为解决因容器引擎层的不透明性而导致的故障排查困难问题,阿里云容器服务 Kubernetes 版 ACK(Container Service for Kubernetes)推出SysOM工具,通过提供操作系统内核层的容器监控数据,增强了对容器内存问题的可观测性。这使您能够更透明地查看和诊断容器引擎层的问题,从而更顺利地进行容器化迁移。本文介绍如何使用SysOM定位容器内存问题。
前提条件
-
已创建ACK托管版集群或自2021年10月以后创建的ACK Serverless集群,并确保集群版本为1.18.8及以上。如需升级集群,请参见手动升级集群。
-
已开启阿里云Prometheus监控。
-
已开启ack-sysom-monitor监控功能。具体操作,请参见开启ack-sysom-monitor监控功能。
ack-sysom-monitor监控功能费用说明
启用ack-sysom-monitor监控功能后,相关组件会自动将监控指标发送至阿里云Prometheus服务,这些指标将被视为自定义指标。使用自定义指标会引起额外的费用。
为避免产生额外的费用,建议在启用此功能前,仔细阅读阿里云Prometheus的计费概述,了解自定义指标的收费策略。费用将根据您的集群规模和应用数量等因素产生变动。您可以通过资源消耗统计功能,监控和管理您的资源使用情况。
场景描述
容器化因其降低成本、提高效率的优势,以及提供的灵活性和可扩展性,已成为企业IT架构的最佳实践。
但容器化也引入了容器引擎层的不透明性,导致内存占用过高甚至超出限制,从而触发OOM(Out of Memory)问题。
阿里云容器服务 Kubernetes 版 ACK(Container Service for Kubernetes)团队联合阿里云GuestOS操作系统团队,通过操作系统内核层的容器监控能力,实现内存使用的精准管控,避免由此引发的OOM问题。
容器内存组成
容器的内存由应用程序内存、内核内存和空闲内存组成。
|
内存大类 |
内存小类 |
说明 |
|
应用程序内存(Application Memory) |
应用程序内存由以下几个部分组成:
|
应用程序运行时所使用的内存。 |
|
内核内存(Kernel Memory) |
内核内存由以下几个部分组成:
|
操作系统内核使用的内存。 |
|
空闲内存(Free Memory) |
不涉及。 |
未被使用的可用内存。 |
实现原理
Kubernetes 采用内存工作集(Workingset)来监控和管理容器的内存使用。当容器的内存消耗超过设定的限制或节点面临内存压力时,Kubernetes 会基于 Workingset 来判断是否需要驱逐或终止容器。通过 SysOM 监控 Pod 的 Workingset,可以提供更为全面和精准的内存监控与分析能力,帮助运维和开发人员迅速定位并解决 Workingset 过高的问题,从而提升容器的性能和稳定性。
内存工作集(Workingset)指的是在一定时间范围内,容器实际使用的内存部分,即容器当前运行所需的内存。具体计算公式为 Workingset = InactiveAnon + ActiveAnon + ActiveFile,其中 InactiveAnon 和 ActiveAnon 代表程序匿名内存的总大小,而 ActiveFile 代表应用程序活跃文件缓存的大小。通过这样的监控和分析,运维人员可以更有效地管理资源,确保应用程序的持续稳定运行。
使用SysOM功能
基于阿里云SysOM提供的操作系统内核层Pod、Node维度监控大盘,您可以实时监控内存、网络、存储等的系统层指标。SysOM功能的详细指标信息,请参见SysOM内核层容器监控。
-
登录容器服务管理控制台,在左侧导航栏选择集群列表。
-
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
-
在Prometheus 监控页面,单击SysOM 系统观测页签,然后单击SysOM容器系统监控-Pod维度页签,查看监控大盘的Pod内存数据。
根据计算公式,分析如何定位内存黑洞问题。
Pod总内存 = RSS 常驻内存 + Cache(缓存)≈ inactive_anon+active_anon+inactive_file+active_file
Workingset = inactive_anon + active_anon + active_file
-
在Pod Memory Monitor区域,根据Pod总内存公式,可以先将Pod内存分为cache和rss内存,然后将cache分为active_file、inactive_file和shmem(共享内存)三种类型占比,rss内存分为active_anon和inactive_anon两种类型占比。
如下图所示,inactive_anon内存大小占比最大。
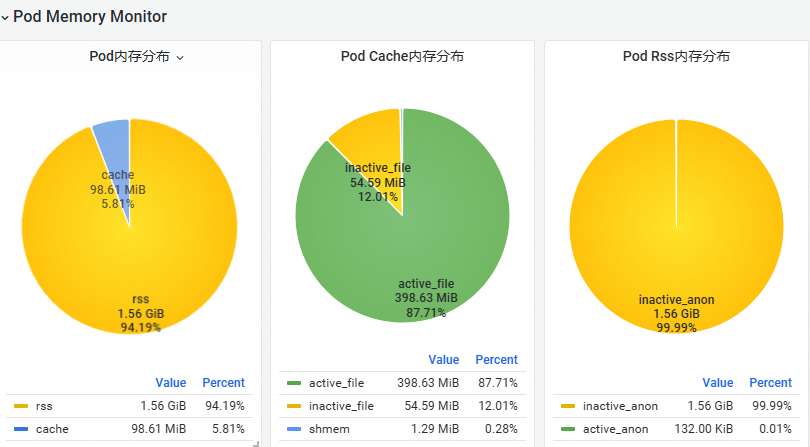
-
在Pod Resource Analysis区域,通过Top工具快速定位集群中InactiveAnon内存消耗最大的Pod。
如下图所示,arms-prom的内存消耗最大。
表格按 InactiveAnon大小 降序排列,显示 arms-prometheus Pod 的 InactiveAnon 大小为 494 MiB、占比 99.4%,远高于 kube-system 命名空间下的其他 Pod。
-
在Pod内存详情区域,查看Pod的详细内存组成。通过Pod Cache(缓存内存)、InactiveFile(非活跃文件内存占用)、InactiveAnon(非活跃匿名内存占用)、Dirty Memory(系统脏内存占用)等不同内存成分的监控展示,发现常见的Pod内存黑洞问题。
表格还展示了各Pod的 Namespace、PodName、Usage量(内存使用量)、PageFault增量和PageFault总量,支持按列头排序,默认按 Usage量 降序排列。
-
-
在Pod File Cache区域,查看产生较大缓存内存的原因。
若Pod的内存缓存较大,可能导致Pod工作内存占用升高,这部分缓存的内存会成为Pod工作内存的黑洞,最终影响Pod所在的业务体验。
Pod File Cache 表格包含 Namespace、PodName、Container、File、内存缓存大小和文件总大小列,默认按文件总大小降序排列,可据此定位缓存占用最大的 Pod 及其对应文件。
-
修复内存黑洞问题。
通过观测发现容器内存黑洞问题,即可通过ACK精细化调度功能进行闭环修复。具体操作,请参见启用容器内存QoS。
相关文档
-
关于SysOM功能的详细指标信息,请参见SysOM内核层容器监控。
-
关于ACK容器内存QoS启用的内核能力,请参见内核功能与接口概述。