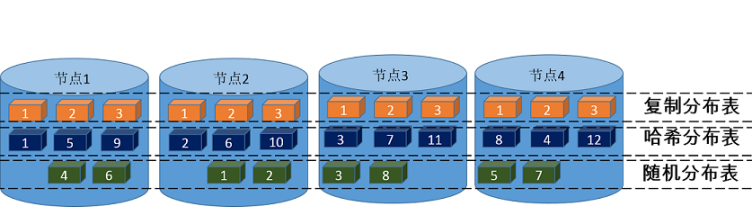
AnalyticDB PostgreSQL版支持三种数据在节点间的分布方式,分别是哈希(HASH)分布、随机(RANDOMLY)分布、复制(REPLICATED)分布。
语法
CREATE TABLE table_name (...) [ DISTRIBUTED BY (column [,..] ) | DISTRIBUTED RANDOMLY | DISTRIBUTED REPLICATED ]哈希分布
DISTRIBUTED BY (column, [ ... ])数据将根据分布列的哈希值将各个行分布到指定计算节点上,相同的哈希值会始终散列到同一计算节点。为保障数据可以均匀分布在各个节点上,建议您选择唯一键(例如主键)作为分布键。
AnalyticDB PostgreSQL版的默认分布策略为哈希分布,如果建表时未指定DISTRIBUTED子句,系统会选择主键或表的第一个合适的列作为分布键。如果表中没有合适的列,系统将会使用随机分布策略。
建表语句示例如下:
CREATETABLEproducts
(namevarchar(40),
prod_idinteger,
supplier_idinteger)DISTRIBUTEDBY(prod_id);随机分布
DISTRIBUTED RANDOMLY系统会按循环的方式将数据分布到各个计算节点上,但是相同值的数据可能不会分布到同一个计算节点。
随机分布仅建议您在没有合适的列作为分布列时使用。
建表语句示例如下:
CREATETABLErandom_stuff(thingstext,
doodadstext,
etctext)DISTRIBUTEDRANDOMLY;复制分布
DISTRIBUTED REPLICATED系统会在每个计算节点都保存一份表的全量数据。
如果数据库中存在大表与小表join的场景,您可以将足够小的表设置为复制分布来提升性能。
建表语句示例如下:
CREATETABLEreplicated_stuff(thingstext,
doodadstext,
etctext)DISTRIBUTEDREPLICATED;创建了一个复制(Replicated)分布的表,每个 Segment 数据节点都存储有一个全量的表数据。