Log Service智能異常分析App提供模型訓練和即時巡檢功能,支援對日誌、指標等資料進行自動化、智能化、自適應地模型訓練和異常巡檢。本文介紹智能巡檢的背景資訊、工作原理、功能特性、基本概念、調度與執行情境和使用建議。
自2025年7月15日(UTC+8)起,智能異常分析功能停止對新使用者服務,存量使用者可繼續使用。
影響範圍
本次下線涉及的核心功能模組包括智能巡檢、文本分析和時序預測。
功能平移方案
上述下線功能均可以通過Log Service的機器學習文法、定時查詢與分析(定時SQL)和儀錶盤實現完整替代。
背景資訊
基於時間的資料(例如日誌、指標)日積月累後會積累大量的資料。例如,某個服務每天產生1000萬條資料,則一年大約為36億條資料。對於這些資料,使用固定巡檢規則的人工巡檢方式面臨以下問題:
效率低:對於異常現場的定位,需要人工配置各種各樣的規則去進行異常的捕獲。
時效差:大部分時序資料具有時效性特徵。故障、變更都會引起對應指標形態的變化,前一種規則條件下的異常可能在下一時刻是正常狀態。
配置難:時序資料形態各異。有突刺變化、折點變化、周期變化等諸多形態,閾值範圍也各有不同。對於複雜形態下的異常,規則往往難以配置。
效果差:資料流不斷動態變化,業務形態日新月異,固定的規則方法很難在新的業態下起作用,從而產生大量的誤判或者漏報。對於異常的程度,不同情境,不同使用者,對其容忍的程度不同。在排查問題中,有效異常點捕捉的越多,有助於具體問題的排查;而在警示通知中,高危異常點越少,越有助於提升警示處理的效率。
針對以上問題,Log Service推出智能巡檢功能,通過自研的人工智慧演算法,對指標、日誌等流資料進行一站式整合、巡檢與警示。使用智能巡檢功能後,您只需要組織一下具體的監控項,演算法模型就會自動為您完成異常檢測、業態自適應、警示精細,讓您從複雜繁瑣的規則配置中解脫出來。
工作原理
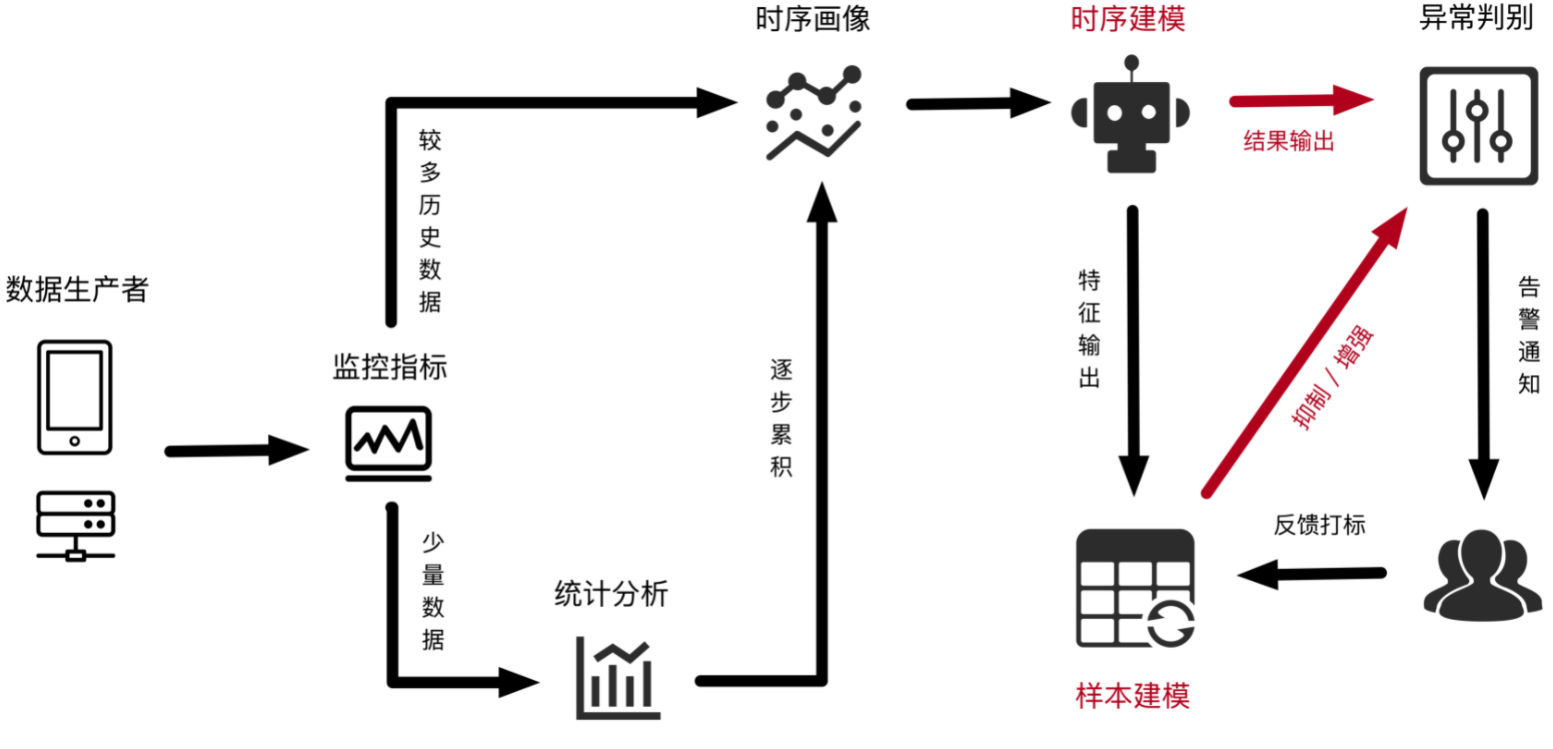
Log Service通過SQL方式構造、彙總監控指標,按照調度規則定時拉取資料輸入模型,將巡檢出來的結果按照事件標準寫入目標日誌庫(internal-ml-log)中,並對異常發送警示通知。具體工作原理如下圖所示。
功能特性
Log Service的智能巡檢功能的特性如下表所示。
特性 | 說明 |
配置監控對象 | 設定SQL語句或查詢分析語句,把日誌資料轉化成監控指標,發起任務 |
定時分析資料 | 根據需求設定具體的資料特徵,配置實體項和指標項。巡檢執行個體自動探索新的監控實體,定時拉取資料進行自動建模與智能分析。模型定時調度最高支援秒級拉取。 |
參數設定與模型效果預覽 | 不同模型參數設定後支援效果預覽,同時對指標時序曲線與異常分數曲線進行可視化。您可以輕鬆配置最適合當前資料特徵的模型參數。 |
結果輸出多渠道 | 巡檢結果儲存到目標LogStore中,通過警示通知將異常語音總機給您。 |
基本概念
Log Service的智能巡檢功能涉及的基本概念如下表所示。
術語 | 說明 |
任務 | 一個巡檢任務包括資料特徵、模型參數、警示策略等資訊。 |
執行個體 | 一個巡檢任務按照任務配置產生執行執行個體。每一個執行個體針對任務配置定時拉取資料,運行演算法模型,分發巡檢結果。
|
執行個體ID | 執行執行個體的唯一標識。 |
建立時間 | 執行個體建立的時間。一般是按照您配置的任務規則產生,在補運行或追趕延遲時會立即產生執行個體。 |
執行時間 | 執行個體開始執行的時間。如果重試任務,則表示最後一次開始執行的時間。 |
結束時間 | 執行個體執行結束的時間。如果重試任務,則表示最後一次執行結束的時間。 |
執行狀態 | 執行個體的執行狀態。取值:
|
資料特徵 | 資料特徵包含以下配置:
|
演算法配置 | 不同的演算法有不同的配置項。各個演算法的配置項說明請參見通過SQL彙總指標資料進行即時檢測。 |
巡檢事件 | 巡檢事件包含以下配置:
|
調度與執行情境
巡檢任務的調度與執行的主要情境如下表所示。
情境 | 說明 |
從某個記錄點開始執行巡檢任務 | 在目前時間點建立巡檢任務後,按照任務規則對歷史資料進行處理。演算法模型會快速消費歷史資料、進行模型訓練,並逐漸追上目前時間。超過任務建立時間或者模型結束學習時間後,發出巡檢事件。 |
修改調度配置 | 修改調度配置後,下一個執行個體按照新配置產生。演算法模型會記憶當前消費的時間位置,進而對新來的資料繼續巡檢。 |
重試失敗的執行個體 | 如果執行個體執行失敗(例如許可權不足、源庫不存在、目標庫不存在、配置不合法等),系統支援自動重試。若您的狀態一直顯示啟動中,可能是配置失敗。錯誤記錄檔會發送到您的internal-etl-log下,您可以檢查下配置並重新發起。調度執行完成後,系統會根據實際執行情況變更執行個體狀態為成功或失敗。 |
使用建議
建議您在使用智能巡檢時,根據業務情況,明確具體的監控項,從而進行高效的資料轉化與巡檢。具體說明如下:
考慮資料上傳LogStore的格式,明確欄位的具體含義,確定觀測時間間隔,從而完成巡檢任務的快速配置。
掌握所監控對象的時序資料變化情況,瞭解其穩定性、周期性,對異常形態有初步預期,從而完成演算法參數的合理配置。
按整時(例如整秒、整分鐘、整小時)對齊巡檢任務時間視窗,從而保證例外狀況事件的警示及時性與多事件關聯的準確性。
模型訓練
您還可以使用模型訓練功能加強對資料的異常學習,提升未來的異常預警準確率,模型訓練主要具備以下優勢。
直接使用即時巡檢功能,準確率不及預期。通過模型訓練任務,可提升異常檢測的準確性。
通過即時巡檢任務檢測出來的異常和您所認為的異常之間存在GAP值時,建議您先通過模型訓練任務來自適應檢測所需要的異常類型。
基本流程
輸入資料:寫入模型訓練服務所需要的資料,包含帶標籤的指標資料和不帶標籤的指標資料。這些資料統一儲存在Log Service中,需要通過SQL查詢來擷取。其中,帶標籤的指標資料可以直接進入演算法服務,不帶標籤的指標資料需要通過類比異常注入方式,在獲得標籤後進入演算法服務。
演算法服務:主要包含特徵工程和監督模型兩部分。在演算法服務中,每一個實體訓練一個模型,即會使用實體ID標識對應的模型。
結果儲存和可視化:模型訓練任務完成後,系統會將所訓練的模型進行雲端儲存,將資料集的驗證結果、任務啟動並執行事件等以日誌形式儲存到名為internal-ml-log的LogStore中。您還可以通過任務詳情查看可視化結果。
建立預測任務:模型訓練任務完成後,您將得到該任務中每個實體所訓練的模型。接著您可以建立預測任務,通過預測任務對未來指標資料做即時的異常檢測,以及Log Service打標工具,對結果進行打標,得到更多的標籤資料,反覆訓練模型,提升準確率。
演算法服務簡介
演算法服務主要包括如下三部分。
資料集:通過指定的時間範圍構建資料集,分為訓練集和驗證集。
訓練集的時間長度需大於12天,因為模型訓練任務需要歷史一周的資料做為特徵工程的前提條件;驗證集長度需大於3天,因為需要三天的資料給出驗證報告,更好地說明模型的擬合程度、魯棒性以及表現水平。
特徵工程:包括同環位元征、平移特徵、趨勢特徵、視窗特徵、時間特徵等。
整合模型:通過整合多個樹模型來構建最終的模型。