在容器化環境中,業務日誌通常分散於各個Docker 容器的標準輸出或記錄檔中,難以集中管理和快速檢索。通過Log Service的 LoongCollector 採集器,可將多節點容器日誌匯聚至統一日誌庫,實現日誌的集中儲存、結構化解析、脫敏過濾和高效查詢分析。
適用範圍
許可權要求:部署使用的阿里雲主帳號或子帳號需具備
AliyunLogFullAccess許可權。Docker 版本與 LoongCollector 要求:
如果您的Docker Engine版本大於等於v29.0,或支援的最低Docker API版本大於等於1.42,請使用 LoongCollector 3.2.4及以上版本,否則將無法採集容器標準輸出或檔案日誌。
LoongCollector 3.2.4及以上版本支援的Docker API版本範圍為1.24 ~ 1.48。
LoongCollector 3.2.3及以下版本支援的Docker API版本範圍為1.18 ~ 1.41。
採集標準輸出限制:
必須在Docker的設定檔daemon.json中添加
"log-driver": "json-file"。如果是CentOS 7.4及以上版本(除CentOS 8.0以外),需設定
fs.may_detach_mounts=1。
採集文本日誌限制:僅支援overlay、overlay2兩種儲存驅動(其他類型需手動掛載日誌目錄)。
採集配置建立流程
準備工作:建立Project和LogStore,Project是資源嵌入式管理單元,用於隔離不同業務日誌,LogStore用於儲存日誌。
配置機器組(安裝LoongCollector):在需要採集日誌的伺服器上安裝LoongCollector,並將其加入到機器組中。使用機器組統一管理採集節點,對伺服器進行配置分發與狀態管理。
查詢分析配置:系統預設開啟全文索引,支援關鍵詞搜尋。建議啟用欄位索引,以便對結構化欄位進行精確查詢和分析,提升檢索效率。
準備工作
在採集日誌前,需規劃並建立用於管理與儲存日誌的Project和LogStore。若已有可用資源,可跳過此步驟,直接進行步驟一:配置機器組(安裝LoongCollector)。
建立Project
建立LogStore
單擊Project名稱,進入目標Project。
在左側導覽列,選擇
 ,單擊+。
,單擊+。在建立LogStore頁面,完成以下核心配置:
Logstore名稱:設定一個在Project內唯一的名稱。該名稱建立後不可修改。
Logstore類型:根據規格對比選擇標準型或查詢型。
計費模式:
按使用功能計費(不支援更改):按儲存、索引、讀寫次數等各項資源獨立計費。適合小規模或功能使用不確定的情境。
按寫入數據量計費:僅按原始寫入資料量計費,提供30天免費儲存,以及免費的資料加工、投遞等功能。適合儲存周期接近30天或資料處理鏈路複雜的業務情境。
資料儲存時間:設定日誌的保留天數(1~3650天,3650為永久儲存),預設為30天。
其他配置保持預設,單擊確定。如需瞭解其他配置資訊,請參考管理LogStore。
步驟一:配置機器組(安裝LoongCollector)
在Docker宿主機上以容器方式部署LoongCollector,並將其加入到機器組中。通過機器組實現對多個採集節點的統一管理、配置分發與狀態監控。
拉取鏡像
在已安裝Docker的宿主機上執行如下命令,拉取 LoongCollector 鏡像。請將
${region_id}替換為宿主機所在地區或就近地區ID(如cn-hangzhou),以提升下載速度和穩定性。# LoongCollector鏡像地址 docker pull aliyun-observability-release-registry.${region_id}.cr.aliyuncs.com/loongcollector/loongcollector:v3.0.12.0-25723a1-aliyun # Logtail鏡像地址 docker pull registry.${region_id}.aliyuncs.com/log-service/logtail:v2.1.11.0-aliyun啟動LoongCollector容器
運行以下命令啟動容器,確保正確掛載目錄並設定必要環境變數:
docker run -d \ -v /:/logtail_host:ro \ -v /var/run/docker.sock:/var/run/docker.sock \ --env ALIYUN_LOGTAIL_CONFIG=/etc/ilogtail/conf/${sls_upload_channel}/ilogtail_config.json \ --env ALIYUN_LOGTAIL_USER_ID=${aliyun_account_id} \ --env ALIYUN_LOGTAIL_USER_DEFINED_ID=${user_defined_id} \ aliyun-observability-release-registry.${region_id}.cr.aliyuncs.com/loongcollector/loongcollector:v3.0.12.0-25723a1-aliyun參數說明:
${sls_upload_channel}:日誌上傳通道,由Project所在地區-網路傳輸類型構成。樣本:傳輸類型
配置值格式
樣本
適用情境
內網傳輸
regionIdcn-hangzhouECS與Project同地區
公網傳輸
regionId-internetcn-hangzhou-internetECS和Project屬於不同地區
伺服器為其他雲廠商伺服器或自建IDC
傳輸加速
regionId-accelerationcn-hangzhou-acceleration國內外跨地區通訊
${aliyun_account_id}:阿里雲主帳號ID。${user_defined_id}:機器組的使用者自訂標識,用於綁定機器組(如user-defined-docker-1),需在地區內唯一。重要必須滿足的啟動條件:
正確配置三個關鍵環境變數:
ALIYUN_LOGTAIL_CONFIG、ALIYUN_LOGTAIL_USER_ID、ALIYUN_LOGTAIL_USER_DEFINED_ID。掛載
/var/run/docker.sock:用於監聽容器生命週期事件。掛載
/→/logtail_host:用於訪問宿主機檔案系統。
驗證容器運行狀態
docker ps | grep loongcollector預期輸出樣本:
6ad510001753 aliyun-observability-release-registry.cn-beijing.cr.aliyuncs.com/loongcollector/loongcollector:v3.0.12.0-25723a1-aliyun "/usr/local/ilogtail…" About a minute ago Up About a minute recursing_shirley配置機器組
在左側導覽列,單擊,配置如下參數並單擊確定:
名稱:自訂機器組名稱(如
docker-host-group)。機器組標識::選擇用戶自訂標識。
用戶自訂標識:輸入啟動容器時設定的
${user_defined_id}。必須完全一致,否則無法關聯成功。
驗證機器組心跳狀態
單擊建立機器組名稱,進入機器組詳情頁,查看:
OK:表示LoongCollector 已成功串連到Log Service。
FAIL:請參考心跳異常問題匯總排查。
步驟二:建立並配置日誌採集規則
定義 LoongCollector 採集哪些日誌、如何解析日誌結構、如何過濾內容,並將配置綁定到登入的機器組。
在
 日誌庫頁面,單擊目標LogStore名稱前的
日誌庫頁面,單擊目標LogStore名稱前的 展開。
展開。單擊接入數據後的
 ,在快速數據接入彈框中,根據日誌源選擇接入模板,並單擊立即接入:
,在快速數據接入彈框中,根據日誌源選擇接入模板,並單擊立即接入:Docker 標準輸出:選擇Docker標準輸出-新版
容器標準輸出採集支援新版與舊版兩種模板,推薦使用新版。如需瞭解新、舊版本差異,請參考附錄:容器標準輸出新舊版本對比。使用舊版採集參考採集Docker容器的標準輸出(舊版)。
Docker 檔案日誌:選擇Docker檔案-容器
機器組配置,完成後單擊下一步:
使用情境:選擇Docker情境。
將步驟一中建立好的機器組從源機器組列表添加至右側應用機器組。
在Logtail設定頁面,完成如下配置,並單擊下一步。
1. 全域與輸入配置
配置前,請確保已完成資料接入模板選擇和機器組綁定。本步驟用於定義採集配置的名稱、日誌來源及採集範圍。
採集Docker標準輸出
全域配置
配置名稱:自訂採集配置名稱,在其所屬Project內必須唯一。建立成功後,無法修改。命名規則:
僅支援小寫字母、數字、連字號(-)和底線(_)。
必須以小寫字母或者數字作為開頭和結尾。
輸入配置
選擇開啟標準輸出或標準錯誤開關(預設全部開啟)。
重要建議不要同時開啟標準輸出和標準錯誤,可能會導致採集日誌出現混亂。
採集Docker容器文本日誌
全域配置:
配置名稱:自訂採集配置名稱,在其所屬Project內必須唯一。建立成功後,無法修改。命名規則:
僅支援小寫字母、數字、連字號(-)和底線(_)。
必須以小寫字母或者數字作為開頭和結尾。
輸入配置:
檔案路徑類型:
容器內路徑:採集容器內的記錄檔。
宿主機路徑:採集宿主機本地服務日誌。
檔案路徑:日誌採集的絕對路徑。
Linux:以“/”開頭,如
/data/mylogs/**/*.log,表示/data/mylogs目錄下所有尾碼名為.Log的檔案。Windows:以盤符開頭,如
C:\Program Files\Intel\**\*.Log。
最大目錄監控深度:檔案路徑中萬用字元
**匹配的最大目錄深度。預設為0(僅本層),取值範圍是0~1000。建議設定為0,配置路徑到檔案所在的目錄。
2. Tlog與結構化
配置Tlog規則可將原始非結構化日誌轉換為結構化的資料,提升日誌查詢與分析效率。建議在配置前先添加日誌範例:
在Logtail設定頁面的處理配置地區,單擊添加日誌範例,輸入待採集的日誌內容。系統將基於範例識別日誌格式,輔助產生Regex和解析規則,降低配置難度。
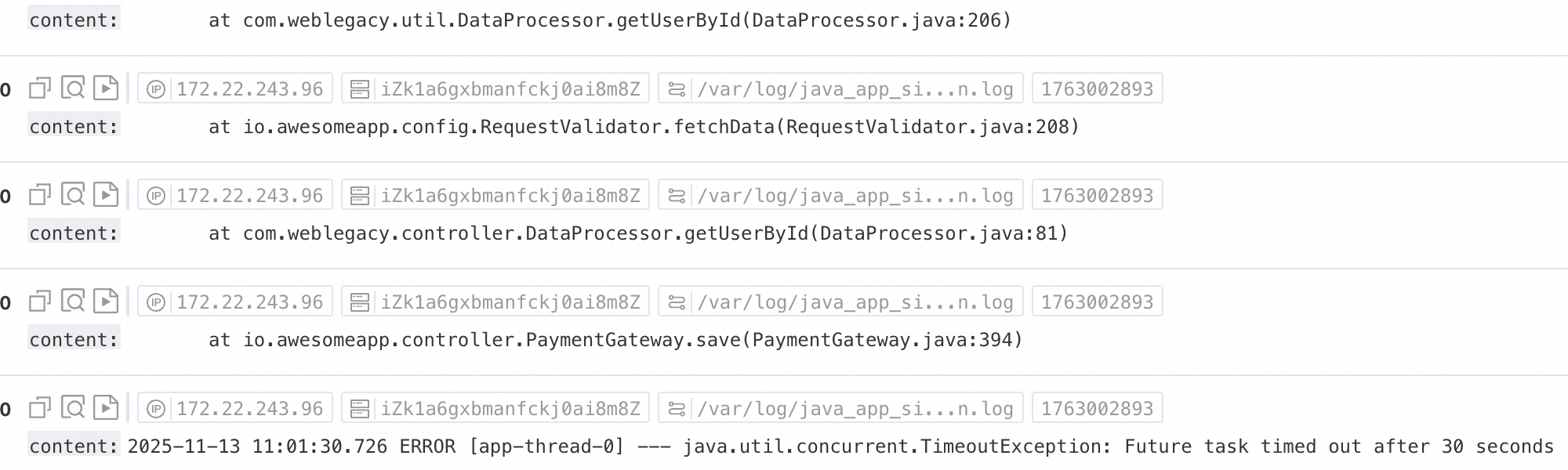
情境一:多行Tlog(如Java堆棧日誌)
由於Java異常堆棧、JSON等日誌通常跨越多行,在預設採集模式下會被拆分為多條不完整的記錄,導致上下文資訊丟失;為此,可啟用多行採集模式,通過配置行首Regex,將同一日誌的連續多行內容合并為一條完整日誌。
效果樣本:
未經任何處理的原始日誌 | 預設採集模式下,每行作為獨立日誌,堆棧資訊被拆散,丟失上下文 | 開啟多行模式,通過行首Regex識別完整日誌,保留完整語義結構。 |
|
|
|

配置步驟:在Logtail設定頁面的處理配置地區,開啟多行模式:
類型:選擇自訂或多行JSON。
自訂:原始日誌的格式不固定,需配置行首Regex,來標識每條日誌的起始行。
行首Regex:支援自動產生或手動輸入,Regex需要能夠匹配完整的一行資料,如上述樣本中匹配的Regex為
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*。自動產生:單擊自動產生Regex,然後在日誌範例文字框中,選擇需提取的日誌內容,單擊產生正則。
手動輸入:單擊手動輸入Regex,輸入完成後,單擊驗證。
多行JSON:當原始日誌均為標準JSON格式時,Log Service會自動處理單條JSON日誌內部的換行。
切分失敗處理方式:
丟棄:如果一段文本無法匹配行首規則,則直接丟棄。
保留單行:將無法匹配的文本按原始的單行模式進行切分和保留。
情境二:結構化日誌
當原始日誌為非結構化或半結構化文本(如 Nginx 訪問日誌、應用輸出日誌)時,直接進行查詢和分析往往效率低下。Log Service提供多種資料解析外掛程式,能夠自動將不同格式的原始日誌轉換為結構化資料,為後續的分析、監控和警示提供堅實的資料基礎。
效果樣本:
未經任何處理的原始日誌 | 結構化解析後的日誌 |
| |
配置步驟:在Logtail設定頁面的處理配置地區
添加解析外掛程式:單擊添加處理外掛程式,根據實際格式配置正則解析、分隔字元解析、JSON 解析等外掛程式。此處以採集NGINX日誌為例,選擇。
NGINX日志配置:將 Nginx 伺服器設定檔(nginx.conf)中的
log_format定義完整地複製並粘貼到此文字框中。樣本:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$request_time $request_length ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent"';重要此處的格式定義必須與伺服器上組建記錄檔的格式完全一致,否則將導致日誌解析失敗。
通用配置參數說明:以下參數在多種資料解析外掛程式中都會出現,其功能和用法是統一的。
原始欄位:指定要解析的源欄位名。預設為
content,即採集到的整條日誌內容。解析失敗時保留原始欄位:推薦開啟。當日誌無法被外掛程式成功解析時(例如格式不匹配),此選項能確保原始日誌內容不會丟失,而是被完整保留在指定的原始欄位中。
解析成功時保留原始欄位:選中後,即使日誌解析成功,原始日誌內容也會被保留。
3. 日誌過濾
在日誌採集過程中,大量低價值或無關日誌(如 DEBUG/INFO 層級日誌)的無差別收集,不僅造成儲存資源浪費、增加成本,還影響查詢效率並帶來資料泄露風險。為此,可通過精細化過濾策略實現高效、安全的日誌採集。
通過內容過濾降低成本
基於日誌內容的欄位過濾(如僅採集 level 為 WARNING 或 ERROR 的日誌)。
效果樣本:
未經任何處理的原始日誌 | 只採集 |
| |
配置步驟:在Logtail設定頁面的處理配置地區
單擊添加處理外掛程式,選擇:
欄位名:過濾的日誌欄位。
欄位值:用於過濾的Regex,僅支援全文匹配,不支援關鍵詞部分匹配。
通過黑名單控制採集範圍
通過黑名單機制排除指定目錄或檔案,避免無關或敏感日誌被上傳。
配置步驟:在Logtail設定頁面的地區,啟用採集黑名單,並單擊添加。
支援完整匹配和萬用字元匹配目錄和檔案名稱,萬用字元只支援星號(*)和半形問號(?)。
檔案路徑黑名單:需要忽略的檔案路徑,樣本:
/home/admin/private*.log:在採集時忽略/home/admin/目錄下所有以private開頭,以.log結尾的檔案。/home/admin/private*/*_inner.log:在採集時忽略/home/admin/目錄下以private開頭的目錄內,以_inner.log結尾的檔案。
檔案黑名單:配置採集時需要忽略的檔案名稱,樣本:
app_inner.log:在採集時忽略所有名為app_inner.log的檔案。
目錄黑名單:目錄路徑不能以正斜線(/)結尾,樣本:
/home/admin/dir1/:目錄黑名單不會生效。/home/admin/dir*:在採集時忽略/home/admin/目錄下所有以dir開頭的子目錄下的檔案。/home/admin/*/dir:在採集時忽略/home/admin/目錄下二級目錄名為dir的子目錄下的所有檔案。例如/home/admin/a/dir目錄下的檔案被忽略,/home/admin/a/b/dir目錄下的檔案被採集。
容器過濾
基於容器元資訊(如環境變數、Pod 標籤、命名空間、容器名稱等)設定採集條件,精準控制採集哪些容器的日誌。
配置步驟:在Logtail設定頁面的輸入配置地區,啟用容器過濾,並單擊添加
多個條件之間為“且”的關係,所有正則匹配均基於 Go 語言的 RE2 正則引擎,功能較 PCRE 等引擎有所限制,請遵循附錄:Regex使用限制(容器過濾)編寫Regex。
環境變數黑/白名單:指定待採集容器的環境變數條件。
K8s Pod標籤黑/白名單:指定待採集容器所在Pod 的標籤條件。
K8s Pod 名稱正則匹配:通過Pod名稱指定待採集的容器
K8s Namespace 正則匹配:通過Namespace名稱指定待採集的容器。
K8s 容器名稱正則匹配:通過容器名稱指定待採集的容器。
容器label黑/白名單:採集容器標籤合格容器,Docker情境使用,K8s情境不推薦使用。
4. 日誌分類
在多應用、多執行個體共用相同日誌格式的情境下,日誌來源難以區分,導致查詢時上下文缺失、分析效率低下。為此,可通過配置日誌主題(Topic)和日誌打標實現自動化的上下文關聯與邏輯分類。
配置日誌主題(Topic)
當多個應用或執行個體的日誌格式相同但路徑不同時(如 /apps/app-A/run.log 和 /apps/app-B/run.log),採集日誌難以區分來源。此時可基於機器組、自訂名稱或檔案路徑提取方式產生 Topic,靈活區分不同業務或路徑來源的日誌。
配置步驟::選擇Topic產生方式,支援如下三種類型:
機器組Topic:將採集配置應用於多個機器組時,LoongCollector 會自動使用伺服器所屬的機器組名稱作為
__topic__欄位上傳。適用於按主機叢集劃分日誌情境。自訂:格式為
customized://<自訂佈景主題名>,例如customized://app-login。適用於固定業務標識的靜態主題情境。檔案路徑提取:從記錄檔的完整路徑中提取關鍵資訊,動態標記日誌來源。適用於多使用者/應用共用相同記錄檔名但路徑不同的情況。
當多個使用者或服務將日誌寫入不同頂級目錄,但下級路徑和檔案名稱一致時,僅靠檔案名稱無法區分來源,例如:
/data/logs ├── userA │ └── serviceA │ └── service.log ├── userB │ └── serviceA │ └── service.log └── userC └── serviceA └── service.log此時您可以配置檔案路徑提取,並使用Regex從完整路徑中提取關鍵資訊,並將匹配結果作為日誌主題(Topic)上傳至LogStore。
擷取規則:基於Regex的擷取的群組
在配置Regex時,系統根據擷取的群組的數量和命名方式自動決定輸出欄位格式,規則如下:
檔案路徑的Regex中,需要對正斜線(/)進行轉義。
擷取的群組類型
適用情境
產生欄位
正則樣本
匹配路徑樣本
產生欄位
單擷取的群組(僅一個
(.*?))僅需一個維度區分來源(如使用者名稱、環境)
產生
__topic__欄位\/logs\/(.*?)\/app\.log/logs/userA/app.log__topic__:userA多擷取的群組-非命名(多個
(.*?))需要多個維度但無需語義標籤
產生tag欄位
__tag__:__topic_{i}__,其中{i}為擷取的群組的序號\/logs\/(.*?)\/(.*?)\/app\.log/logs/userA/svcA/app.log__tag__:__topic_1__userA;__tag__:__topic_2__svcA多擷取的群組-命名(使用
(?P<name>.*?)需多維且希望欄位含義清晰、便於查詢與分析
產生tag欄位
__tag__:{name}\/logs\/(?P<user>.*?)\/(?P<service>.*?)\/app\.log/logs/userA/svcA/app.log__tag__:user:userA;__tag__:service:svcA
日誌打標
啟用日誌標籤富化功能,從容器環境變數或 Kubernetes Pod 標籤中提取關鍵資訊並附加為 tag,實現日誌的精細化分組。
配置步驟:在Logtail設定頁面的輸入配置地區,啟用日誌標籤富化,並單擊添加。
環境變數相關:配置環境變數名和tag名,環境變數值將存放在tag名中。
環境變數名:指定需要提取的環境變數名稱。
tag名:環境變數標籤名稱。
Pod標籤相關:配置Pod標籤名和tag名,Pod標籤值將存放在tag名中。
Pod標籤名:需要提取的 Kubernetes Pod 標籤名稱。
tag名:標籤名稱。
5. 輸出配置
預設採集所有日誌發送到當前日誌庫,壓縮方式為lz4。如需將同一來源的日誌分發到不同日誌庫,請參考如下步驟進行配置:
多目標動態分發
多目標發送僅適用於LoongCollector 3.0.0及以上版本,Logtail不支援。
輸出目標最多可配置5個。
配置多個輸出目標後,該採集配置將不再顯示在當前 LogStore 的採集配置列表中。如需查看、修改或刪除多目標分發配置,請參考如何管理多目標分發配置?。
配置步驟:在Logtail設定頁面的輸出配置地區。
單擊
 展開輸出配置。
展開輸出配置。單擊添加輸出目標,完成如下配置:
日誌庫:選擇目標日誌庫。
壓縮方式:支援lz4和zstd。
路由配置:根據日誌的Tag欄位路由分發,滿足路由配置的日誌會被上傳到目標日誌庫,路由配置為空白時表示採集到的所有日誌都會被上傳到目標日誌庫。
Tag名稱:用於路由的Tag欄位名稱,直接填寫欄位名(如
__path__),無需__tag__:首碼。Tag欄位分為如下兩類:關於Tag的詳細資料請參考管理LoongCollector採集Tag。
Agent相關:與採集 Agent 本身相關,不依賴外掛程式。 如
__hostname__、__user_defined_id__等。輸入外掛程式相關:依賴輸入外掛程式,由輸入外掛程式提供並富化相關資訊到日誌中。如檔案採集的
__path__;K8s採集的_pod_name_、_container_name_等。
Tag值:日誌的Tag欄位值與此匹配時,發送到該目標日誌庫。
是否丟棄該Tag欄位:開啟後上傳的日誌中不包含該Tag欄位。
步驟三:查詢與分析配置
在完成Tlog與外掛程式配置後,單擊下一步,進入查詢分析配置頁面:
配置完成後,單擊下一步,完成整個採集流程的設定。
步驟四:驗證與故障排查
完成採集配置並應用到機器組後,系統將自動下發配置並開始採集增量日誌。
查看上報日誌
確認記錄檔有新增內容:LoongCollector只採集增量日誌。執行
tail -f /path/to/your/log/file,並觸發業務操作,確保有新的日誌正在寫入。查詢日誌:進入目標 LogStore 的查詢分析頁面,單擊查詢 / 剖析(預設時間範圍為最近15分鐘),觀察是否有新日誌流入。採集的每條Docker容器文本日誌中預設包含以下欄位資訊:
欄位名
說明
__source__
LoongCollector(Logtail)容器的IP地址。
_container_ip_
業務容器的IP地址。
__tag__:__hostname__
LoongCollector(Logtail)所在Docker主機的名稱。
__tag__:__path__
日誌採集路徑。
__tag__:__receive_time__
日誌到達服務端的時間。
__tag__:__user_defined_id__
機器組的自訂標識。
常見問題排查
機器組心跳串連為fail
檢查使用者標識:如果您的伺服器類型不是ECS,或使用的ECS和Project屬於不同阿里雲帳號,請根據如下表格檢查指定目錄下是否存在正確的使用者標識。
Linux:執行
cd /etc/ilogtail/users/ && touch <uid>命令,建立使用者標識檔案。Windows:進入
C:\LogtailData\users\目錄,建立一個名為<uid>的空檔案。
如果指定路徑下存在以當前Project所屬的阿里雲帳號ID命名的檔案,則說明使用者標識配置正確。
檢查機器組標識:如果您使用了使用者自訂標識機器組,請檢查指定目錄下是否存在
user_defined_id檔案,如果存在請檢查該檔案中的內容是否與機器組配置的自訂標識一致。系統
指定目錄
解決方案
Linux
/etc/ilogtail/user_defined_id# 配置使用者自訂標識,如目錄不存在請手動建立 echo "user-defined-1" > /etc/ilogtail/user_defined_idWindows
C:\LogtailData\user_defined_id在
C:\LogtailData目錄下建立user_defined_id檔案,並寫入使用者自訂標識。(如目錄不存在,請手動建立)如果使用者標識和機器組標識均配置無誤,請參考LoongCollector(Logtail)機器組問題排查思路進一步排查。
日誌採集無資料
檢查是否有增量日誌:配置LoongCollector(Logtail)採集後,如果待採集的記錄檔沒有新增日誌,則LoongCollector(Logtail)不會採集該檔案。
檢查機器組心跳狀態:前往頁面,單擊目標機器組名稱,在地區,查看心跳狀態。
如果心跳為OK,則表示機器組與Log Service Project 串連正常。
如果心跳為FAIL:參考機器組心跳串連為fail進行排查。
確認LoongCollector(Logtail)採集配置是否已應用到機器組:即使LoongCollector(Logtail)採集配置已建立,但如果未將其應用到機器組,日誌仍無法被採集。
前往頁面,單擊目標機器組名稱,進入機器組配置頁面。
在頁面中查看管理設定,左側展示全部Logtail設定,右側展示已生效Logtail設定。如果目標LoongCollector(Logtail)採集配置已移動到右側生效地區,則表示該配置已成功應用到目標機器組。
如果目標LoongCollector(Logtail)採集配置未移動到右側生效地區,請單擊修改,在左側全部Logtail設定列表中勾選目標LoongCollector(Logtail)配置名稱,單擊
 移動到右側生效地區,完成後單擊確定。
移動到右側生效地區,完成後單擊確定。
採集日誌報錯或格式錯誤
排查思路:這種情況說明網路連接和基礎配置正常,問題主要出在日誌內容與解析規則不匹配。您需要查看具體的錯誤資訊來定位問題:
在Logtail設定頁面,單擊採集異常的LoongCollector(Logtail)配置名稱,在日誌採集錯誤頁簽下,單擊時間選擇設定查詢時間。
在地區,查看錯誤記錄檔的警示類型,並根據採集資料常見錯誤類型查詢對應的解決辦法。
後續步驟
常用命令
查看LoongCollector(Logtail)運行狀態
docker exec ${logtail_container_id} /etc/init.d/ilogtaild status查看LoongCollector(Logtail)的版本號碼、IP地址和啟動時間等資訊
docker exec ${logtail_container_id} cat /usr/local/ilogtail/app_info.json查看LoongCollector(Logtail)的作業記錄
LoongCollector(Logtail)作業記錄儲存在容器內的/usr/local/ilogtail/目錄下,檔案名稱為ilogtail.LOG,輪轉檔案會壓縮儲存為ilogtail.LOG.x.gz。樣本如下:
# 查看LoongCollector作業記錄
docker exec a287de895e40 tail -n 5 /usr/local/ilogtail/loongcollector.LOG
# 查看Logtail作業記錄
docker exec a287de895e40 tail -n 5 /usr/local/ilogtail/ilogtail.LOG輸出結果樣本如下:
[2025-08-25 09:17:44.610496] [info] [22] /build/loongcollector/file_server/polling/PollingModify.cpp:75 polling modify resume:succeeded
[2025-08-25 09:17:44.610497] [info] [22] /build/loongcollector/file_server/polling/PollingDirFile.cpp:100 polling discovery resume:starts
[2025-08-25 09:17:44.610498] [info] [22] /build/loongcollector/file_server/polling/PollingDirFile.cpp:103 polling discovery resume:succeeded
[2025-08-25 09:17:44.610499] [info] [22] /build/loongcollector/file_server/FileServer.cpp:117 file server resume:succeeded
[2025-08-25 09:17:44.610500] [info] [22] /build/loongcollector/file_server/EventDispatcher.cpp:1019 checkpoint dump:succeeded重啟LoongCollector(Logtail)
# 停止loongcollector
docker exec a287de895e40 /etc/init.d/ilogtaild stop
# 啟動loongcollector
docker exec a287de895e40 /etc/init.d/ilogtaild start常見問題
常見錯誤資訊
錯誤現象 | 原因 | 解決方案 |
| Project地區與LoongCollector(Logtail)容器不一致 | 檢查 |
| 檔案路徑配置錯誤 | 確認業務容器內日誌路徑與採集配置匹配 |
錯誤記錄檔:The parameter is invalid : uuid=none
問題描述:如果LoongCollector(Logtail)日誌(/usr/local/ilogtail/ilogtail.LOG)中出現The parameter is invalid : uuid=none的錯誤記錄檔。
解決方案:請在宿主機上建立一個product_uuid檔案,在其中輸入任意合法UUID(例如169E98C9-ABC0-4A92-B1D2-AA6239C0D261),並把該檔案掛載到LoongCollector(Logtail)容器的/sys/class/dmi/id/product_uuid目錄。
如何讓同一個記錄檔或容器標準輸出被多個採集配置同時採集?
預設情況下,Log Service為了防止資料重複,限制了每個日誌源只能被一個採集配置採集:
文本記錄檔只能匹配一個 Logtail 採集配置;
容器的標準輸出(stdout) :
如果使用的是標準輸出-新版模板, 預設只能被一個標準輸出採集配置採集。
如果使用的是標準輸出-舊版模板,無需額外配置,預設支援採集多份。
登入Log Service控制台,進入目標Project。
在左側導航選擇
日誌庫,找到目標LogStore。單擊其名稱前的
展開LogStore。單擊Logtail設定,在配置列表中,找到目標Logtail配置,單擊操作列的管理Logtail配置。
在Logtail配置頁面,單擊編輯,下滑至輸入配置地區:
採集文字檔日誌:開啟允許檔案多次採集。
採集容器標準輸出:開啟允許標準輸出多次採集。
如何管理多目標分發配置?
由於多目標分發配置關聯了多個日誌庫,這類配置需要通過 Project 層級的管理頁面進行維護:
登入Log Service控制台,單擊目標Project名稱。
在目標Project頁面,單擊左側導覽列
 。說明
。說明此頁面集中管理Project下的所有採集配置,包括那些因日誌庫被誤刪而殘留的配置。
附錄:原生解析外掛程式詳解
在Logtail設定頁面的處理配置地區,可以通過添加處理外掛程式,對原始日誌進行結構化配置。如需為已有採集配置添加處理外掛程式,可以參考如下步驟:
在左側導覽列選擇
 日誌庫,找到目標LogStore。
日誌庫,找到目標LogStore。單擊其名稱前的
 展開LogStore。
展開LogStore。單擊Logtail設定,在配置列表中,找到目標Logtail配置,單擊操作列的管理Logtail配置。
在Logtail配置頁面,單擊編輯。
此處僅介紹常用處理外掛程式,覆蓋常見Tlog情境,如需更多功能,請參考拓展處理外掛程式。
外掛程式組合使用規則(適用於 LoongCollector / Logtail 2.0 及以上版本):
原生處理外掛程式與拓展處理外掛程式均可獨立使用,也支援按需組合使用。
推薦優先選用原生處理外掛程式,因其具備更優的效能和更高的穩定性。
當原生功能無法滿足業務需求時,可在已配置的原生處理外掛程式之後,追加配置拓展處理外掛程式以實現補充處理。
順序約束:
所有外掛程式按照配置順序組成處理鏈,依次執行。需要注意:所有原生處理外掛程式必須先於任何拓展處理外掛程式,添加任意拓展處理外掛程式後,將無法繼續添加原生處理外掛程式。
正則解析
通過Regex提取日誌欄位,並將日誌解析為索引值對形式,每個欄位都可以被獨立查詢和分析。
效果樣本:
未經任何處理的原始日誌 | 使用正則解析外掛程式 |
| |
配置步驟:在Logtail設定頁面的處理配置地區,單擊添加處理外掛程式,選擇:
Regex:用於匹配日誌,支援自動產生或手動輸入:
自動產生:
單擊自動產生Regex。
在日誌範例中劃選需要提取的日誌內容。
單擊產生正則。
確認 日誌範例 地區中已粘貼正確格式的日誌內容(例如 Apache Combined 格式的訪問日誌),再單擊該地區中的 產生正則 按鈕以自動產生解析Regex。
手動輸入:根據日誌格式手動輸入Regex。
配置完成後,單擊驗證,測試Regex是否能夠正確解析日誌內容。
日志提取欄位:為提取的日誌內容(Value),設定對應的欄位名(Key)。
其他參數請參考情境二:結構化日誌中的通用配置參數說明。
分隔字元解析
通過分隔字元將日誌內容結構化,解析為多個索引值對形式,支援單字元分隔字元和多字元分隔字元。
效果樣本:
未經任何處理的原始日誌 | 按指定字元 |
| |
配置步驟:在Logtail設定頁面的處理配置地區,單擊添加處理外掛程式,選擇:
分隔字元:指定用於切分日誌內容的字元。
樣本:對於CSV格式檔案,選擇自訂,輸入半形逗號(,)。
引用符:當某個欄位值中包含分隔字元時,需要指定引用符包裹該欄位,避免錯誤切割。
日志提取欄位:按分隔順序依次為每一列設定對應的欄位名稱(Key)。規則要求如下:
欄位名只能包含:字母、數字、底線(_)。
必須以字母或底線(_)開頭。
最大長度:128位元組。
其他參數請參考情境二:結構化日誌中的通用配置參數說明。
標準JSON解析
將Object類型的JSON日誌結構化,解析為索引值對形式。
效果樣本:
未經任何處理的原始日誌 | 標準JSON索引值自動提取 |
| |
配置步驟:在Logtail設定頁面的處理配置地區,單擊添加處理外掛程式,選擇:
原始欄位:預設值為content(此欄位用於存放待解析的原始日誌內容)。
其他參數請參考情境二:結構化日誌中的通用配置參數說明。
嵌套JSON解析
通過指定展開深度,將嵌套的JSON日誌解析為索引值對形式。
效果樣本:
未經任何處理的原始日誌 | 展開深度:0,並使用展開深度作為首碼 | 展開深度:1,並使用展開深度作為首碼 |
| | |
配置步驟:在Logtail設定頁面的處理配置地區,單擊添加處理外掛程式,選擇:
原始欄位:需要展開的原始欄位名,例如
content。JSON展開深度:JSON對象的展開層級。0表示完全展開(預設值),1表示當前層級,以此類推。
JSON展開串連符:JSON展開時欄位名的串連符,預設為底線 _。
JSON展開欄位首碼:指定JSON展開後欄位名的首碼。
展開數組:開啟此項可將數組展開為帶索引的索引值對。
樣本:
{"k":["a","b"]}展開為{"k[0]":"a","k[1]":"b"}。如果需要對展開後的欄位進行重新命名(例如,將 prefix_s_key_k1 改為 new_field_name),可以後續再添加一個重新命名欄位外掛程式來完成映射。
其他參數請參考情境二:結構化日誌中的通用配置參數說明。
JSON數組解析
使用json_extract函數,從JSON數組中提取JSON對象。
效果樣本:
未經任何處理的原始日誌 | 提取JSON數組結構 |
| |
配置步驟:在Logtail設定頁面的處理配置地區,將處理模式切換為SPL,配置SPL語句,使用 json_extract函數從JSON數組中提取JSON對象。
樣本:從日誌欄位 content 中提取 JSON 數組中的元素,並將結果分別儲存在新欄位 json1和 json2 中。
* | extend json1 = json_extract(content, '$[0]'), json2 = json_extract(content, '$[1]')Apache日誌解析
根據Apache日誌設定檔中的定義將日誌內容結構化,解析為多個索引值對形式。
效果樣本:
未經任何處理的原始日誌 | Apache通用日誌格式 |
| |
配置步驟:在Logtail設定頁面的處理配置地區,單擊添加處理外掛程式,選擇:
日誌格式:combined
APACHE配置欄位:系統會根據日誌格式自動填滿配置。
重要請務必核對自動填滿的內容,確保與伺服器上 Apache 設定檔(通常位於/etc/apache2/apache2.conf)中定義的 LogFormat 完全一致。
其他參數請參考情境二:結構化日誌中的通用配置參數說明。
資料脫敏
對日誌中的敏感性資料進行脫敏處理。
效果樣本:
未經任何處理的原始日誌 | 脫敏結果 |
| |
配置步驟:在Logtail設定頁面的處理配置地區,單擊添加處理外掛程式,選擇:
時間解析
對日誌中的時間欄位進行解析,並將解析結果設定為日誌的__time__欄位。
效果樣本:
未經任何處理的原始日誌 | 時間解析 |
| 解析 |
配置步驟:在Logtail設定頁面的處理配置地區,單擊添加處理外掛程式,選擇:
原始欄位:解析日誌前,用於存放日誌內容的原始欄位。
時間格式:根據日誌中的時間內容設定對應的時間格式。
時區:選擇日誌時間欄位所在的時區。預設使用機器時區,即LoongCollector(Logtail)進程所在環境的時區。
附錄:Regex使用限制(容器過濾)
容器過濾時所使用的Regex基於Go語言的RE2引擎,與PCRE等其他引擎相比存在部分文法限制。請在編寫Regex時注意以下事項:
1. 命名分組文法差異
Go語言使用 (?P<name>...) 文法定義命名分組,不支援 PCRE中的 (?<name>...) 文法。
正確樣本:
(?P<year>\d{4})錯誤寫法:
(?<year>\d{4})
2. 不支援的正則特性
以下常見但複雜的正則功能在RE2中不可用,請避免使用:
斷言:
(?=...)、(?!...)、(?<=...)、(?<!...)條件運算式:
(?(condition)true|false)遞迴匹配:
(?R)、(?0)子程式引用:
(?&name)、(?P>name)原子組:
(?>...)
3. 使用建議
推薦使用 Regex101等工具調試Regex時,選擇 Golang (RE2) 模式進行驗證,以確保相容性。若使用了上述不支援的文法,外掛程式將無法正確解析或匹配。
附錄:容器標準輸出新舊版本對比
為提升日誌儲存效率與採集一致性,容器標準輸出的日誌元資訊格式已完成升級。新版格式將元資訊統一歸類至 __tag__ 欄位中,實現儲存最佳化和格式標準化。
新版標準輸出核心優勢
效能大幅提升
採用C++重構,相較舊版Go實現,效能提升180%-300%。
支援原生外掛程式處理資料,支援同步多執行緒,充分利用系統資源。
支援原生外掛程式與Go外掛程式靈活組合使用,滿足複雜情境需求。
更強的可靠性
支援標準輸出日誌輪轉隊列,日誌採集機制和檔案採集機制統一,在標準輸出日誌快速輪轉時的情境可靠性高。
更低的資源消耗
CPU使用率降低20%-25%。
記憶體佔用減少20%-25%。
營運一致性增強
參數配置統一:新版標準輸出採集外掛程式的配置參數和檔案採集外掛程式保持一致。
元資訊統一管理:容器元資訊欄位命名和Tag日誌儲存位置,與檔案採集情境進行了統一,消費端只需維護同套處理邏輯。
新舊版本特性對比
特性維度
舊版特點
新版特點
儲存方式
元資訊作為普通欄位直接嵌入日誌內容中
元資訊集中存放於
__tag__標籤中儲存效率
每條日誌重複攜帶完整元資訊,佔用較多儲存空間
相同上下文下的多條日誌可複用元資訊,節省儲存成本
格式一致性
與容器檔案採集格式不一致
欄位命名及儲存結構與容器檔案採集完全對齊,實現統一體驗
查詢訪問方式
可通過欄位名直接查詢(如
_container_name_)需通過
__tag__訪問對應索引值(如__tag__: _container_name_)容器元資訊欄位對應表
舊版欄位名稱
新版欄位名稱
_container_ip_
__tag__:_container_ip_
_container_name_
__tag__:_container_name_
_image_name_
__tag__:_image_name_
_namespace_
__tag__:_namespace_
_pod_name_
__tag__:_pod_name_
_pod_uid_
__tag__:_pod_uid_
所有元資訊欄位在新版中均以
__tag__:<key>形式儲存於日誌的標籤(Tag)地區,而非嵌入日誌內容中。新版變更對使用者影響
消費端適配:由於儲存位置從“內容”變為“Tag”,使用者的日誌消費邏輯需做相應調整(例如查詢時需通過 __tag__ 訪問欄位)。
SQL相容性:查詢SQL已經自動相容適配,因此使用者無需修改查詢語句即可同時處理新舊版本日誌。
更多資訊
全域配置參數介紹
輸入配置參數介紹
處理配置參數介紹
配置項 | 說明 |
日誌範例 | 待採集日誌的範例,請務必使用實際情境的日誌。日誌範例可協助配置Tlog相關參數,降低配置難度。支援添加多條範例,總長度不超過1500個字元。 |
多行模式 |
|
處理模式 | 處理外掛程式組合,包括原生處理外掛程式和拓展處理外掛程式。有關處理外掛程式的更多資訊,請參見原生與拓展處理外掛程式使用說明。 重要 處理外掛程式的使用限制,請以控制台頁面的提示為準。
|



地區
登入Log Service控制台,在Project列表中,單擊目標Project。
單擊Project名稱右側的
 進入專案概覽頁面。
進入專案概覽頁面。在基礎資訊中可查看當前Project的地區名稱,地區名稱對應RegionID請參考下表。
地區代表雲端服務資源的物理資料中心所在的地理位置,RegionID 是雲端服務地區的唯一識別碼。
地區名稱
RegionID
華北1(青島)
cn-qingdao
華北2(北京)
cn-beijing
華北3(張家口)
cn-zhangjiakou
華北5(呼和浩特)
cn-huhehaote
華北6(烏蘭察布)
cn-wulanchabu
華東1(杭州)
cn-hangzhou
華東2(上海)
cn-shanghai
華東5(南京-本地地區-關停中)
cn-nanjing
華東6(福州-本地地區-關停中)
cn-fuzhou
華南1(深圳)
cn-shenzhen
華南2(河源)
cn-heyuan
華南3(廣州)
cn-guangzhou
菲律賓(馬尼拉)
ap-southeast-6
韓國(首爾)
ap-northeast-2
馬來西亞(吉隆坡)
ap-southeast-3
日本(東京)
ap-northeast-1
泰國(曼穀)
ap-southeast-7
西南1(成都)
cn-chengdu
新加坡
ap-southeast-1
印尼(雅加達)
ap-southeast-5
中國香港
cn-hongkong
德國(法蘭克福)
eu-central-1
美國(維吉尼亞)
us-east-1
美國(矽谷)
us-west-1
英國(倫敦)
eu-west-1
阿聯酋(杜拜)
me-east-1
沙特(利雅得)
me-central-1