通過離線全量Key分析功能來分析Tair (Redis OSS-compatible)的備份檔案,可以快速發現執行個體中的大Key,協助您掌握Key在記憶體中的佔用和分布、Key到期時間等資訊,為您的最佳化操作提供資料支援,協助您避免因Key傾斜引發的記憶體不足、效能下降等問題。
該功能由CloudDBA的緩衝分析提供。
適用範圍
操作步驟
訪問執行個體列表,在上方選擇地區,然後單擊目標執行個體ID。
在左側導覽列,單擊。
離線全量Key分析頁簽預設展示最近一天緩衝分析結果清單,您可以根據需求選擇其他時間段。
在離線全量Key分析頁簽,單擊頁面右側的立即分析。
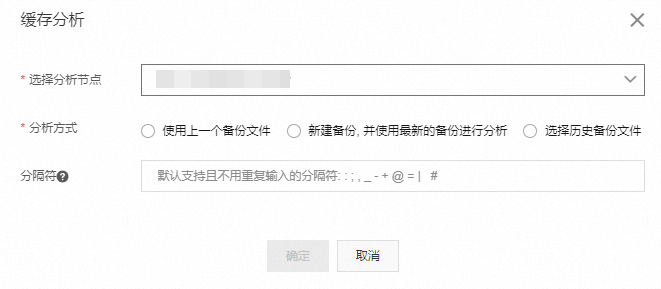
在彈出的對話方塊中,設定分析的節點與方式。
參數
說明
選擇分析節點
選擇需要執行緩衝分析的節點ID。
說明您可以選擇分析整個執行個體,也可以只選中某個節點進行分析。
分析方式
您可以按照介面提示,選擇不同的備份檔案。
使用上一個備份檔案:分析當前最新的備份檔案。
選擇歷史備份檔案:允許選擇並分析任意歷史備份檔案。
建立備份, 並使用最新的備份進行分析:立即建立一次備份,待備份完成後對其進行分析,該方式可分析執行個體當前的狀態。
說明在分析已存在的備份檔案時,請確認備份檔案的時間點,是否符合預期。
分隔字元
根據需要,輸入用於識別Key首碼的分隔字元。當分隔字元為預設的
:;,_-+@=|#時,不需要輸入。單擊確定。
系統執行分析並展示分析狀態,您可以單擊重新整理以更新分析狀態。
找到已完成的分析任務,單擊其操作列的詳情展示詳細的分析結果。
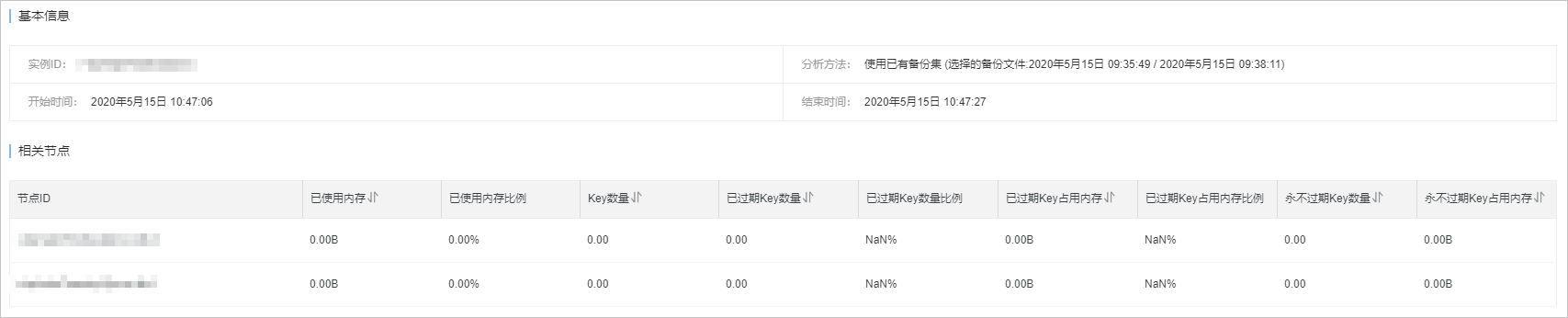
基本資料:展示執行個體基本屬性和緩衝分析方法等資訊。

相關節點:展示執行個體內各節點的記憶體情況和Key統計資訊。
 說明
說明當執行個體為叢集或讀寫分離架構,且選擇的分析節點為整個執行個體時,詳情頁才會展示相關節點資訊並提供節點選擇的功能。
詳情:展示執行個體或節點的Key記憶體佔有情況、Key數量分布情況、Key中元素的記憶體佔用和分布情況、Key到期時間分布、大Key排名等資訊。

常見問題
Q:分析出大量已到期的Key怎麼辦?
A:當業務中資料設定了到期時間,且執行個體在同一時間(時間段)到期大量Key時,可能會出現該情況。此時,除了依靠執行個體自動清除到期資料外,您可以通過控制台上的清除資料功能快速清除到期Key,更多資訊請參見如何清除到期Key。
Q:若使用RAM帳號,操作時提示許可權不足怎麼辦?
A:請對RAM帳號進行授權並重試,更多資訊請參見常見自訂權限原則情境及樣本。
Q:在同一個執行個體中,為什麼執行離線分析任務的速度時快時慢?
A:離線分析任務是非同步任務,分析速度還與CloudDBA的當前總任務數有關,當總任務數較多時,該離線分析任務需排隊等待,分析任務的耗時就會變長。
Q:如何處理報錯
decode rdbfile error: rdb: unknown object type 116 for key?A:該報錯表示執行個體中存在非標準的Bloom結構,暫不支援分析。
Q:如何處理報錯
decode rdbfile error: rdb: invalid file format?A:該報錯表示所選的備份檔案無效,請檢查執行個體是否在該備份時間點後進行了變更配置;或者執行個體是否開啟了透明資料加密TDE(該功能無法分析已加密的資訊)。
Q:如何處理報錯
decode rdbfile error: rdb: unknown module type?A:該報錯表示備份檔案中存在Tair自研資料結構,暫不支援分析。
Q:如何處理建立備份, 並使用最新的備份進行分析後報錯
XXX backup failed?A:該執行個體當前存在正在執行的BGSAVE或BGREWRITEAOF命令,導致建立用於緩衝分析任務的備份時出現了失敗的情況。建議您選擇業務低峰期建立備份,並使用最新的備份進行分析或者選擇歷史備份檔案進行分析。
Q:為什麼緩衝分析結果展示的Key記憶體佔有會比實際使用的記憶體小?
A:因為緩衝分析結果實際只是解析了Key和對應value在RDB中序列化後佔用的大小,這個只佔用了used_memory中的一部分,used_memory還包含了如下部分:
Key和value所對應的struct和指標大小。在jemalloc分配後,位元組對齊部分所佔用的大小也沒計算在used_memory中,例如在2.5億Key的數量下,struct、指標、位元組對齊這三部分的大小加起來約有2~3 GB。
用戶端輸出緩衝區、查詢緩衝區、AOF重寫緩衝區和主從複製的backlog,這些也沒計算到緩衝分析中。
Q:Redis緩衝分析的首碼分隔字元是什嗎?
A:目前Redis緩衝分析的首碼分隔字元是按照固定的首碼
:;,_-+@=|#區分的字串。Q:為什麼Redis緩衝分析中String類型Key的元素數量和元素長度是一樣的?
A:在Redis緩衝分析中,針對String類型的Key,其元素數量就是其元素長度。
Q:為什麼Stream資料結構的緩衝分析結果是實際值的數倍?
A:Stream資料結構底層使用基數樹(Radix Tree)和緊湊列表(listpack),資料結構複雜。緩衝分析功能目前無法精確獲得此類複雜資料結構的記憶體佔用情況,只能進行估算,因此緩衝分析結果存在偏差。
說明緩衝分析結果的偏差僅為資料統計偏差,不影響資料庫執行個體的功能。
相關API
API介面 | 說明 |
建立緩衝分析任務。 | |
查詢快取分析任務詳情。 | |
查詢快取分析工作清單。 |