GPU监控基于NVIDIA DCGM构建功能强大的GPU监控体系。本文介绍如何开启集群GPU监控。
前提条件
已开通ARMS。
背景信息
对于Kubernetes集群的大规模GPU设备管理,需建立完善的监控体系。通过监测GPU相关指标,可以了解整个集群的GPU的使用情况、健康状态、工作负载性能等,从而实现对异常问题的快速诊断、优化GPU资源的分配、提升资源利用率等。除运维人员以外,其他人员(例如数据科学家、AI算法工程师等)也能通过相关监控指标了解业务的GPU使用情况,以助于进行容量规划和任务调度。
NVIDIA支持使用数据中心GPU管理器DCGM(Data Center GPU Manager)来管理大规模集群中的GPU。基于NVIDIA DCGM构建的GPU监控系统具有更强大的功能,提供了多种GPU监控指标,其主要功能包括:
GPU行为监控
GPU配置管理
GPU Policy管理
GPU健康诊断
GPU级别统计和线程级别统计
NVSwitch配置和监控
使用限制
节点NVIDIA驱动需为418.87.01及以上版本。您可以登录GPU节点,执行
nvidia-smi命令查看驱动版本。若您需要使用GPU Profiling Metrics,则节点NVIDIA驱动需为450.80.02及以上版本。关于GPU Profiling Metrics的更多信息,请参见Feature Overview。
不支持对NVIDIA MIG进行监控。
费用说明
关于阿里云Prometheus的收费策略,请参见计费概述。
1. 开启Prometheus监控
请确保ack-arms-prometheus组件为1.1.7及以上版本。可查看ack-arms-prometheus组件版本,确认组件版本后,升级组件。
创建集群时开启


在已有集群中开启
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在Prometheus 监控页面,按照页面提示完成相关组件的安装和监控大盘的检查。
控制台会自动安装组件、检查监控大盘。安装完成后,您可以单击各个页签查看相应监控数据。
如果您想了解更多关于开启Prometheus监控的操作,请参见开启阿里云Prometheus监控。
当采用开源自建的Prometheus服务,您如果需要GPU监测能力,需要安装ack-gpu-exporter组件。
2. 部署示例应用
使用以下YAML内容,创建tensorflow-benchmark.yaml文件。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=50000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #申请1张GPU卡。 workingDir: /root restartPolicy: Never执行以下命令,在GPU节点上部署tensorflow-benchmark应用。
kubectl apply -f tensorflow-benchmark.yaml执行以下命令,查看Pod状态。
kubectl get pod预期输出:
NAME READY STATUS RESTARTS AGE tensorflow-benchmark-k*** 1/1 Running 0 114s
3. 查看集群GPU监控
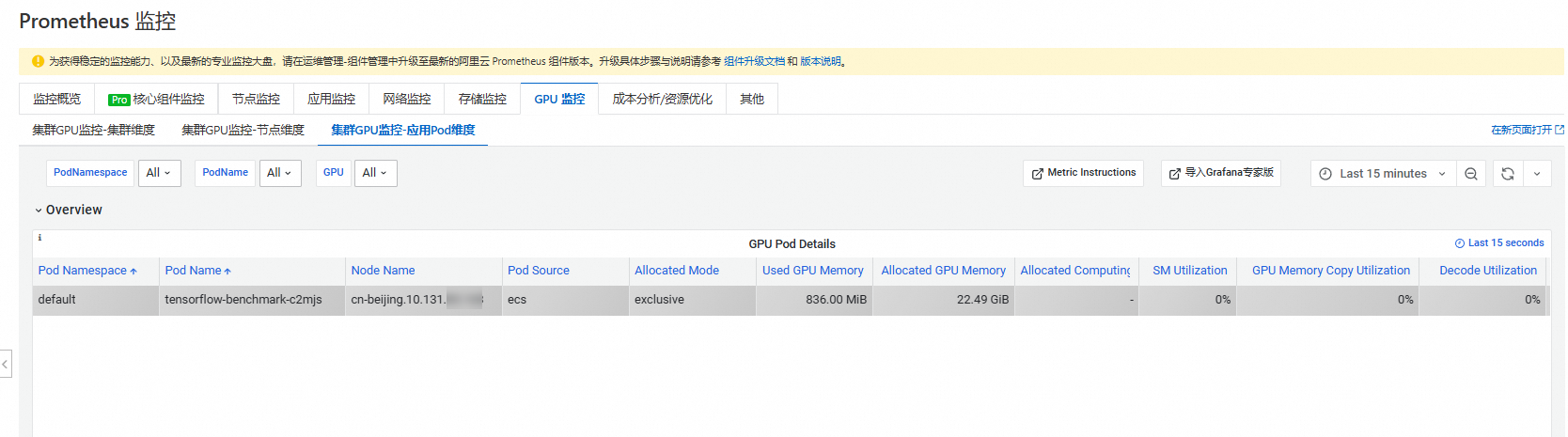
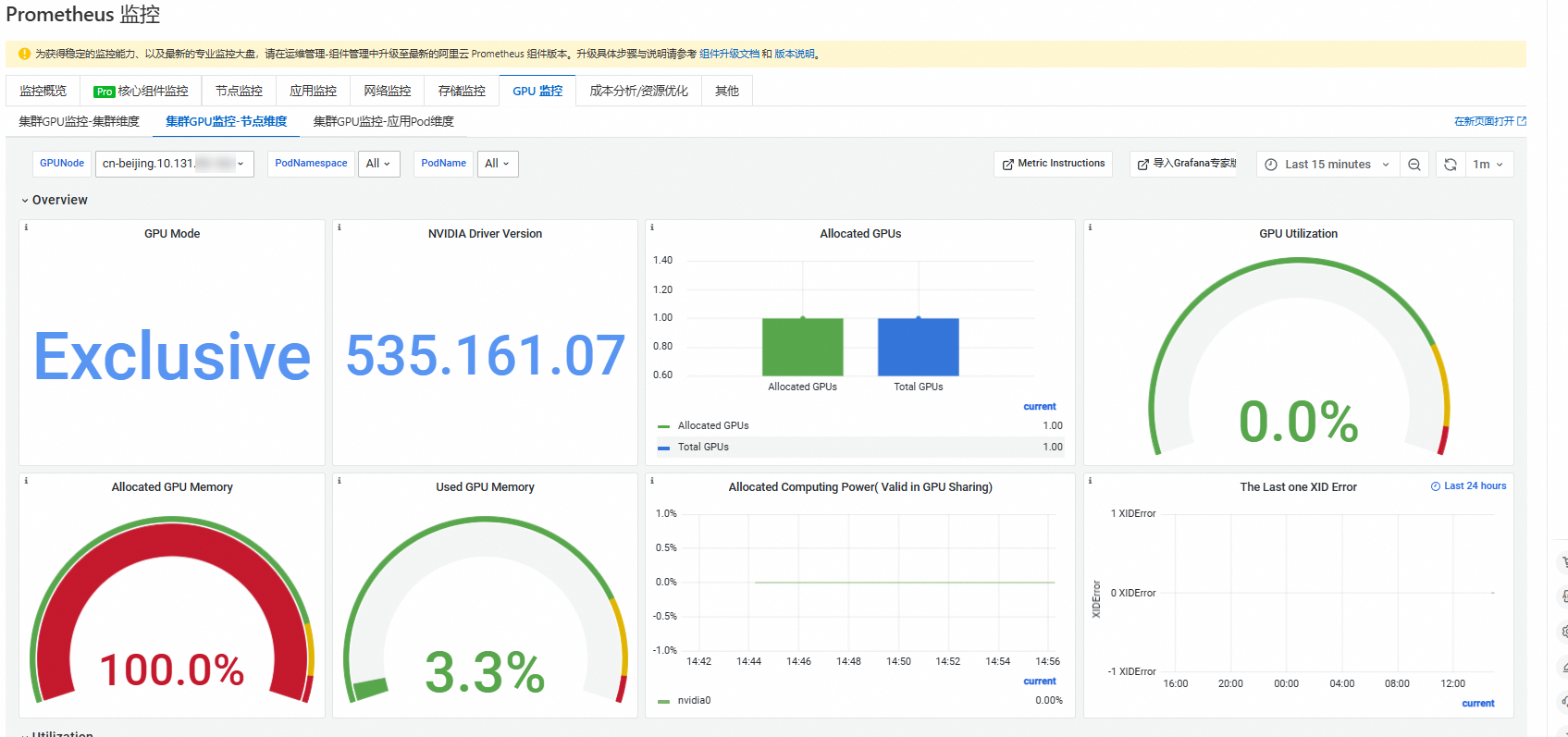
常见问题
DCGM内存泄漏
背景:DCGM(Data Center GPU Manager)是NVIDIA提供的一款用于管理和监控GPU的工具。
ack-prometheus-gpu-exporter是安装阿里云Prometheus组件后启动的一个DaemonSet类型的Pod。原因:DCGM内存泄漏是指在运行过程中,DCGM占用的内存未能被正确释放,导致内存使用量持续增加。
解决办法:当前DCGM可能会出现内存泄漏情况,已通过为
ack-prometheus-gpu-exporter所在的Pod设置resources.limits来规避这个问题。当内存使用达到limits限制时,ack-prometheus-gpu-exporter会重启(一般一个月左右重启一次),重启后将正常上报指标,但在重启后的几分钟内,Grafana可能会出现某些指标的显示异常(例如节点数突然变多),之后恢复正常。问题详情请参见The DCGM has a memory leak?。
ack-prometheus-gpu-exporter出现OOM Kill
背景:
ack-prometheus-gpu-exporter是安装阿里云Prometheus组件后启动的一个DaemonSet类型的Pod,可能导致开启监控出现问题。原因:由于ACK集群上的
ack-prometheus-gpu-exporter采用的是DCGM的embedding的模式,这种模式下DCGM会在多卡情况下占用较多的内存,且会出现内存泄露的问题。所以如果在具有多个GPU的实例上运行多个GPU进程,并且ack-prometheus-gpu-exporter分配的内存较少,可能会导致exporter Pod被OOM Kill。解决办法:这种情况下,通常等待Pod重启后即可重新上报Metrics。如果频繁的出现OOM Kill的情况,可以手动提升
arms-prom命名空间中DaemonSetack-prometheus-gpu-exporter的limits来解决这个问题。
ack-prometheus-gpu-exporter报错
背景:
ack-prometheus-gpu-exporter是安装阿里云Prometheus组件后启动的一个DaemonSet类型的Pod,报错可能导致监控出现问题。原因:若
ack-prometheus-gpu-exporter的Pod日志出现类似如下的报错信息:failed to get all process informations of gpu nvidia1,reason: failed to get gpu utilizations for all processes on device 1,reason: Not Found这是由于旧版本的
ack-prometheus-gpu-exporter在某些GPU卡上未运行具体任务时,无法获取相关容器的GPU指标。解决办法:此问题已在最新版本中修复。请升级ack-arms-prometheus组件到最新版本以解决该问题。