云数据库HBase增强版支持冷热分离功能,可以将冷热数据存储在不同的介质中,有效提升热数据的查询效率,同时降低数据存储成本。
背景信息
在海量大数据场景下,一张表中的部分业务数据随着时间的推移仅作为归档数据或者访问频率很低,同时这部分历史数据体量非常大,比如订单数据或者监控数据,降低这部分数据的存储成本将会极大的节省企业的成本。因此,如何以极简的运维配置最大程度地降低存储成本,成为了数据库产品新的课题。为实现这一目标,阿里云HBase增强版冷热分离功能应运而生。阿里云HBase增强版为冷数据提供新的存储介质,新的存储介质存储成本仅为高效云盘的1/3。
HBase增强版在同一张表里实现了数据的冷热分离,系统会自动根据用户设置的冷热分界线自动将表中的冷数据归档到冷存储中。在用户的访问方式上和访问普通表没有任何差异,在查询的过程中,用户只需配置查询的Hint或者TimeRange,系统会根据条件自动地判断数据应该在热数据区还是冷数据区。
原理介绍
用户在表上配置数据冷热时间分界点后,HBase增强版会依赖用户写入数据的时间戳(毫秒)和时间分界点来判断数据的冷热。数据开始存储在热存储上,随意时间的推移慢慢往冷存储上迁移。同时用户可以任意变更数据的冷热分界点,数据可以从热存储到冷存储,也可以从冷存储到热存储。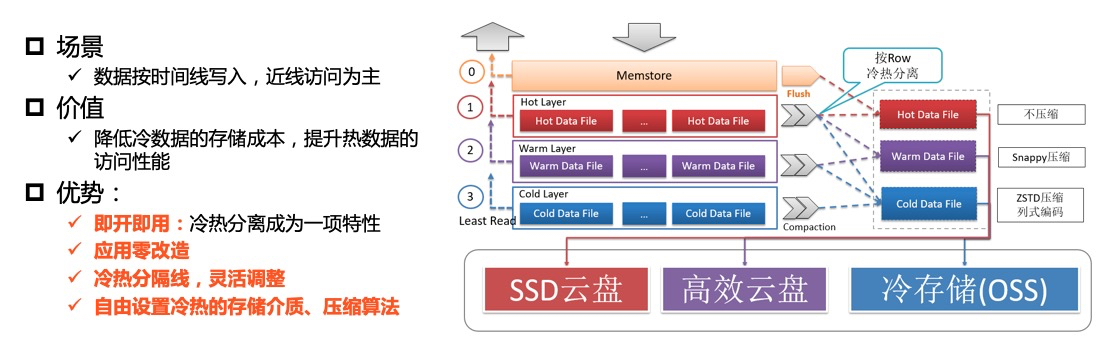
注意事项
参见使用冷存储中的注意事项。
使用方法
冷存储功能需要HBase增强版服务端升级到2.1.8及以上版本,但无需修改数据读写链路的客户端依赖,只需要选择以下一种方式修改表结构即可:
使用Java API:要求AliHBase-Connector 1.0.7/2.0.7以上,请参考使用Java API访问增强版集群中的步骤完成Java SDK安装和参数配置。
使用HBase Shell:要求alihbase-2.0.7-bin.tar.gz以上,请按照使用HBaseue Shell访问增强版集群中的步骤完成Shell的下载和配置。
开通冷存储功能
请参照使用冷存储开通集群的冷存储功能。
为表设置冷热分界线
用户在使用过程中可以随时调整COLD_BOUNDARY来划分冷热的边界。COLD_BOUNDARY的单位为秒,如COLD_BOUNDARY => 86400 代表86400秒(一天)前写入的数据会被自动归档到冷存储介质上。
在冷热分离使用过程中,无需把列簇的属性设置为COLD,如果已经把列簇的属性设置为了COLD,请参见使用冷存储将冷存储的属性去除。
Shell
// 创建冷热分离表
hbase(main):002:0> create 'chsTable', {NAME=>'f', COLD_BOUNDARY=>'86400'}
// 取消冷热分离
hbase(main):004:0> alter 'chsTable', {NAME=>'f', COLD_BOUNDARY=>""}
// 为已经存在的表设置冷热分离,或者修改冷热分离分界线,单位为秒
hbase(main):005:0> alter 'chsTable', {NAME=>'f', COLD_BOUNDARY=>'86400'}Java API方式
// 新建冷热分离表
Admin admin = connection.getAdmin();
TableName tableName = TableName.valueOf("chsTable");
HTableDescriptor descriptor = new HTableDescriptor(tableName);
HColumnDescriptor cf = new HColumnDescriptor("f");
// COLD_BOUNDARY 设置冷热分离时间分界点,单位为秒, 示例表示1天之前的数据归档为冷数据
cf.setValue(AliHBaseConstants.COLD_BOUNDARY, "86400");
descriptor.addFamily(cf);
admin.createTable(descriptor);
// 取消冷热分离
// 注意:需要做major compaction,数据才能从冷存储上回到热存储上
HTableDescriptor descriptor = admin
.getTableDescriptor(tableName);
HColumnDescriptor cf = descriptor.getFamily("f".getBytes());
// 取消冷热分离
cf.setValue(AliHBaseConstants.COLD_BOUNDARY, null);
admin.modifyTable(tableName, descriptor);
// 为已经存在的表设置冷热分离功能,或者修改冷热分离分界线
HTableDescriptor descriptor = admin
.getTableDescriptor(tableName);
HColumnDescriptor cf = descriptor.getFamily("f".getBytes());
// COLD_BOUNDARY 设置冷热分离时间分界点,单位为秒, 示例表示1天之前的数据归档为冷数据
cf.setValue(AliHBaseConstants.COLD_BOUNDARY, "86400");
admin.modifyTable(tableName, descriptor);数据写入
冷热分离的表与普通表的数据写入方式完全一致,用户可以参照使用Java API访问增强版集群文档中的方式或者使用多语言API访问对表进行数据写入。数据的写入的时间戳使用的是当前时间。数据先会存储在热存储(云盘)中。随着时间的推移,如果这行数据的写入时间超过COLD_BOUNDARY设置的值,就会在major_compact时归档到冷数据,此过程完全对用户透明。
数据查询
由于冷热数据都在同一张表中,用户全程只需要和一张表交互。在查询过程中,如果用户明确知道需要查询的数据在热数据里(写入时间少于COLD_BOUNDARY设置的值),可以在Get或者Scan上设置HOT_ONLY的Hint来告诉服务器只查询热区数据。或者在Get/Scan上设置TimeRange来限定查询数据的时间,系统会根据设置TimeRange决定是查询热区,冷区还是冷热都查。查询冷区数据延迟要比热区数据延迟高的多,并且查询吞吐受到冷存储限制。
查询示例
Get
Shell
// 不带HotOnly Hint的查询,可能会查询到冷数据 hbase(main):013:0> get 'chsTable', 'row1' // 带HotOnly Hint的查询,只会查热数据部分,如row1是在冷存储中,该查询会没有结果 hbase(main):015:0> get 'chsTable', 'row1', {HOT_ONLY=>true} // 带TimeRange的查询,系统会根据设置的TimeRange与COLD_BOUNDARY冷热分界线进行比较来决定查询哪个区域的数据(注意TimeRange的单位为毫秒时间戳) hbase(main):016:0> get 'chsTable', 'row1', {TIMERANGE => [0, 1568203111265]}Java
Table table = connection.getTable("chsTable"); // 不带HotOnly Hint的查询,可能会查询到冷数据 Get get = new Get("row1".getBytes()); System.out.println("result: " + table.get(get)); // 带HotOnly Hint的查询,只会查热数据部分,如row1是在冷存储中,该查询会没有结果 get = new Get("row1".getBytes()); get.setAttribute(AliHBaseConstants.HOT_ONLY, Bytes.toBytes(true)); // 带TimeRange的查询,系统会根据设置的TimeRange与COLD_BOUNDARY冷热分界线进行比较来决定查询哪个区域的数据(注意TimeRange的单位为毫秒时间戳) get = new Get("row1".getBytes()); get.setTimeRange(0, 1568203111265)
Scan
如果scan不设置Hot Only,或者TimeRange包含冷区时间,则会并行访问冷数据和热数据来合并结果,这是由于HBase的Scan原理决定的。
Shell
// 不带HotOnly Hint的查询,一定会查询到冷数据 hbase(main):017:0> scan 'chsTable', {STARTROW =>'row1', STOPROW=>'row9'} // 带HotOnly Hint的查询,只会查询热数据部分 hbase(main):018:0> scan 'chsTable', {STARTROW =>'row1', STOPROW=>'row9', HOT_ONLY=>true} // 带TimeRange的查询,系统会根据设置的TimeRange与COLD_BOUNDARY冷热分界线进行比较来决定查询哪个区域的数据(注意TimeRange的单位为毫秒时间戳) hbase(main):019:0> scan 'chsTable', {STARTROW =>'row1', STOPROW=>'row9', TIMERANGE => [0, 1568203111265]}
Java
TableName tableName = TableName.valueOf("chsTable"); Table table = connection.getTable(tableName); // 不带HotOnly Hint的查询,一定会查询到冷数据 Scan scan = new Scan(); ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println("scan result:" + result); } // 带HotOnly Hint的查询,只会查询热数据部分 scan = new Scan(); scan.setAttribute(AliHBaseConstants.HOT_ONLY, Bytes.toBytes(true)); // 带TimeRange的查询,系统会根据设置的TimeRange与COLD_BOUNDARY冷热分界线进行比较来决定查询哪个区域的数据(注意TimeRange的单位为毫秒时间戳) scan = new Scan(); scan.setTimeRange(0, 1568203111265);
冷热分离表中的冷区只是用来归档数据,查询请求应该非常的少,用户查询冷热分离表的绝大部分请求应该带上HOT_ONLY的标记(或者设置的TimeRange只在热区)。如果用户有大量请求需要去查冷区数据,则可能得考虑COLD_BOUNDARY冷热分界线的设置是否合理。
如果一行数据已经在冷数据区域,但这一行后续有更新,更新的字段先会在热区,如果设置HOT_ONLY去查询这一行(或者设置的TimeRange只在热区),则只会返回这一行更新的字段(在热区)。只有在查询时去掉HOT_ONLY Hint,去掉TimeRange,或保证TimeRange覆盖了该行数据插入和更新时间,才能完整返回这一行。因此不建议对已经进入冷区的数据进行更新,如果有频繁更新冷数据的需求,则可能得考虑COLD_BOUNDARY冷热分界线的设置是否合理。
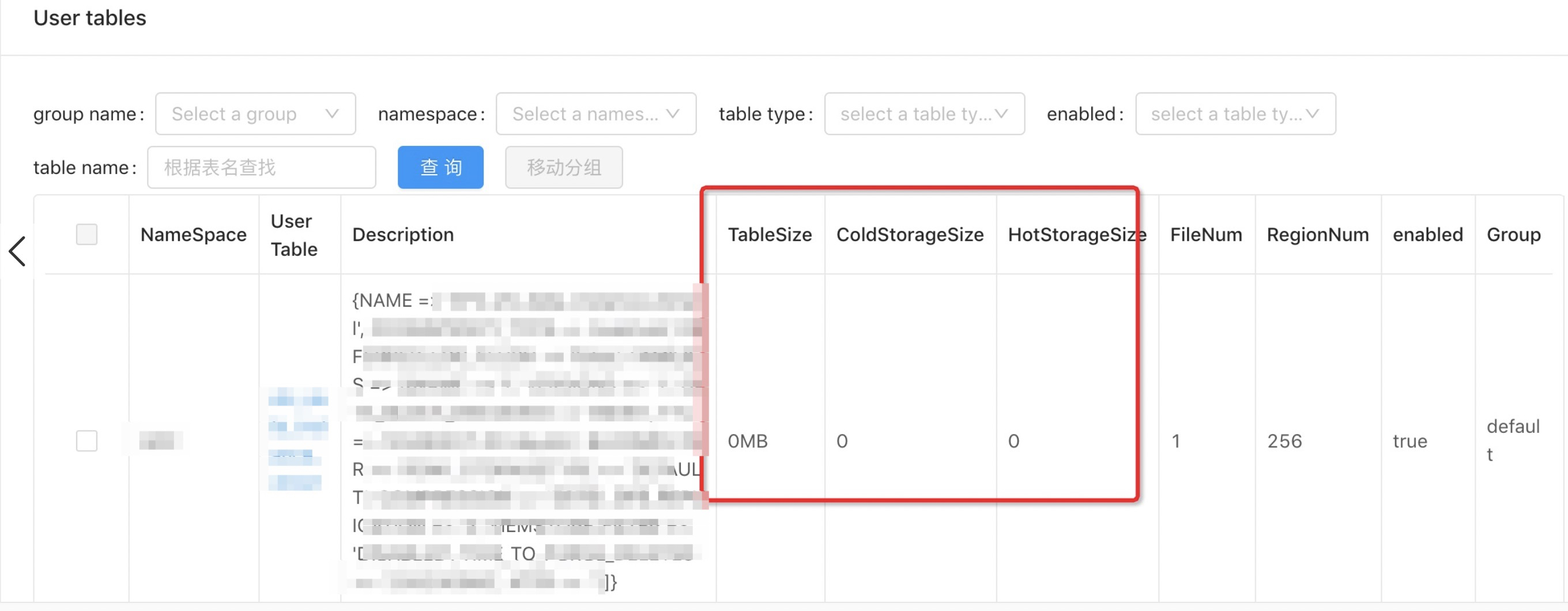
查看表中冷数据和热数据的大小
在集群管理系统的表Tab中,可以显示某一张表的冷存储使用大小和热存储使用大小。
如果数据还没有进入冷存储,有可能数据还在内存中,请执行flush,将数据刷写到盘上,再请执行major_compact完成后再查看。
优先查询热数据
在范围查询(Scan)场景下,查询的数据可能横跨冷热区,比如查询一个用户的所有订单、聊天记录等。但查询的结果往往是从新到旧的分页展示,最先展示的是最近的热数据。在这个场景下,普通的Scan(不带Hot_Only)会并行地扫描冷热数据,导致请求性能下降。而在开启了优先查询热数据后,会优先只查热数据,只有热数据的条数不够显示(如用户点了下一页查看),才会去查询冷数据,减少冷存储的访问,提升请求响应。
开启热数据优先查询,只需在Scan上设置COLD_HOT_MERGE属性即可。该属性的含义是优先查询热存储中的数据, 若热存储中的数据查完了,用户仍然在调用next获取下一条数据,则会开始查询冷数据。
Shell
hbase(main):002:0> scan 'chsTable', {COLD_HOT_MERGE=>true}Java
scan = new Scan();
scan.setAttribute(AliHBaseConstants.COLD_HOT_MERGE, Bytes.toBytes(true));
scanner = table.getScanner(scan);若某一行同时包含热数据和冷数据(部分列属于热数据,部分列属于冷数据,比如部分列更新场景),开启热数据优先功能,会使得该行的查询结果会分两次返回,即scanner返回的Result集合中,对于同一个Rowkey会有两个对应的Result。
由于是先返回热数据,再返回冷数据,开启热数据优先功能后,无法保证后返回的冷数据结果的Rowkey一定大于先返回的热数据结果的Rowkey,即Scan得到的Result集不保序, 但热数据和冷数据的各自返回集仍保证按Rowkey有序排列(参见下面的demo)。在部分实际场景中, 用户可以通过Rowkey设计,保障scan的结果仍然保序,比如订单记录表,Rowkey=用户ID+订单创建时间,扫描某个用户的订单数据是有序的。
//假设rowkey为"coldRow"的这一行是冷数据,rowkey为"hotRow"的这一行为热数据
//正常情况下,由于hbase的row是字典序排列,rowkey为"coldRow"的这一行会比"hotRow"这一行先返回。
hbase(main):001:0> scan 'chsTable'
ROW COLUMN+CELL
coldRow column=f:value, timestamp=1560578400000, value=cold_value
hotRow column=f:value, timestamp=1565848800000, value=hot_value
2 row(s)
// 设置COLD_HOT_MERGE时, scan的rowkey顺序被破坏,热数据比冷数据先返回,因此返回的结果中,"hot"排在了"cold"的前面
hbase(main):002:0> scan 'chsTable', {COLD_HOT_MERGE=>true}
ROW COLUMN+CELL
hotRow column=f:value, timestamp=1565848800000, value=hot_value
coldRow column=f:value, timestamp=1560578400000, value=cold_value
2 row(s)