云原生AI套件是阿里云容器服务ACK提供的云原生AI技术和产品方案。使用云原生AI套件,您可以充分利用云原生架构和技术,在Kubernetes容器平台上快速定制化构建AI生产系统,并为AI/ML应用和系统提供全栈优化。本文介绍云原生AI套件产品架构、核心功能、使用场景、使用流程等内容。
产品架构
云原生AI套件以阿里云容器服务ACK为底座,向下封装对各类异构资源的统一管理,向上提供标准Kubernetes集群环境和API,以运行各核心组件,实现资源运维管理、AI任务调度和弹性伸缩、数据访问加速、工作流编排、大数据服务集成、AI作业生命周期管理、AI制品管理、统一运维等服务;再向上针对AI生产流程中的主要环节,支持AI数据集管理,AI模型开发、训练、评测,以及模型推理服务等。
您可以通过统一的命令行工具、多种语言SDK和控制台界面,直接使用各核心组件。您也可以灵活地进行扩展、组装或二次开发,快速定制化构建AI生产系统。通过同样的组件和工具,云原生AI套件也支持阿里云AI服务、开源AI框架和第三方AI能力的集成。
此外,云原生AI套件支持与阿里云人工智能平台 PAI无缝集成,提供高效、灵活的一站式AI平台。一方面,您可以直接使用PAI平台提供的DSW、DLC、EAS等服务。这些服务借助ACK为AI模型开发、训练和推理带来了更好的弹性和效率。另一方面,云原生AI套件支持在ACK集群中一键部署轻量化人工智能平台 PAI平台,降低AI使用门槛。在Kubernetes应用中,您可以灵活地集成PAI平台深度优化的算法和引擎,依托其最佳实践沉淀,极大优化训练与推理效果。关于人工智能平台 PAI的更多信息,请参见什么是人工智能平台 PAI。
云原生AI套件的产品架构如下图所示。

核心功能
云原生AI套件基于阿里云容器服务ACK,为AI/ML应用和系统提供了自底向上的全栈支持和优化。云原生AI套件有以下核心功能。
功能项 | 说明 | 相关文档 |
异构资源统一管理 |
| |
AI任务调度 |
| |
弹性调度 | 弹性调度分布式深度学习训练任务:训练过程中,支持动态伸缩子任务Worker实例数量和节点数量,同时基本维持整体训练进度和模型精度。在集群资源空闲时,支持增加更多Worker加速训练;在资源紧张时,释放部分Worker,以保证训练的基本运行进度。这种模式可以极大提升集群的总体利用率,避免计算节点故障影响,同时显著减少用户提交作业之后等待作业启动的时间。 | |
AI数据编排与加速 | Fluid:提出弹性数据集(Dataset)的概念。对“计算任务使用数据的过程”进行抽象,并创建数据编排与加速系统Fluid,以实现数据集管理、权限控制和访问加速等能力。ack-fluid组件支持将多个不同类型的存储服务作为数据源聚合到同一个Dataset中使用,还可以接入不同位置的存储服务实现混合云环境下的数据管理与访问加速。此外,ack-fluid组件可扩展兼容多种分布式缓存服务,为每个Dataset配置缓存服务,还提供数据集预热、缓存容量监控和弹性伸缩等功能,可以大大降低计算任务远程拉取数据的开销,提高GPU计算效率。 | |
AI作业生命周期管理 |
|
使用场景
云原生AI套件的核心场景包括持续优化异构资源效率、高效运行AI等异构工作负载。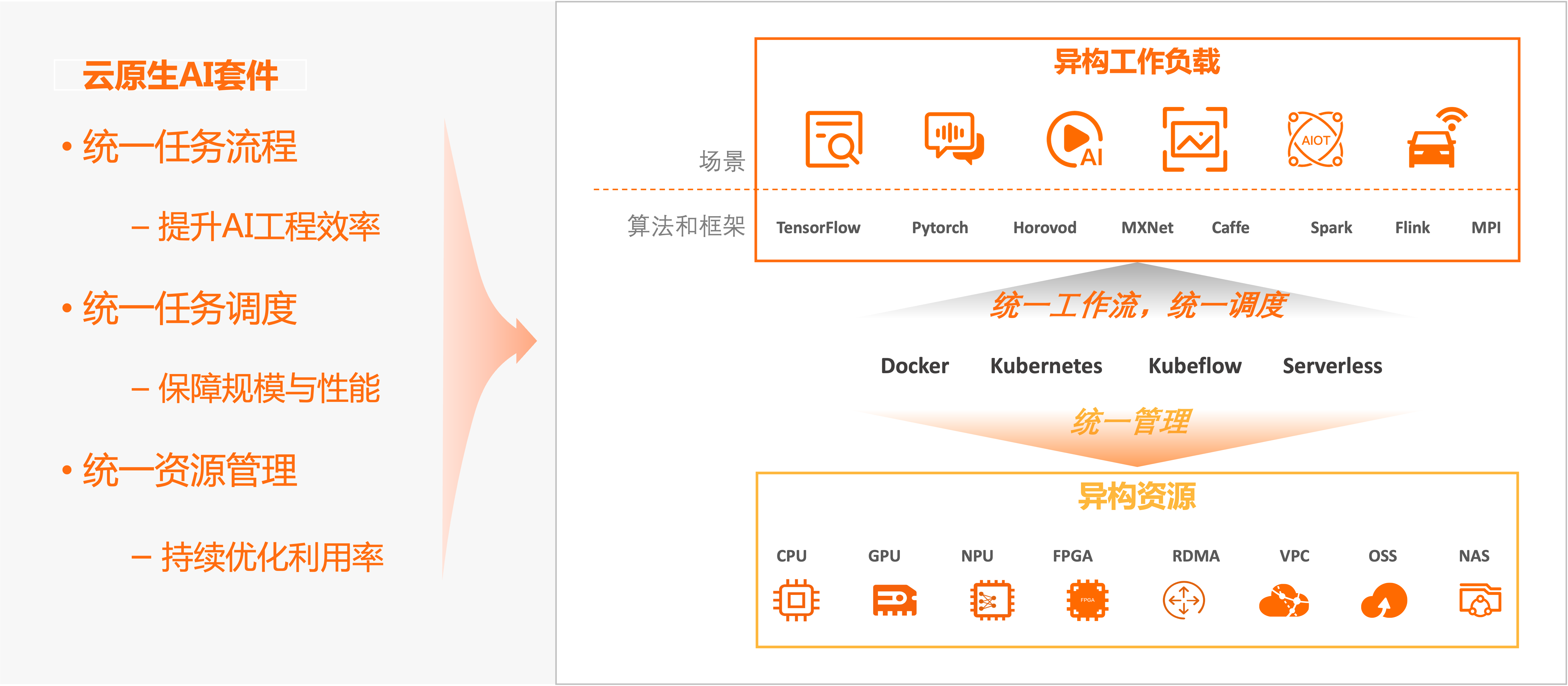
场景一:持续优化异构资源效率
对云上各种异构计算资源(如CPU、GPU、NPU、VPU、FPGA)、存储(OSS、NAS、CPFS、HDFS)、网络(TCP、RDMA)资源,云原生AI套件支持对其进行抽象,统一管理、运维和分配,通过弹性和软硬件协同优化,持续提升资源利用率。
场景二:高效运行AI等异构工作负载
云原生AI套件内置支持TensorFlow、PyTorch、DeepSpeed、Ray、Horovod、Spark、Flink、Kubeflow、KServe、vLLM、Triton inference server等主流开源或者用户自有的各种计算引擎和运行时,统一运行各类异构工作负载,统一管理作业生命周期,统一调度任务工作流,保证任务规模和性能。云原生AI套件一方面不断优化运行任务的性能、效率和成本,另一方面持续改善开发运维体验和工程效率。
用户角色
云原生AI套件存在两种用户角色。
角色类型 | 说明 |
运维管理员 | |
算法工程师、数据科学家 | 使用云原生AI套件管理任务。更多信息,请参见基于Kubernetes部署运行模型训练作业、对MLflow模型仓库中的模型进行管理、模型分析优化。 |
使用流程
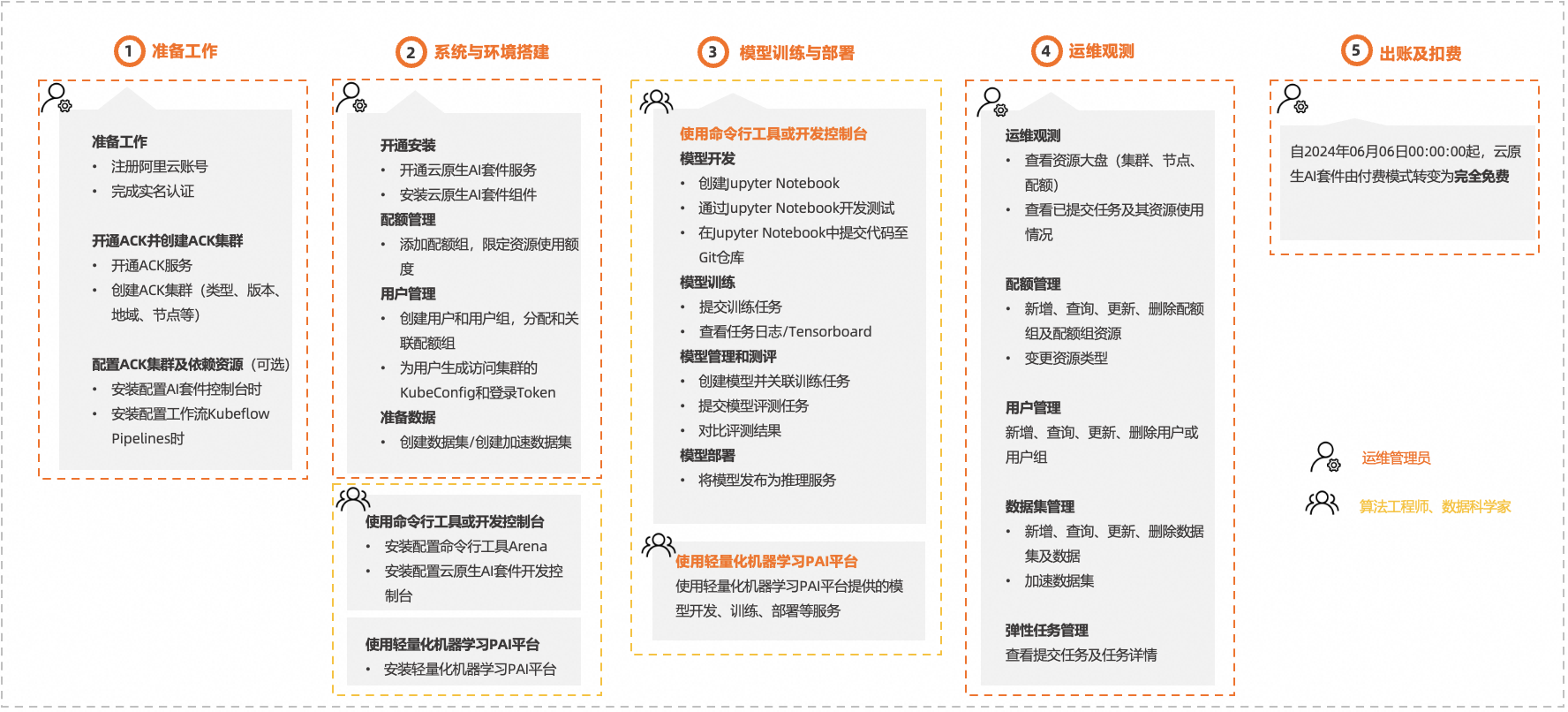
基于用户角色,云原生AI套件的使用流程如下图所示。
流程 | 说明 | 操作界面 |
1、准备工作 (运维管理员) | 注册账号 注册阿里云账号并完成实名认证。具体操作,请参见注册阿里云账号。 | |
创建ACK集群 开通ACK服务并创建ACK集群。推荐配置如下。关于配置的详情说明,请参见创建ACK托管集群。
| ||
配置ACK集群依赖项及创建依赖云资源(可选)
| ||
2、系统与环境搭建 (运维管理员) | 开通安装
| |
管理用户和配额
| AI运维控制台、kubectl 说明 阿里云提供的AI控制台(包括开发控制台、运维控制台)于2025年01月22日起以白名单功能的形式开放。如果您在白名单开放前已部署开发控制台或运维控制台,您的使用将不会受到影响。未加入白名单的用户,可以从开源社区安装配置AI套件控制台。关于开源配置的详细操作,请参见开源AI控制台。 | |
准备数据
| ||
(算法工程师、数据科学家) | 云原生AI套件支持命令行工具Arena、Web控制台和一站式AI平台等多种方式,帮助算法工程师和数据科学家进行模型开发、训练、推理和任务管理。
| |
3、模型训练与部署 (算法工程师、数据科学家) | 使用云原生AI套件提供的命令行工具Arena或AI套件开发控制台时,模型训练与部署如下。 模型开发
模型训练
模型管理
模型部署 将模型发布为推理服务。更多信息,请参见AI服务部署。 | AI开发控制台、Arena |
使用轻量化人工智能平台 PAI提供的模型开发、训练、部署等服务。 | ||
4、运维观测 (运维管理员) | 运维观测 查看资源大盘,包括集群、节点、训练任务、资源配额等监控大盘。更多信息,请参见使用云原生AI监控大盘。 | |
配额管理
| ||
用户管理 | ||
数据集管理 | ||
弹性任务管理 查看提交的弹性任务及任务详情。具体参照,请参见查看弹性任务。 | ||
5、出账及扣费 (运维管理员) | 自2024年06月06日00:00:00起,由付费模式转变为免费开放。更多信息,请参见云原生AI套件计费说明。 | |
按天出账
|
产品计费
关于云原生AI套件的计费详情,请参见云原生AI套件计费说明。
更多信息
信息项 | 说明 |
通过简单的实践,带您体验和了解如何使用云原生AI套件进行开发或运维。 | |
介绍云原生AI套件相关内容的最新动态。 |