為提供持續、穩定且優質的雲資料庫服務,我們可能會對您的部分執行個體發起計劃營運事件進行軟硬體、配置升級和網路換代升級,事件類型涉及執行個體遷移、主備切換、版本升級、參數調整等。營運事件通常會產生執行個體串連閃斷影響,請確保業務應用具備斷線重連機制。實際影響請以各事件對應的具體影響說明為準。
事件通知說明
計劃內事件通常會提前1~3天根據訊息中心相關配置()下發郵件通知到訊息訂閱人,請確保您的主帳號配置了正確的接收人並開啟郵件通道訂閱。當您接收到標題為“資料庫計劃內營運事件通知”的通知後,您可以在對應產品控制台的事件中心(或事件管理)的計劃內事件頁面中查看具體的事件類型、地區、原因、取消風險以及涉及的執行個體列表,也可以根據需要調整執行個體計劃切換時間為業務低峰期。
注意事項
事件按緊急程度不同分為兩類:
【S0緊急層級】風險修複:通常是非預期的需要儘快修複避免故障的情境,因此其通知可能會提前3天或更早且允許修改計劃切換時間的視窗更小,典型情境為緊急問題版本替換升級、宿主機異常修複、SSL認證到期升級等。
【S1計劃層級】系統維護:通常是低風險問題修複或有計劃的軟硬體升級換代,通常提前3天以上發送通知且允許使用者取消事件。
為了確保您能接收營運事件的預約通知,您需要登入訊息中心,確保雲資料庫故障或營運通知的通知方式複選框處於選中狀態並設定訊息接收人(推薦設定為資料庫營運人員),否則您將無法收到事件通知資訊。通知方式為郵件、站內信,建議選中郵件,提高觸達成功率。

圖1 訊息中心通知設定入口
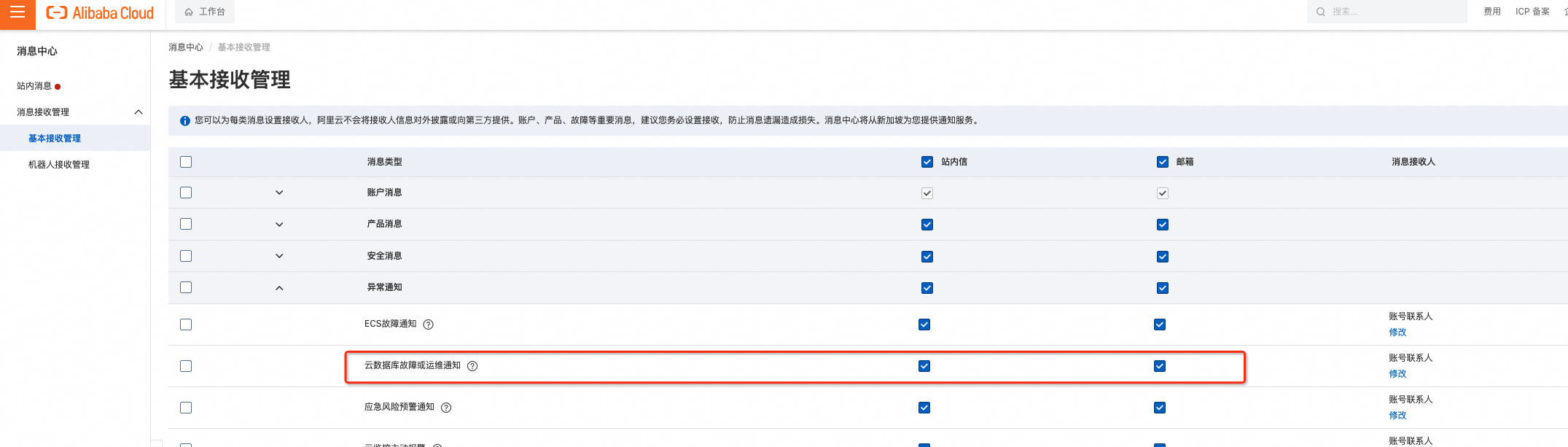
圖2 雲資料庫通知設定
如您需要第一時間獲知營運事件的動態或者希望通過事件驅動的方式做自訂營運自動化,您可以通過CloudMonitor平台配置系統事件訂閱。雲資料庫會對營運事件的生命週期(預約、開始、完成、取消等)推送CloudMonitor系統事件。具體操作,請參見管理事件訂閱(推薦),可訂閱的CloudMonitor事件參見附錄1 CloudMonitor相關係統事件。
操作步驟
登入各產品管理主控台。
在左側導覽列單擊,並在控制台上方選擇地區。
在計劃內事件頁面,可查看事件詳細資料,預設顯示的為計劃中未完結的事件,查看歷史已完結事件可以點擊已完成或已取消切換查詢,事件屬性的詳細介紹如下:
屬性
樣本
說明
事件類型
風險修複
事件按緊急程度不同分為“風險修複”和“系統維護”。
運行狀態
等待執行
事件的調度狀態,需要關注的狀態如下:
等待設定時間:事件的執行時間為空白,需要您根據業務情況設定時間,如果截至最晚操作時間仍未設定時間,系統會自動取消且不會自動執行。
等待執行:事件等待到達計劃開始時間進入到調度階段。
執行中:事件進入調度執行,此時無法人工幹預,如需緊急終止需要提工單(非標操作可能有未知風險)。
成功結束:執行成功。
已取消:執行失敗或取消,常見取消原因。
客戶自主取消(UserCancel):使用者在控制台或通過OpenAPI取消。
客戶響應逾時(UserResponseTimeout):需要指定時間的事件超截止時間未設定時間,事件自動取消。
資料庫管控取消(SupervisorCancel):事件發起端主動取消。
無需執行的規避性取消(AvoidCancel):風險已解除或執行個體目前狀態已無需執行此事件,比如執行個體已經是最新版本無需再做升級。
系統自動取消(AutoCancel):系統會對計劃中事件定期巡檢,如果執行個體不具備執行事件條件可能會被取消,比如當前執行個體狀態異常無法下發動作。
執行逾時(ExecuteTimeout):事件進入執行隊列未在預期時間內完結。
執行失敗(ExecuteFail):事件執行過程中有未知異常失敗。
事件類型
小版本升級
參見事件的類型與影響。
事件原因
-
業務影響
執行個體閃斷
不同事件的業務影響不同,參見事件的類型與影響。
營運建議
確認業務應用具備資料庫自動重連機制並關注業務影響
不同事件的營運建議不同,參見附錄1 CloudMonitor相關係統事件。
計劃開始時間
-
事件開始進入到調度隊列的時間,在開始時間之前,此事件對執行個體無任何影響,過了開始時間您仍可正常訪問資料庫,但是無法執行執行個體層級的操作(例如變更配置、遷移可用性區域等);狀態為“等待設定時間”時此時間為空白。
計劃切換時間
-
主備或鏈路切換(如果有)的時間,通常指執行個體串連有閃斷影響的時間;此時間是預估值,發生切換在此時間附近都符合預期,極端情況下,比如涉及回切可用性區域情境下可能有二次切換。
說明考慮到事件調度、資料準備耗時等因素通常在切換之前需要一定的前置準備時間,因此開始時間和切換時間有一定間隔,不同資料庫產品不同事件間隔可能不同。
最晚操作時間
-
可設定切換時間的最晚時間,要調整的切換時間不能晚於此時間。
是否可取消
是
如需屏蔽本次事件您可以操作取消,通常“系統營運”類事件開放此功能。
重要計劃事件通常是雲資料庫管控系統定期巡檢下發,當次取消後可能會在下個巡檢周期有新事件下發,如果頻繁取消也可能會出現風險升級,建議您根據業務情況選擇合適時間執行而不是取消事件。取消後的風險參見附錄2 詳細原因碼和取消風險。
是否可改時間
是
絕大多數都可以調整事件執行時間,很少情境的高危風險緊急修複沒有足夠的執行時間調整視窗可能不允許調整時間。
修改計劃事件(可選)。
可選中需要調整執行時間的記錄,點擊修改計劃事件進入設定切換時間介面,支援兩種修改方式:
立即執行:即任務開始時間將設定為目前時間,隨後進入執行隊列立即執行。
指定切換時間:根據可配置切換時間範圍選擇合適的時間點作為切換時間執行,開始時間將會根據切換時間自動計算,但新的開始時間不能早於目前時間,否則無法修改。
修改周期時間視窗(可選)。
點擊事件列表右上方的“周期時間視窗配置”可進入周期時間視窗配置頁面。
計劃內事件的執行時間通常是根據執行個體的營運時間自動計算的(參見設定可維護時間段 RDS|Tair/Redis|MongoDB|PolarDB),您也可以根據自己的營運需要自訂周期時間視窗,雲資料庫在後續發起新事件時會優先根據您設定的時間視窗編排計算執行時間。
支援按月或周兩個維度設定視窗,例如設定的周期切換時間為每周一、周二的02:00~03:00,雲平台的計劃事件視窗為本周二至下周日,則事件的切換時間會命中本周二的02:00~03:00和下周一的02:00~03:00,通常優先選擇本周二切換。
重要此配置僅對未來新的事件有效,當前事件列表中的事件如果希望調整時間請點擊“設定執行時間”
此配置僅作為輔助計算執行時間的配置且僅對事件類型為“系統維護”的事件有效,實際計算的執行時間請以事件列表的時間為準。
此配置為帳號層級配置,配置後所有支援周期時間的資料庫產品均會同步生效。
取消計劃事件(可選)。
可選中需要取消的事件記錄,點擊取消計劃事件進入取消介面,知曉取消風險後可點擊確認發起取消。
事件的類型與影響
事件類型 | 說明 | 影響類型 | 影響 |
執行個體遷移 | 因主機風險、硬體過保或作業系統升級而發起的計劃內營運操作,系統會將執行個體遷移至新的伺服器節點,包含非高可用執行個體和唯讀執行個體。 | 執行個體閃斷 | |
主備切換 | 因主機風險、硬體過保或作業系統升級而發起的計劃內營運操作,系統會將發起主備節點切換操作,僅包含高可用執行個體。 | ||
執行個體參數調整 | 因已知的參數風險而發起的計劃內營運操作,系統會對執行個體發起參數修改操作,如果下發的參數包含需要重啟的參數,則執行個體會被重啟。 | ||
主機風險修複 | 修複執行個體所屬主機存在的故障風險。 | ||
SSL認證更新 | 為保障執行個體持續提供更出色的安全性和穩定性,當執行個體的SSL認證即將到期時會發起該操作。 | ||
備份模式升級 | 為保障執行個體提供更快速的備份恢複能力,將執行個體的備份模式從邏輯備份切換到物理庫表備份。 | ||
可用性區域遷移 | 對部分老、舊地區和可用性區域的物理基礎設施進行升級和技術改造。 | ||
小版本升級 | 為提升使用者體驗,雲資料庫會不定期地發布執行個體的小版本,用於豐富雲產品功能或修複已知缺陷。 | 執行個體閃斷 | 進入計劃切換時間後,將產生下述影響: 說明 待處理事件通常會產生執行個體切換操作,該操作將在計劃切換時間之後的執行個體可維護時間段執行。 |
小版本號碼間的差異 | 不同的小版本號碼(核心版本號碼)更新的內容有所區別,您需要關注升級後的小版本和當前小版本的差異,具體請參見相關產品的小版本更新日誌(部分產品暫未開放小版本更新日誌):
| ||
代理小版本升級 | 為提升使用者體驗,雲資料庫會不定期地發布代理節點(Proxy)的小版本,用於豐富代理服務的功能或修複已知缺陷。 | 執行個體閃斷 | 進入計劃切換時間後,將產生下述影響: 說明 待處理事件通常會產生執行個體切換操作,該操作將在計劃切換時間之後的執行個體可維護時間段執行。 |
小版本號碼間的差異 | 不同的小版本號碼更新的內容有所區別,您需要關注升級後的小版本和當前小版本的差異,具體請參見相關產品的小版本更新日誌(部分產品沒有代理節點或暫未開放代理節點更新日誌):
| ||
網路升級 | 為提升執行個體的網路效能和穩定性而升級網路硬體。 | 執行個體閃斷 | 進入計劃切換時間後,將產生下述影響: 說明 待處理事件通常會產生執行個體切換操作,該操作將在計劃切換時間之後的執行個體可維護時間段執行。 |
VIP直連影響 | 部分網路升級過程中可能涉及跨可用性區域遷移,執行個體的虛擬IP(VIP)地址會發生改變,如果用戶端使用VIP串連雲資料庫將會引起串連中斷。 說明 為避免影響,您應當使用執行個體提供的網域名稱形式的串連地址,同時關閉應用及其所屬伺服器的DNS緩衝。 | ||
儲存網關升級 | 為提升執行個體的儲存效能和穩定性而升級儲存網關。 | I/O 抖動 | 可能出現短暫的I/O抖動或SQL時延增加,影響的時間不超過3秒。 |
開啟無感遷移能力 | 為提升使用者體驗而開啟無感遷移。 | 參數修改 | 無影響。 說明 不涉及重啟遷移,對您當前業務無影響。 |
代理遷移 | 代理所在宿主機升級或維護,提高代理節點穩定性。 | 代理節點遷移 | 代理節點遷移過程中,執行個體地址和自訂地址會出現一次閃斷,閃斷時間不超過10秒。 |
受影響執行個體
如果系統提示的計劃切換時間不合適,您可以將計劃切換時間設定在該事件產生後30天內的某個時間點。
如需第一時間獲知待處理事件的動態(例如事件的產生和執行情況),您可以通過CloudMonitor平台配置事件警示。具體操作,請參見訂閱事件通知。
執行個體類型 | 引擎 | 相關文檔 |
不涉及 |
常見問題
關於通知
關於開始時間和切換時間
關於事件操作
其他問題
附錄
附錄1 CloudMonitor相關係統事件
事件代碼 | 事件名稱 | 觸發時機 | 營運建議 |
Instance:SystemMaintenance.MinorVersionUpgrade:Scheduled | 執行個體小版本升級(計劃中) | 發起小版本升級預約 | 事件未開始,執行個體可用性無影響。 |
Instance:SystemMaintenance.MinorVersionUpgrade:ReminderNotice | 執行個體小版本升級(執行前提醒) | 開始執行前7天、3天、1天分別推送一次 | INFO層級通知事件,事件未執行。 |
Instance:SystemMaintenance.MinorVersionUpgrade:Executing | 執行個體小版本升級(開始執行) | 開始執行小版本升級 | 事件開始進入到執行隊列,此狀態下通常不允許人工幹預,容易出現未知問題。 |
Instance:SystemMaintenance.MinorVersionUpgrade:Executed | 執行個體小版本升級(執行完成) | 完成小版本升級 | 事件執行成功,過程中可能有主備切換,請觀察業務影響。 |
Instance:SystemMaintenance.MinorVersionUpgrade:Canceled | 執行個體小版本升級(已取消) | 小版本升級失敗或取消 | 事件執行失敗或因為部分原因(比如已經是最新版本無需升級)自動取消,執行個體可用性無影響。 |
Instance:SystemMaintenance.Transfer:ReminderNotice | 執行個體遷移(執行前提醒) | 開始執行前7天、3天、1天分別推送一次 | INFO層級通知事件,事件未執行。 |
Instance:SystemMaintenance.Transfer:Scheduled | 執行個體遷移(計劃中) | 發起執行個體遷移預約 | 事件未開始,執行個體可用性無影響。 |
Instance:SystemMaintenance.Transfer:Executing | 執行個體遷移(開始執行) | 開始執行執行個體遷移 | 事件開始進入到執行隊列,此狀態下通常不允許人工幹預,容易出現未知問題。 |
Instance:SystemMaintenance.Transfer:Executed | 執行個體遷移(執行完成) | 完成執行個體遷移 | 事件執行成功,過程中可能有主備切換,請觀察業務影響。 |
Instance:SystemMaintenance.Transfer:Canceled | 執行個體遷移(已取消) | 執行個體遷移失敗或取消 | 事件執行失敗或因為部分原因(比如使用者提前手動遷移過執行個體)自動取消,執行個體可用性無影響。 |
Instance:SystemMaintenance.ScheduledOperation:ReminderNotice | 執行個體計劃內營運事件(執行前提醒) | 開始執行前7天、3天、1天分別推送一次 | INFO層級通知事件,事件未執行。 |
Instance:SystemMaintenance.ScheduledOperation:Scheduled | 執行個體計劃內事件(計劃中) | 其他計劃營運事件預約 | 事件未開始,執行個體可用性無影響。 |
Instance:SystemMaintenance.ScheduledOperation:Executing | 執行個體計劃內事件(開始執行) | 開始計劃營運事件執行 | 事件開始進入到執行隊列,此狀態下通常不允許人工幹預,容易出現未知問題。 |
Instance:SystemMaintenance.ScheduledOperation:Executed | 執行個體計劃內事件(執行完成) | 完成計劃營運事件 | 事件執行成功,過程中可能有主備切換,請觀察業務影響。 |
Instance:SystemMaintenance.ScheduledOperation:Canceled | 執行個體計劃內事件(已取消) | 計劃營運事件執行失敗或取消 | 執行個體可用性無影響。 |
更多資訊,請參見支援的雲產品及其系統事件。
附錄2 詳細原因碼和取消風險
詳細原因碼 | 詳細原因描述 | 取消風險碼 | 取消風險徵兆 | 補充說明 | 觸發事件周期 |
InfraArchUpgrade | 底層基礎設施架構替換升級 | OutOfGoodPerfByHardwareUpgrade | 將無法體驗軟體升級後更好的效能和穩定性。 | 隨著產品形態和底層依賴的計算、儲存、網路等資源的架構升級換代,為了提升雲產品的服務品質和穩定性而下發執行個體升級或遷移動作。 | 月/季度 |
EnhanceStabilityAndResUtil | 提升執行個體穩定性和資源使用率 | ImpactStabAndResContention | 影響執行個體穩定性,潛在影響為資源爭搶、核心漏洞、效能低於預期。 | - | 不定期 |
EnableHotReplica | 開啟無感遷移後,將極大提升資料庫執行個體的高可用能力,加速執行個體升降配、小版本升級、執行個體遷移等主動營運的速度,且對前端業務無感。 | - | - | - | - |
KernalExceptionRepair | 核心原因導致執行個體異常問題修複 | RiskEscatateToFailure | 風險可能升級為故障,影響執行個體可用性。 | 常見於核心緊急版本風險修複。 | 不定期 |
OldKernelVersionWithHardwareUpgrade | 核心版本到期升級同時升級硬體資源 | KernelVersionEndOfLife | 核心版本生命週期結束,同時執行個體無法使用新功能和效能最佳化。 | 常見於例行版本更新升級。 | 月/季度 |
KernelBugFix | 核心漏洞修複 | RiskEscatateToFailure | 風險可能升級為故障,影響執行個體可用性。 | 常見於核心緊急版本bugFix。 | 不定期 |
HostLoadHigh | 宿主機負載高 | HostLoadHighAffectStability | 宿主機負載過高對執行個體的效能和穩定性存在一定影響。 | 常見於宿主機硬體風險規避。 | 不定期 |
SoftwareUpgrade | 宿主機軟體升級 | OutOfGoodPerfByHardwareUpgrade | 將無法體驗軟體升級後更好的效能和穩定性。 | 宿主機作業系統或依賴外掛程式冷升級。 | 月/季度 |
HardwareUpgrade | 底層硬體替換升級 | OutOfGoodPerfBySoftwareUpgrade | 將無法體驗軟體升級後更好的效能和穩定性。 | 宿主機硬體升級。 | 月/季度 |
HostSoftHardwareUpgrade | 宿主機軟體/硬體升級 | OutOfGoodPerfBySoftHardwareUpgrade | 將無法體驗軟體升級後更好的效能和穩定性。 | 宿主機軟硬體升級。 | 月/季度 |
ProxyNodeHostMaintain | 代理節點所在宿主機維護/升級 | ProxyNodeHost Maintenance/Upgrade | 宿主機風險影響代理節點穩定性。 | - | - |
HostCPUException | 宿主機CPU異常 | RiskEscatateToFailure | 風險可能升級為故障,影響執行個體可用性。 | - | 不定期 |
HostMemException | 宿主機記憶體異常 | RiskEscatateToFailure | 風險可能升級為故障,影響執行個體可用性。 | - | 不定期 |
HostDiskException | 宿主機磁碟異常 | RiskEscatateToFailure | 風險可能升級為故障,影響執行個體可用性。 | - | 不定期 |
KernelVersionWithServerlessUpgrade | 核心版本升級,同時公測執行個體升級至正式版。 | BetaVersionEndOfLife | 公測版本生命週期結束,執行個體無法使用新功能和效能最佳化。 | - | 月/季度 |
ParamRiskRepairOrOptimize | 參數風險修複或最佳化 | UnknownRisks | 可能導致未知風險。 | 常見於雲資料庫有不合理的參數設定而下發的自動調優。 | 月/季度 |
PGOldKernelVersionWithHardwareUpgrade | 核心版本到期升級同時升級硬體資源,可能導致資料庫連接埠和跨庫串連串改變;由於Timescaledb、Postgis以及Ganos外掛程式在版本過低情況下會不可用,因此會升級外掛程式到最新版本。 | KernelVersionEndOfLife | 核心版本生命週期結束,同時執行個體無法使用新功能和效能最佳化。 | - | 月/季度 |
MaxScaleExceptionRepair | 代理組件風險修複 | RiskEscatateToFailure | 風險可能升級為故障,影響執行個體可用性。 | 常見於代理服務的緊急版本風險修複。 | 不定期 |
OriginalNetWorkHasFlawWithSqlTimeoutAndDIsconnection | 原網路模式存在缺陷,會導致慢sql逾時報錯以及偶發斷連,升級之後可提高穩定性。 | FlawNotResolvedAndAbnormalConnectionMayOccur | 網路模式缺陷未解決,可能出現串連異常問題。 | - | 不定期 |
附錄3 事件類型
中文描述 | 英文描述 |
執行個體遷移 | Instance migration |
小版本升級 | Minor version update |
網路升級 | Network upgrade |
主備切換 | Primary/secondary switchover |
SSL認證更新 | SSL certificate update |
代理小版本升級 | Proxy minor version update |
執行個體參數調整 | Instance config modify |
大版本升級 | Major version update |
開啟無感遷移能力 | Enable Hotreplica Migration |
代理遷移 | Instance Proxy Migration |