LogStore中的時序資料通過SPL指令處理後,可以調用時序SPL函數進行結果可視化。
函數列表
函數名稱 | 說明 |
時間轉換函式:將秒級時間戳記轉為納秒級,適用於高精度情境。 | |
時間序列預測函數:基於歷史資料預測未來趨勢,適用於監控、分析和規劃。 | |
異常檢測函數:基於機器學習演算法,識別時間序列中的異常點或異常模式,適用於監控、警示和資料分析等情境。 | |
時間序列分解與異常檢測函數:基於時間序列分解演算法,將未經處理資料拆分為趨勢、季節性和殘差分量,並通過統計方法分析殘差分量以識別異常點,適用於即時監控、根因分析及資料品質檢測等情境。 | |
用於時間序列分析的下鑽函數,允許在時間分組統計的基礎上,進一步對特定時間段內的資料進行細粒度分析。 | |
支援對多條時間序列(或向量資料)進行快速分組分析,識別相似形態的指標曲線、檢測異常模式或歸類資料模式。 | |
一種用於時間序列分析的函數。該函數從多個維度對時間序列進行分析並返回結果,具體包括:資料是否連續、資料缺失情況、序列是否穩定、序列是否具有周期性及周期長度、以及序列是否存在顯著趨勢。 | |
用於計算兩個對象之間的相似性。具體功能包括: 1. 如果兩個對象均為單個向量,返回兩序列的相似性。 2. 如果一個對象是向量組,另一個是單個向量,返迴向量組中每個向量與該單個向量的相似性。 3. 如果兩個對象均為向量組,返回兩組向量之間兩兩相似性的矩陣。 |
second_to_nano函數
時間轉換函式,用於將秒級時間戳記轉換為納秒級時間戳記。它通常用於處理日誌中的時間欄位,尤其是在需要更高精度時間戳記的情境下。
精度:確保資料庫和應用程式支援足夠的精度,以處理納秒層級的時間資料。
資料類型:需要選擇合適的資料類型來儲存納秒級的資料,比如
BIGINT,以避免溢出或精度丟失。
文法
second_to_nano(seconds)參數說明
參數 | 說明 |
seconds | 秒級時間戳記(可以是整數或浮點數)。 |
傳回值
返回對應的納秒級時間戳記(以整數形式表示)。
樣本
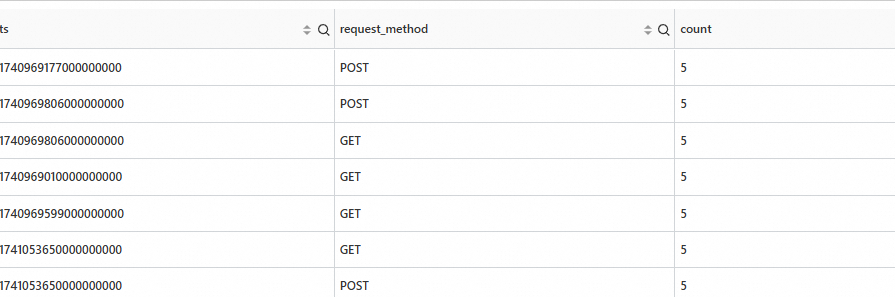
統計不同時間段(納秒級)不同請求的數量。
查詢分析語句
* | extend ts = second_to_nano(__time__) | stats count=count(*) by ts,request_method輸出結果
series_forecast函數
用於時間序列預測。它基於歷史時間序列資料,利用機器學習演算法對未來的時間點進行預測。該函數常用於監控、趨勢分析和容量規劃等情境。
使用限制
已經通過make-series構造出series格式資料,並且時間單位為納秒。
每行的時間點數量至少為31個 。
文法
series_forecast(array(T) field, bigint periods)或
series_forecast(array(T) field, bigint periods, varchar params)參數說明
參數 | 說明 |
field | 輸入時間序列的指標列。 |
periods | 期望預測結果中時間點的數量。 |
params | 可選。演算法參數,json 格式。 |
傳回值
row(
time_series array(bigint),
metric_series array(double),
forecast_metric_series array(double),
forecast_metric_upper_series array(double),
forecast_metric_lower_series array(double),
forecast_start_index bigint,
forecast_length bigint,
error_msg varchar)列名 | 類型 | 說明 |
time_series | array(bigint) | 納秒級時間戳記數組。包含輸入時間段的時間戳記和預測時間段的時間戳記。 |
metric_series | array(double) | metric 數組,長度和 time_series 一致。 對原始輸入 metric 進行修改(修改 NaN 等)並用 NaN 擴充預測時間段。 |
forecast_metric_series | array(double) | 預測結果數組,長度和 time_series 一致。 包含對輸入 metric 的擬合值以及預測時間段的預測值。 |
forecast_metric_upper_series | array(double) | 預測結果上界數組,長度和 time_series 一致。 |
forecast_metric_lower_series | array(double) | 預測結果下界數組,長度和 time_series 一致。 |
forecast_start_index | bigint | 表示時間戳記數組中預測時間段的起始下標。 |
forecast_length | bigint | 表示時間戳記數組中預測時間段時間點的數量。 |
error_msg | varchar | 錯誤資訊。為 null 則表示該行時間序列預測成功,否則展示失敗原因。 |
樣本
統計不同request_method接下來10個時間點的數量。
SPL語句
* | extend ts = second_to_nano(__time__ - __time__ % 60) | stats latency_avg = max(cast(status as double)), inflow_avg = min(cast (status as double)) by ts, request_method | make-series latency_avg default = 'last', inflow_avg default = 'last' on ts from 'min' to 'max' step '1m' by request_method | extend test=series_forecast(inflow_avg, 10)輸出結果

演算法參數
參數 | 說明 |
"pred":"10min" | 期望預測結果中時間點的間隔, 單位支援 |
"uncertainty_config": {"interval_width": 0.9999} |
|
"seasonality_config": {"seasons": [{"name": "month", "period": 30.5, "fourier_order": 1}]} |
|
series_pattern_anomalies函數
用於檢測時間序列資料中異常模式。它基於機器學習演算法,能夠自動識別時間序列中的異常點或異常模式,適用於監控、警示和資料分析等情境。
使用限制
已經通過make-series構造出series格式資料,並且時間單位為納秒。
每行的時間點數量至少為11個 。
文法
series_pattern_anomalies(array(T) metric_series)參數說明
參數 | 說明 |
metric_series | 輸入時間序列的指標列,僅支援數實值型別。 |
傳回值
row(
anomalies_score_series array(double),
anomalies_type_series array(varchar)
error_msg varchar
) 列名 | 類型 | 說明 |
anomalies_score_series | array(double) | 異常分數序列,與輸入時間序列相對應。範圍為 [0,1] 代表每個時間點的異常分數。 |
anomalies_type_series | array(varchar) | 異常類型描述序列,與輸入時間序列相對應。代表每個時間點的異常類型。非異常的時間點表示為null。 |
error_msg | varchar | 錯誤資訊。值為null則表示該行時間序列異常檢測成功,否則展示失敗原因。 |
樣本
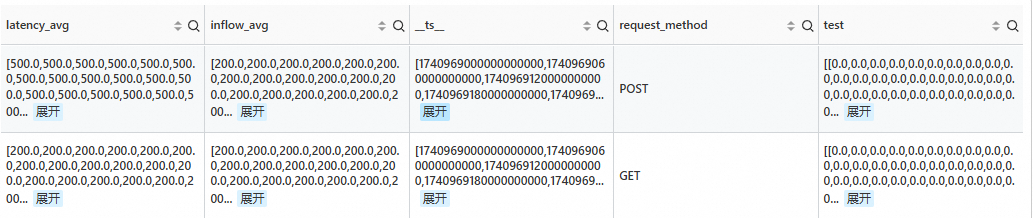
檢測目前時間點的序列是否有異常。
SPL語句
* | extend ts = second_to_nano(__time__ - __time__ % 60) | stats latency_avg = max(cast(status as double)), inflow_avg = min(cast (status as double)) by ts, request_method | where request_method is not null | make-series latency_avg default = 'last', inflow_avg default = 'last' on ts from 'min' to 'max' step '1m' by request_method | extend test=series_pattern_anomalies(inflow_avg)輸出結果
series_decompose_anomalies函數
用於時間序列分解和異常檢測的函數。它基於時間序列分解演算法,將原始時間序列資料拆分為趨勢分量、季節性分量和殘差分量,並通過分析殘差分量來檢測異常點。
使用限制
已經通過make-series構造出series格式資料,並且時間單位為納秒。
每行的時間點數量至少為11個 。
文法
series_decompose_anomalies(array(T) metric_series)或
series_decompose_anomalies(array(T) metric_series, varchar params)參數說明
參數 | 說明 |
metric_series | 輸入時間序列的指標列。 |
params | 可選。演算法參數,json 格式。 |
傳回值
row(
metric_baseline_series array(double)
anomalies_score_series array(double),
anomalies_type_series array(varchar)
error_msg varchar
) 列名 | 類型 | 說明 |
metric_baseline_series | array(double) | 演算法擬合的 metric 資料。 |
anomalies_score_series | array(double) | 異常分數序列,與輸入時間序列相對應。範圍為 [0,1] 代表每個時間點的異常分數。 |
anomalies_type_series | array(varchar) | 異常類型描述序列,與輸入時間序列相對應。代表每個時間點的異常類型。非異常的時間點表示為 null。 |
error_msg | varchar | 錯誤資訊。值為null則表示該行時間序列異常檢測成功,否則展示失敗原因。 |
樣本
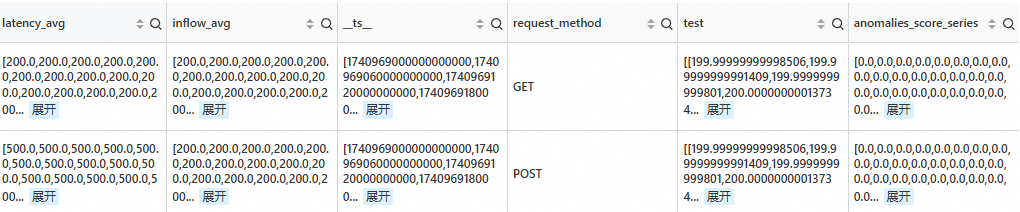
對所有時間軸異常檢測之後,保留最近 5 min 異常分數值大於等於0的時間軸。
SPL語句
* | extend ts = second_to_nano(__time__ - __time__ % 60) | stats latency_avg = max(cast(status as double)), inflow_avg = min(cast (status as double)) by ts, request_method | where request_method is not null | make-series latency_avg default = 'last', inflow_avg default = 'last' on ts from 'min' to 'max' step '1m' by request_method | extend test=series_decompose_anomalies(inflow_avg, '{"confidence":"0.005"}') | extend anomalies_score_series = test.anomalies_score_series | where array_max(slice(anomalies_score_series, -5, 5)) >= 0輸出結果
演算法參數
參數 | 類型 | 樣本 | 描述 |
auto_period | varchar | "true" | 只能設定 "true" 或 "false"。表示是否開啟時序周期自動檢測。如果設定為 "true",自訂的 period_num 和 period_unit 不生效。 |
period_num | varchar | "[1440]" | 序列周期包含多少個時間點。可以輸入多個周期長度,目前服務只考慮長度最長的一個周期。 |
period_unit | varchar | "[\"min\"]" | 序列周期的每個時間點的時間單位。可以輸入多個時間單位,時間單位的數量必須和設定的周期的數量相同。 |
period_config | varchar | "{\"cpu_util\": {\"auto_period\":\"true\", \"period_num\":\"720\", \"period_unit\":\"min\"}}" | 如果需要針對不同的特徵設定不同的周期,可以配置 period_config 欄位,prediod_config 中的欄位名為要設定的特徵的名稱,欄位值為 object,在其中設定 auto_period,period_num,period_unit 三個欄位。 |
trend_sampling_step | varchar | "8" | 時序分解時對於趨勢成分的下採樣率,需要可以轉換成正整數。採樣率越大,趨勢成分的擬合速度越快,趨勢成分的擬合精度會降低。預設為 "1"。 |
season_sampling_step | varchar | "1" | 時序分解時對於周期成分的下採樣率,需要可以轉換成正整數。採樣率越大,周期成分的擬合速度越快,周期成分的擬合精度降低,預設為 "1"。 |
batch_size | varchar | "2880" | 異常分析時使用滑動視窗的形式分段處理。batch_size 表示視窗的大小。視窗越小,分析的速度越快,準確度可能會降低。預設視窗的大小與序列的長度一致。 |
confidence | varchar | "0.005" | 異常分析的敏感度,需要可以轉換成浮點數,取值範圍是(0,1.0)。數值越小,演算法對異常的敏感度越低,檢測到的異常數量減少。 |
confidence_trend | varchar | "0.005" | 在分析趨勢項時,對於異常的敏感度。設定該參數後自動忽略 confidence。數值越小,演算法對於趨勢項的異常的敏感度越低,趨勢項檢測到的異常數量減少。 |
confidence_noise | varchar | "0.005" | 在分析殘差項時,對於異常的敏感度。設定該參數後自動忽略 confidence。數值越小,演算法對於殘差項的異常的敏感度越低,殘差項檢測到的異常數量減少。 |
series_drilldown函數
用於時間序列分析的下鑽函數,允許在時間分組統計的基礎上,進一步對特定時間段內的資料進行細粒度分析。
文法
series_drilldown(array(varchar) label_0_array,array(varchar) label_1_array,array(varchar) label_2_array, ... ,array(array(bigint)) time_series_array,array(array(double)) metric_series_array,bigint begin_time,bigint end_time)或
series_drilldown(array(varchar) label_0_array,array(varchar) label_1_array,array(varchar) label_2_array, ... ,array(array(bigint)) time_series_array,array(array(double)) metric_series_array,bigint begin_time,bigint end_time,varchar config)參數說明
參數 | 說明 |
label_x_array | 數組中每個元素為對應時間序列的label。函數重載最多支援 7 個 label array。 |
time_series_array | 外層數組中每個元素為一個 time series。 |
metric_sereis_array | 外層數組中每個元素為一個 metric series |
begin_time | 需要進行根因下探的開始時間點,一般設定為異常的開始時間,單位為納秒。 |
end_time | 需要進行根因下探的結束時間點,一般設定為異常的結束時間,單位為納秒。 |
config | 可選。演算法參數,json 格式。 |
傳回值
row(dirlldown_result varchar, error_msg varchar)列名 | 類型 | 說明 |
dirlldown_result | varchar | 下探的結果,JSON格式。 |
error_msg | varchar | 錯誤資訊。為 null 則表示該行時間序列預測成功,否則展示失敗原因。 |
dirlldown_result參數說明
{
"attrs": [
{
"api": "/ids/ml/annotationdataset",
"resource": "test"
},
{
"api": "/console/logs/getLogs"
}
],
"statistics": {
"relative_ratio": 0.5003007763190033,
"relative_ratio_predict": 1.0000575873881987,
"unexpected_difference": -4.998402840764594,
"relative_unexpected_difference": -0.499660063545782,
"difference": -4.999183856137503,
"predict": 5.005203022057271,
"relative_ratio_real": 1.9987568734256989,
"real": 10.004386878194774,
"support": 50
}
}attrs參數說明
該參數用於標識該統計結果對應的維度篩選條件。數組中的各個條件為或的關係。
樣本中表示
api為/ids/ml/annotationdataset或者/console/logs/getLogs。"attrs": [ { "api": "/ids/ml/annotationdataset", "resource": "test" }, { "api": "/console/logs/getLogs" } ]attrs中第一個元素表示
api為/ids/ml/annotationdataset並且resource為test。{ "api": "/ids/ml/annotationdataset", "resource": "test" }
statistics參數說明
該參數提供時間序列的統計分析結果,用於根因分析或異常檢測。
指標名 | 類型 | 說明 |
support | int | 在當前根因範圍內,統計樣本量(如資料點數量)。 |
real | float | 在當前根因範圍內,指標的實際觀測值。 |
predict | float | 在當前根因範圍內,指標的預測值。 |
difference | float | 在當前根因範圍內,指標的實際值與預測值的絕對差。計算公式:predict - real。 |
unexpected_difference | float | 在當前根因範圍內,指標的預測值和去除正常波動後的真實值(預期內的變化)的差值(非預期內的變化)。 |
relative_unexpected_difference | float | 在當前根因範圍內,指標的非預期內的變化與預期內的變化的比值。 |
relative_ratio | float | 在當前根因範圍內,指標的實際值與基準值的比例。計算公式:predict/real。 |
relative_ratio_predict | float | 在當前根因範圍內,指標的預測值與根因範圍外的指標的預測值的比值。 |
relative_ratio_real | float | 在當前根因範圍內,指標的真實值與根因範圍外的指標的真實值的比值。 |
樣本
SPL語句
* | extend ts= (__time__- __time__%60)*1000000000 | stats access_count = count(1) by ts, Method, ProjectName | extend access_count = cast( access_count as double) | make-series access_count = access_count default = 'null' on ts from 'sls_begin_time' to 'sls_end_time' step '1m' by Method, ProjectName | stats m_arr = array_agg(Method), ProjectName = array_agg(ProjectName), ts_arr = array_agg(__ts__), metrics_arr = array_agg(access_count) | extend ret = series_drilldown(ARRAY['Method', 'Project'], m_arr, ProjectName, ts_arr, metrics_arr, 1739192700000000000, 1739193000000000000, '{"fill_na": "1", "gap_size": "3"}') | project ret輸出結果

cluster函數
支援對多條時間序列(或向量資料)進行快速分組分析,識別相似形態的指標曲線、檢測異常模式或歸類資料模式。
文法
cluster(array(array(double)) array_vector, varchar cluster_mode,varchar params)參數說明
參數 | 說明 |
array_vector | 一個二維向量,在二維向量中要確保每行的向量長度一致。 |
cluster_mode | 聚類的模型,目前Log Service提供兩種模式: |
params | 不同的聚類模型對應著不同的演算法參數說明。 |
聚類模型
kmeans
{
"n_clusters": "5",
"max_iter": "100",
"tol": "0.0001",
"init_mode": "kmeans++",
"metric": "cosine/euclidean"
}在調整KMeans演算法參數時的最佳化方法和建議,具體針對以下幾個關鍵參數進行了說明:
n_clusters(聚類數量):當前值為5。建議通過肘部法則選擇合適的聚類數量,觀察總誤差平方和(SSE)的變化趨勢,並根據實際效果調整為3或7等其他值。
max_iter(最大迭代次數):當前值為100。對於大規模資料集,可能需要增加迭代次數以確保收斂;若結果提前穩定,則可減少此值以節省計算資源,常用範圍為100至300。
tol(收斂容忍度):該參數控制演算法的收斂條件,定義了簇中心變化幅度的閾值。高精度需求時可將值減小至0.00001,而對於大規模資料可適當放寬至0.001以提高效率,需權衡計算效率與精度。
init_mode(初始模式):當前值為kmeans++,通常能提供較好的初始聚類中心。可根據需求嘗試random初始化,但可能需要更多迭代次數。若初始聚類中心對結果影響較大,可探索不同的初始化策略。
metric(cosine/euclidean):
cosine(餘弦相似性):用於計算向量之間的夾角餘弦值,衡量方向上的相似性,適用於高維資料(如文本向量、映像特徵向量)和相似性匹配任務(如推薦系統)。當資料已歸一化為單位向量時,餘弦相似性等價於內積。
euclidean(歐幾裡得距離):用於計算兩點間的直線距離,衡量絕對距離差異,適用於低維空間的幾何問題(如座標點)和距離敏感任務(如K均值聚類、K近鄰分類/迴歸)。適用於需要保留資料絕對值差異的情境。
dbscan
{
"epsilon": "0.1", // 注意:當 epsilon 的值 小於等於 0 時,演算法會自動的去推斷這個參數。
"min_samples": "5"
}SPL函數文本介紹了DBSCAN(Density-Based Spatial Clustering of Applications with Noise)演算法中的兩個關鍵參數epsilon (ε) 和 min_samples,它們用於定義簇的密度標準:
epsilon (
ε):定義點的鄰域範圍,用於判斷點是否相鄰。較小的ε可能導致更多雜訊點,而較大的ε可能合并不相關的點。通常通過觀察k距離圖的肘部點來選擇合適的ε值。min_samples:定義形成密集簇所需的最小點數。較高的值會使演算法更嚴格,減少簇數量並增加雜訊點;較低的值可能包括不密集的地區。一般根據資料維度選擇,如二維資料可選4或5。
這兩個參數共同決定簇的形成和雜訊點的識別。DBSCAN的優勢在於能識別任意形狀的簇且無需指定簇的數量,但其效能對參數選擇非常敏感,通常需要結合實驗和資料特性進行調整以獲得最佳聚類效果。
傳回值
row(
n_clusters bigint,
cluster_sizes array(bigint),
assignments array(bigint),
error_msg varchar
)列名 | 類型 | 說明 |
n_clusters | bigint | 返回的聚類結果的個數。 |
cluster_sizes | array(bigint) | 每個聚類中心包含樣本的個數。 |
assignments | array(bigint) | 輸入的每個樣本對應的cluster_id的編號。 |
error_msg | varchar | 當調用失敗時,返回的錯誤資訊。 |
樣本
SPL語句
* and __tag__:__job__: sql-calculate-metric | extend time = cast(time as bigint) - cast(time as bigint) % 300 | extend time = second_to_nano(time) | stats avg_latency = avg(cast(sum_latency as double)) by time, Method | make-series avg_latency = avg_latency default = '0' on time from 'sls_begin_time' to 'sls_end_time' step '5m' by Method | stats method_array = array_agg(Method), ts_array = array_agg(__ts__), ds_array = array_agg(avg_latency) | extend ret = cluster(ds_array, 'kmeans', '{"n_clusters":"5"}') | extend n_clusters = ret.n_clusters, cluster_sizes = ret.cluster_sizes, assignments = ret.assignments, error_msg = ret.assignments輸出結果

series_describe函數
一種用於時間序列分析的函數。該函數從多個維度對時間序列進行分析並返回結果,具體包括:資料是否連續、資料缺失情況、序列是否穩定、序列是否具有周期性及周期長度、以及序列是否存在顯著趨勢。
使用限制
已經通過make-series構造出 series 格式資料,時間單位必須精確到納秒。
文法
series_describe(__ts__ array<bigint>, __ds__ array<double>)或
series_describe(__ts__ array<bigint>, __ds__ array<double>,config varchar)參數說明
參數 | 說明 |
__ts__ | 單調遞增加的時間序列,表示時間序列的每個資料點的Unix時間戳記(納秒級)。 |
__ds__ | 浮點數類型的數值序列,表示對應時間點的數值,長度和時間序列相同。 |
config | 演算法參數(可選),演算法的預設參數如下,也可以自訂參數進行控制:
樣本: |
傳回值
row(statistic varchar, error_msg varchar)列名 | 類型 | 說明 |
statistic | varchar | json序列化後的字串,用來儲存序列的統計資訊。 |
cluster_sizes | array(bigint) | 每個聚類中心包含樣本的個數。 |
statistic樣本
返回的結果是一個JSON序列化的字串。
{
"duplicate_count": 0,
"total_count": 1,
"mean": 3.0,
"variance": null,
"min": 3.0,
"max": 3.0,
"median": 3.0,
"interval": null,
"missing_count": 0,
"adf_test": null,
"is_stable": false,
"period": null,
"trend": null
}參數 | 說明 |
duplicate_count | 重複值的數量。 |
total_count | 總資料點數量。 |
mean | 平均值。 |
variance | 方差(此處為 |
min | 最小值。 |
max | 最大值。 |
median | 中位元。 |
interval | 時間間隔(此處為 |
missing_count | 缺失值的數量。 |
adf_test | ADF檢驗結果(此處為null,表示未進行或不適用)。 |
is_stable | 是否穩定(布爾值,表示資料是否具有穩定性)。 |
period | 周期(此處為 |
trend | 趨勢(此處為 |
樣本
SPL語句
* and entity.file_name: "239_UCR_Anomaly_taichidbS0715Master.test.csv" | extend time = cast(__time__ as bigint) | extend time = time - time % 60 | stats value = avg(cast(value as double)) by time | extend time = second_to_nano(time) | make-series value = value default = 'nan' on time from 'min' to 'max' step '1m' | extend ret = series_describe(value)輸出結果

correlation函數
用於計算兩個對象之間的相似性。具體功能包括: 1. 如果兩個對象均為單個向量,返回兩序列的相似性。 2. 如果一個對象是向量組,另一個是單個向量,返迴向量組中每個向量與該單個向量的相似性。 3. 如果兩個對象均為向量組,返回兩組向量之間兩兩相似性的矩陣。
使用限制
入參已經通過make-series構造出 series 格式資料。
文法
重載1
correlation(arr_1 array(double), arr_2 array(double), params varchar)重載2
correlation(arr_arr_1, array(array(double)), arr_2 array(double), params varchar)重載3
correlation(arr_arr_1 array(array(double)), arr_arr_2 array(array(double)), params varchar)
參數說明
重載1
參數
說明
arr_1
一條時間序列(通過make-series產生的單個單元)。
arr_2
一條時間序列(通過make-series產生的單個單元)。
params
演算法參數(可選),json 格式。
重載2
參數
說明
arr_arr_1
一條時間序列(通過make-series產生的單個單元)處理後,使用array_agg函數返回一個二維數組。
arr_2
一條時間序列(通過make-series產生的單個單元)。
params
演算法參數(可選),json 格式。
重載3
參數
說明
arr_arr_1
一條時間序列(通過make-series產生的單個單元)處理後,使用array_agg函數返回一個二維數組。
arr_arr_2
一條時間序列(通過make-series產生的單個單元)處理後,使用array_agg函數返回一個二維數組。
params
演算法參數(可選),json 格式。
演算法參數
參數名 | 參數解釋 | 參數類型 | 是否必填 |
measurement | 相關性係數的計算方式,大部分情況下直接選用"Pearson"即可。 取值範圍:
| varchar | 是 |
max_shift | 表示允許第一個變數(第一個參數對應的向量)向左移的時序點的最大數量。負值表示第一個變數可以“右移”。輸出的相關性係數是允許位移的情況下的最大相關性係數。 | integer | 否。預設值為0,表示不允許shift。 |
flag_shift_both_direction | 取值範圍:
| boolean | 否,預設為"false"。 |
傳回值
重載1
row(result double)列名
類型
說明
result
double
入參arr_1和arr_2的相關性係數。
重載2
row(result array(double))列名
類型
說明
result
array(double)
arr_arr_1裡面每一個向量和和arr_2的相關性係數的數組, 返回數組的長度是 arr_arr_1裡面向量的個數。
重載3
row(result array(array(double)))列名
類型
說明
result
array(array(double))
返回的是一個矩陣。如果資料不為空白,第i行j列是 arr_arr_1[i] 和arr_arr_2[j]的相關性係數。
樣本
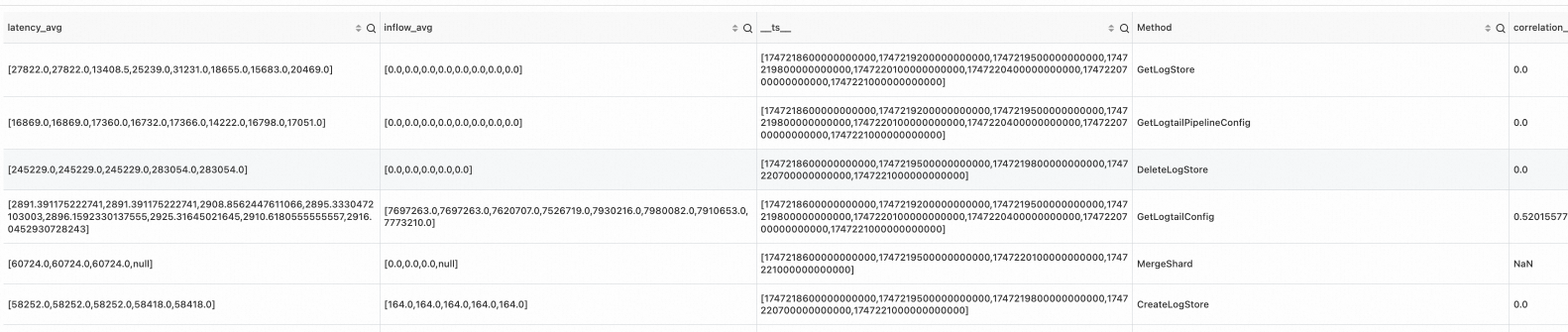
樣本一
SPL語句
* | where Method != 'GetProjectQuery' | extend ts = second_to_nano(__time__ - __time__ % 60) | stats latency_avg = max(cast(avg_latency as double)), inflow_avg = min(cast (sum_inflow as double)) by ts, Method | make-series latency_avg default = 'next', inflow_avg default = 'next' on ts from 'sls_begin_time' to 'sls_end_time' step '1m' by Method | extend correlation_scores = correlation( latency_avg, inflow_avg )輸出結果
樣本2
SPL語句
* | where Method='GetProjectQuery' | extend ts = second_to_nano(__time__ - __time__ % 60) | stats latency_avg = max(cast(avg_latency as double)), inflow_avg = min(cast (sum_inflow as double)) by ts, Method | make-series latency_avg default = 'last', inflow_avg default = 'last' on ts from 'min' to 'max' step '1m' by Method | extend scores = correlation( latency_avg, inflow_avg, '{"measurement": "SpearmanRank", "max_shift": 4}' )輸出結果

樣本3
SPL語句
* | where Method='GetProjectQuery' | extend ts = second_to_nano(__time__ - __time__ % 60) | stats latency_avg = max(cast(avg_latency as double)), inflow_avg = min(cast (sum_inflow as double)) by ts, Method | make-series latency_avg default = 'last', inflow_avg default = 'last' on ts from 'min' to 'max' step '1m' by Method | extend scores = correlation( latency_avg, inflow_avg, '{"measurement": "KendallTau", "max_shift": 5, "flag_shift_both_direction": true}')輸出結果
