备弹性扩缩容能力以降低成本。在大规模高并发场景下,传统部署方案往往难以满足此类需求。阿里云容器服务通过提供弹性节点池,支持基于弹性节点池部署模型推理服务,从而实现高效的弹性伸缩。本文将介绍如何基于ECS运行弹性推理工作负载。
前提条件
操作步骤
创建弹性节点池。
将训练模型上传到OSS。具体操作,请参见控制台上传文件。
创建PV和PVC。
创建
pvc.yaml。apiVersion: v1 kind: PersistentVolume metadata: name: model-csi-pv spec: capacity: storage: 5Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: model-csi-pv // 需要和PV名字一致。 volumeAttributes: bucket: "<Your Bucket>" url: "<Your oss url>" akId: "<Your Access Key Id>" akSecret: "<Your Access Key Secret>" otherOpts: "-o max_stat_cache_size=0 -o allow_other" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 5Gi参数
说明
bucket
OSS的Bucket名称,在OSS范围内全局唯一。更多信息,请参见存储空间命名。
url
OSS文件的访问URL。更多信息,请参见如何获取单个或多个文件的URL。
akId
访问OSS的AccessKey ID和AccessKey Secret。建议使用RAM用户访问,更多信息,请参见创建AccessKey。
akSecret
otherOpts
挂载OSS时支持定制化参数输入。
-o max_stat_cache_size=0代表禁用属性缓存,每次访问文件都会从 OSS 中获取最新的属性信息。-o allow_other代表允许其他用户访问挂载的文件系统。
参数设置的更多信息,请参见ossfs支持的设置参数选项。
执行以下命令,创建PV和PVC。
kubectl apply -f pvc.yaml
执行以下命令,部署推理服务。
arena serve tensorflow \ --name=bert-tfserving \ --model-name=chnsenticorp \ --selector=inference:tensorflow \ --gpus=1 \ --image=tensorflow/serving:1.15.0-gpu \ --data=model-pvc:/models \ --model-path=/models/tensorflow \ --version-policy=specific:1623831335 \ --limits=nvidia.com/gpu=1 \ --requests=nvidia.com/gpu=1参数
说明
selectorselector参数根据标签选择用于选择TensorFlow训练任务所需的Pods。本例设置为inference: tensorflow。limits: nvidia.com/gpu最多可使用的GPU卡数量。
requests: nvidia.com/gpu需要使用的GPU卡数量。
model-name模型的名称。
model-path模型的访问路径。
创建HPA(Horizontal Pod Autoscaler)。HPA可以根据不同负载情况,自动调整Kubernetes中的Pod副本数量。
创建
hpa.yaml。apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: bert-tfserving-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: bert-tfserving-202107141745-tensorflow-serving minReplicas: 1 maxReplicas: 10 metrics: - type: External external: metricName: sls_ingress_qps metricSelector: matchLabels: sls.project: "k8s-log-c210fbedb96674b9eaf15f2dc47d169a8" sls.logstore: "nginx-ingress" sls.ingress.route: "default-bert-tfserving-202107141745-tensorflow-serving-8501" targetAverageValue: 10参数
说明
scaleTargetRef设置当前HPA绑定的对象,配置为推理服务对应的Deployment名称。
minReplicas最小副本数。
maxReplicas最大副本数。
sls.project集群的日志项目名称,配置规则为
k8s-log-{cluster id}。sls.logstore日志库的名称,默认值为
nginx-ingress。sls.ingress.routeIngress路由,配置规则为
{namespace}-{service name}-{service port}。metricname指标名称,本文配置为
sls_ingress_qps。targetaverageValue触发弹性扩容的QPS值。本文配置为
10,表示当QPS大于10时,触发弹性扩容。执行以下命令,部署HPA。
kubectl apply -f hpa.yaml
配置公网Ingress。
通过
arena serve tensorflow命令部署的推理服务默认使用 ClusterIP类型,无法直接通过公网访问。因此,需要为推理服务创建一个公网Ingress,以便实现便捷的访问。登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在路由页面上方,选择推理服务所在的命名空间,然后单击创建Ingress,配置如下参数。关于参数的更多信息,请参见创建Nginx Ingress。
名称:本文配置为
bert-tfserving。规则:
域名:自定义域名,例如:
test.example.com。路径映射
路径:不做配置,保留根路径
/。匹配规则:默认(ImplementationSpecific)。
服务名称:通过执行
kubectl get service命令获取。端口:本文配置为8501。
- 路由创建成功后,您可以在路由页面的规则列获取到Ingress地址。
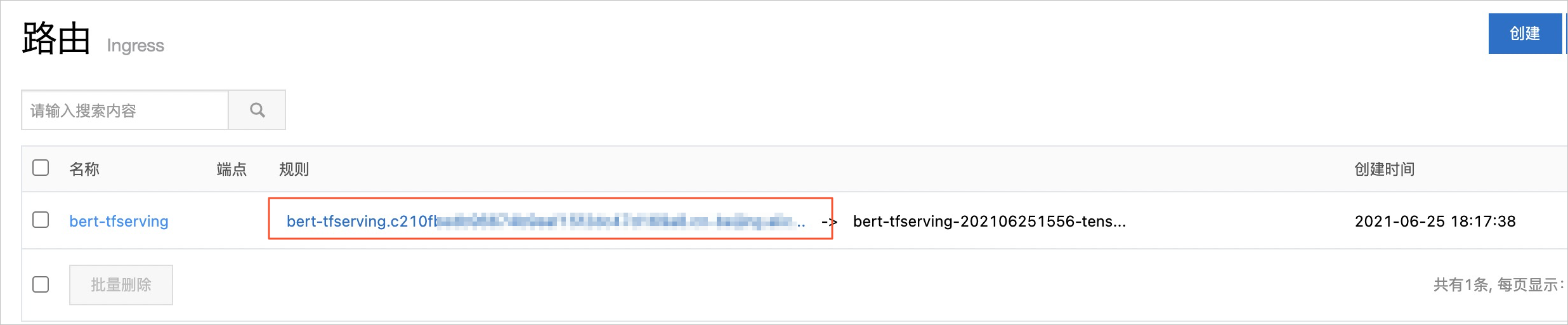
使用获取的Ingress地址对推理服务进行压测。
登录运维控制台。具体操作,请参见访问AI运维控制台。
重要在登录运维控制台前,您需要安装和配置访问方式,具体步骤,请参见安装云原生AI套件。
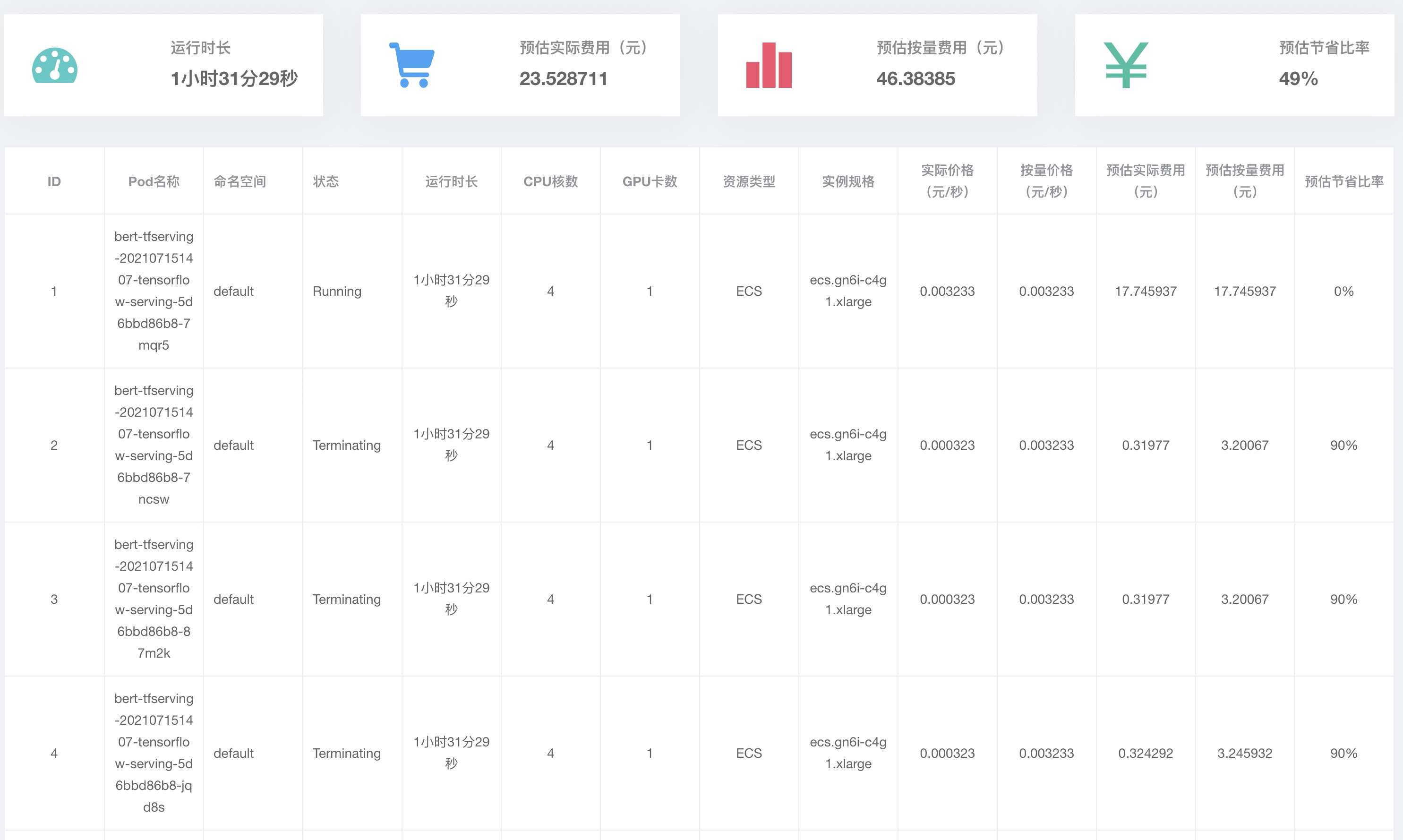
在运维控制台导航栏选择,单击推理任务页签,查看推理服务的详情。
扩容得到的Pod,都运行在ECS实例上。其中既有按量付费实例,也有抢占式实例(Spot),且数量比例等于创建节点池时配置的比例。