本文介紹Tablestore的系統架構和典型應用架構。
系統架構
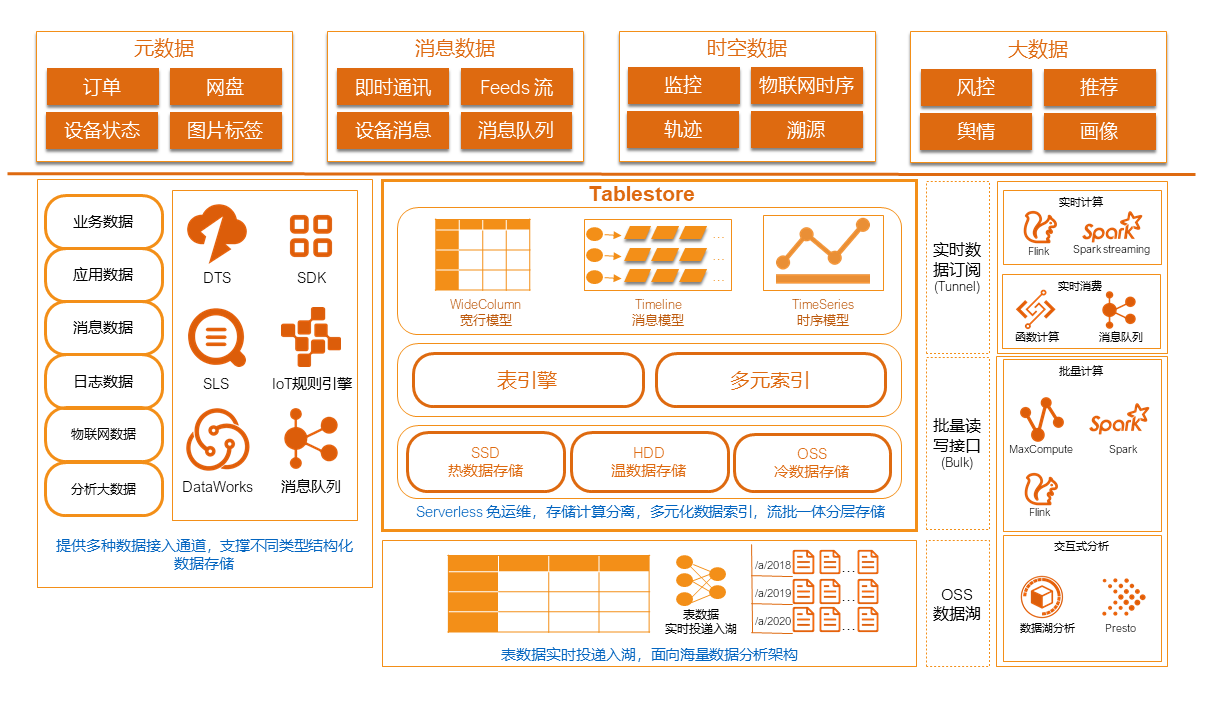
Tablestore的架構如下圖所示。
業務情境
Tablestore適用於中繼資料、訊息資料、時空資料、巨量資料等情境下的系統搭建。
資料接入
Tablestore提供SDK、DataWorks、IoT規則引擎等多種資料接入方式,支撐應用資料、訊息資料、物聯網資料等不同業務類型結構化資料的儲存。
Tablestore
多模型資料存放區
Tablestore針對不同業務類型的結構化資料提供了寬表(WideColumn)模型、時序(TimeSeries)模型和訊息(Timeline)模型三種資料存放區模型。
模型
描述
寬表模型
類Bigtable/HBase模型,可應用於中繼資料、巨量資料等多種情境,支援資料版本、生命週期、主鍵列自增、條件更新、局部事務、原子計數器、過濾器等功能。更多資訊,請參見寬表模型。
時序模型
針對時間序列資料的特點進行設計的模型,可應用於物聯網裝置監控、裝置採集資料、機器監控資料等情境,支援自動構建時序中繼資料索引、豐富的時序查詢能力等功能。更多資訊,請參見時序模型。
訊息模型
針對訊息資料情境設計的模型,可應用於IM、Feed流等訊息情境。能滿足訊息情境對訊息保序、海量訊息儲存、即時同步的需求,同時支援全文檢索索引與多維度組合查詢。更多資訊,請參見訊息模型。
多元化資料索引
除了支援主鍵查詢,Tablestore還支援二級索引和多元索引的索引方式,提供強大的資料查詢能力。
索引類型
描述
資料表主鍵
資料表類似於一個巨大的Map,它的查詢能力也就類似於Map,只能通過主鍵查詢。
二級索引
通過建立一張或多張索引表,使用索引表的主鍵列查詢,相當於把資料表的主鍵查詢能力擴充到了不同的列。
多元索引
使用了倒排索引、BKD樹、列存等結構,具備豐富的查詢能力,例如非主鍵列的條件查詢、多條件組合查詢、地理位置查詢、全文檢索索引、模糊查詢、嵌套結構查詢、統計彙總等。
冷熱階層式存放區
資料存放區支援自動冷熱分層,同時Tablestore支援高效能執行個體和容量型執行個體兩種執行個體規格來滿足不同業務的資料存放區需求。
執行個體規格
描述
高效能執行個體
適用於對讀寫效能和並發都要求非常高的情境,例如遊戲、金融風控、社交應用、推薦系統等。
容量型執行個體
適用於對讀效能不敏感,但對成本較為敏感的業務,例如日誌監控資料、車連網資料、裝置資料、時序資料、物流資料、輿情監控等。
資料湖投遞
將表資料全量備份或即時投遞資料到資料湖OSS中儲存。投遞的資料相容開源生態標準,按照Parquet列存格式儲存,相容Hive命名規範。您可以使用E-MapReduce直接對投遞到OSS的資料進行外表分析。
計算生態對接
支援對接主流開源流批次計算引擎,包括Flink、Spark、Presto等。
與阿里巨量資料平台生態組件有較完善的對接,包括DataWorks、DataHub、MaxCompute等。
典型應用架構
根據使用情境不同,Tablestore有互連網應用架構、資料湖架構和物聯網架構三種典型應用架構。
互連網應用架構
互連網應用架構包括資料庫分層架構和分布式結構化資料存放區架構,主要用於電商訂單、直播彈幕、網盤中檔案中繼資料、社交網路中即時通訊等情境。
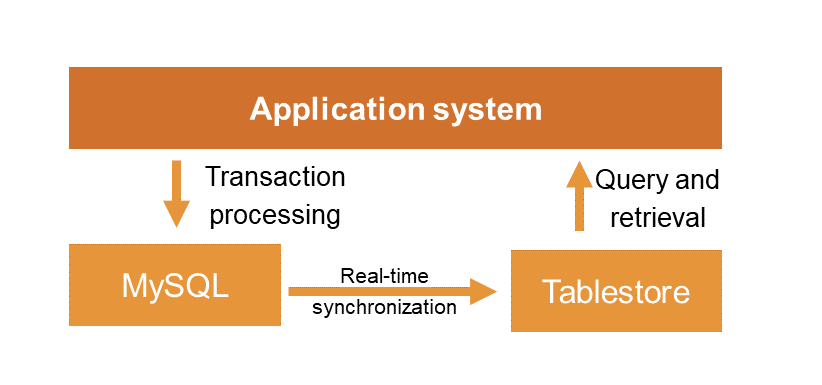
資料庫分層架構
在資料庫分層架構中,使用Tablestore配合MySQL來完成應用系統的業務需求,利用MySQL的事務能力來處理對事務強需求的寫操作與部分讀操作,利用Tablestore的資料檢索能力和巨量資料儲存來實現資料存放區、查詢與分析。
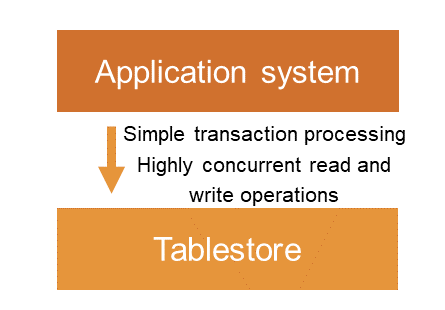
分布式結構化資料存放區架構
在分布式結構化資料存放區架構中,Tablestore直連應用系統實現簡單的交易處理和高並發資料讀寫。
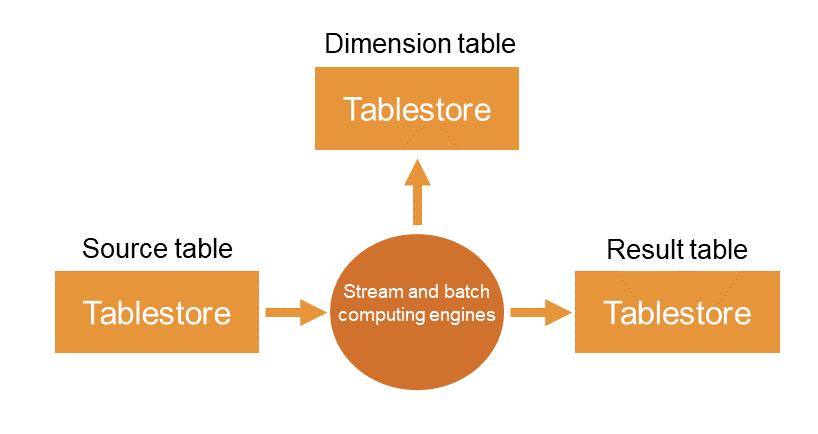
資料湖架構
資料湖架構主要用於資料中台、推薦系統、風控系統等情境。
在資料湖架構中,Tablestore作為源表、結果表或者維表對接流批次計算引擎實現巨量資料計算與分析。
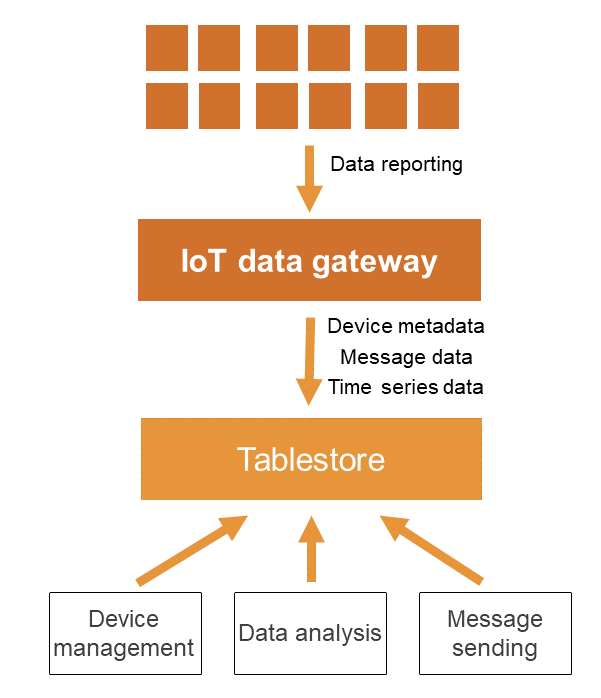
物聯網架構
物聯網架構主要用於車連網、智能家電、工業物聯網、物流等情境。
在物聯網架構中,Tablestore作為IoT基礎設施中的統一資料存放區平台來儲存物聯網平台相關的時序資料、中繼資料、訊息資料等,並提供豐富的資料分析處理能力。