本文介紹ApsaraDB for SelectDB支援通過Bucket Shuffle Join進行查詢最佳化,能夠減少資料在節點間的傳輸耗時和Join時的記憶體開銷,進而最佳化查詢效能。
功能簡介
Bucket Shuffle Join旨在為某些Join查詢提供基於本地的最佳化,減少資料在節點間的傳輸耗時來加速查詢。Bucket Shuffle Join的設計、實現和效果的詳細資料,請參見ISSUE 4394。
名稱解釋
左表:Join查詢時左邊的表,進行Probe操作,可被Join Reorder調整順序。
右表:Join查詢時右邊的表,進行Build操作,可被Join Reorder調整順序。
工作原理
SelectDB支援的常規分布式Join方式包括Shuffle Join和Broadcast Join。這兩種Join都會導致相當大的網路開銷。
例如,當前存在A表與B表的Join查詢,它的Join方式為Hash Join,不同Join類型的開銷如下:
Broadcast Join:如果根據資料分布,查詢規划出A表有3個執行的HashJoinNode,那麼需要將B表全量的資料發送到這3個HashJoinNode。這次查詢的網路開銷是3倍的B表資料量,記憶體開銷也是3倍的B表資料量。
Shuffle Join:Shuffle Join會根據雜湊計算,將A、B兩張表的資料分散到叢集的節點之中,所以這次操作的網路開銷為
A表資料量+B表資料量,記憶體開銷為B表資料量。
FE中儲存了SelectDB每個表的資料分布資訊。如果Join語句命中了表的資料分布列,則應該使用資料分布資訊來減少Join語句的網路與記憶體開銷,這就是Bucket Shuffle Join的思路來源。
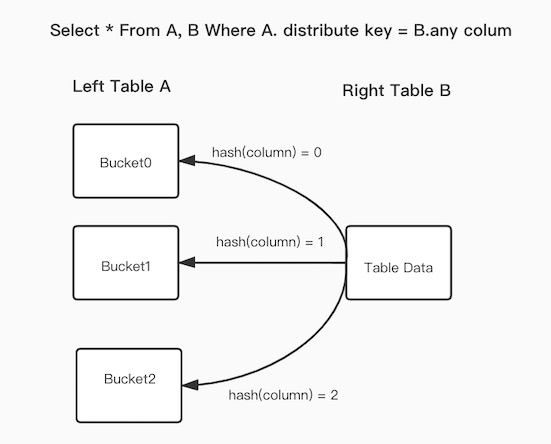
上圖展示了Bucket Shuffle Join的工作原理。在SQL語句中,A表與B表進行了Join操作,並且Join的等值運算式與A表的資料分布列相吻合。Bucket Shuffle Join會根據A表的資料分布資訊,將B表的資料發送到對應的A表的資料存放區計算節點。Bucket Shuffle Join開銷如下:
網路開銷:B表資料量。小於常規Join方式的網路開銷,其中Broadcast Join為
3倍的B表資料量,Shuffle Join為A表資料量+B表資料量記憶體開銷:B表資料量。小於等於常規Join方式的記憶體開銷,其中Broadcast Join為
3倍的B表資料量,Shuffle Join為B表資料量。
相比於Broadcast Join與Shuffle Join, Bucket Shuffle Join有著較為明顯的效能優勢,可以減少資料在節點間的傳輸耗時和Join時的記憶體開銷。相對於SelectDB原有的Join方式,Bucket Shuffle Join有如下優點:
Bucket Shuffle Join降低了網路與記憶體開銷,使一些Join查詢具有了更好的效能。尤其是當FE能夠執行左表的分區裁剪與桶裁剪時。
與Colocate Join不同,Bucket Shuffle Join對於表的資料分布方式並沒有侵入性,這對於您來說是透明的。對於表的資料分布沒有強制性的要求,不容易導致資料扭曲問題。
可以為Join Reorder提供更多可能的最佳化方向。
使用方式
設定Session變數
將Session變數enable_bucket_shuffle_join設定為true,則FE在進行查詢規劃時就會預設將能夠轉換為Bucket Shuffle Join的查詢自動規劃為Bucket Shuffle Join。
set enable_bucket_shuffle_join = true;在FE進行分散式查詢規劃時,優先選擇的順序為Colocate Join > Bucket Shuffle Join > Broadcast Join > Shuffle Join。但是如果您顯式hint了Join的類型,則上述的選擇優先順序不生效,優先選擇hint方式的Join類型。例如:
SELECT * FROM test JOIN [shuffle] baseall ON test.k1 = baseall.k1;查看Join的類型
通過explain命令來查看Join是否為Bucket Shuffle Join:
| 2:HASH JOIN |
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
| | hash predicates: |
| | colocate: false, reason: table not in the same group |
| | equal join conjunct: `test`.`k1` = `baseall`.`k1` 在Join類型之中會指明使用的Join方式為:BUCKET_SHUFFLE。
Bucket Shuffle Join的規劃規則
在絕大多數情況下,您只需將Session變數的開關設為true,就能透明地體驗Bucket Shuffle Join所帶來的效能提升。然而,如果瞭解Bucket Shuffle Join的規劃規則,您就能編寫出更高效的SQL語句。
Bucket Shuffle Join只生效於Join條件為等值的情境,原因與Colocation Join類似,都依賴hash計算來確定資料分布。
在等值Join條件中包含兩張表的分桶列,當左表的分桶列為等值的Join條件時,它有很大機率會被規劃為Bucket Shuffle Join。
由於不同資料類型的hash值計算結果不同,因此,Bucket Shuffle Join要求左表分桶列的類型與右表等值Join列的類型保持一致,否則無法進行對應的規劃。
Bucket Shuffle Join只作用於SelectDB原生的OLAP表。對於ODBC,MySQL,ES等外表,當其作為左表時無法進行有效規劃。
對於分區表而言,由於每個分區的資料分布規則可能不同,因此只有在左表為單分區時,Bucket Shuffle Join才會生效。所以在SQL執行之中,需要盡量使用
where條件,以確保分區裁剪的策略能夠生效。如果左表為Colocate的表,那麼它每個分區的資料分布規則是確定的。在Colocate表上,Bucket Shuffle Join的表現更好。