PolarDB-X是一款支援HTAP(Hybrid Transaction/Analytical Processing)的資料庫,在支援高並發、事務性請求的同時,也對分析型的複雜查詢提供了良好的支援。
查詢最佳化工具
PolarDB-X的最佳化器面向HTAP負載設計,對複雜查詢有著良好的支援。TP(Transaction Processing)類事務型查詢包含的表數量通常有限(例如3個以內),並且Join條件往往被索引覆蓋,且查詢涉及的資料量較小。而對於不符合上述特徵的複雜查詢,對最佳化器提出了更高的要求。
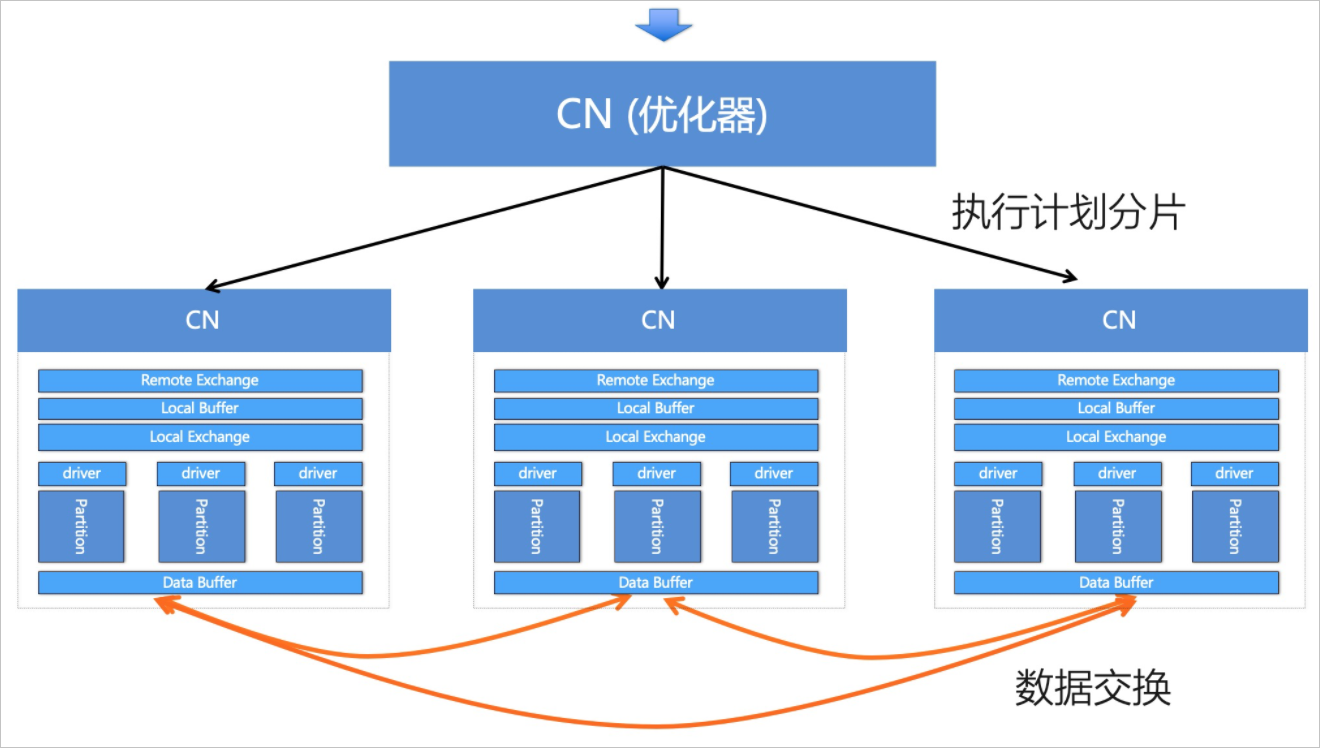
PolarDB-X採用了基於代價的最佳化器技術,能夠根據實際資料量、資料分布情況等,搜尋到較優的執行計畫,例如,對Join順序進行調整、選擇合適的Join或彙總演算法,對關聯子查詢去關聯化等。執行計畫的好壞很大程度上決定了查詢效率,查詢最佳化對於AP(Analytical Processing)類分析型查詢至關重要。
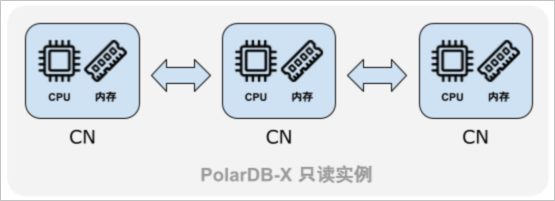
讀寫分離
當線上業務流量比較多時,對PolarDB-X主執行個體壓力比較大。此種情境下,PolarDB-X建議您購買唯讀執行個體,按照預先設定好的比例將一部分TP類讀查詢通過主執行個體CN轉寄給唯讀DN,這個過程稱為讀寫分離。通過讀寫分離對讀流量進行分流,可以減輕主執行個體儲存層DN的讀壓力。
- 強一致性讀:路由到唯讀執行個體的請求,保證一定能夠查詢到讀請求執行前在主執行個體上已完成更新的資料,提供外部強一致性;
- 弱一致性讀:路由到唯讀執行個體的請求,讀請求僅訪問唯讀執行個體上當前的最新資料,會因為主從非同步複製的架構產生資料讀取延遲。
您可以通過Hint指定哪些讀SQL在主執行個體上執行,也可以預先設定讀寫比例,詳情請參見配置讀寫分離。
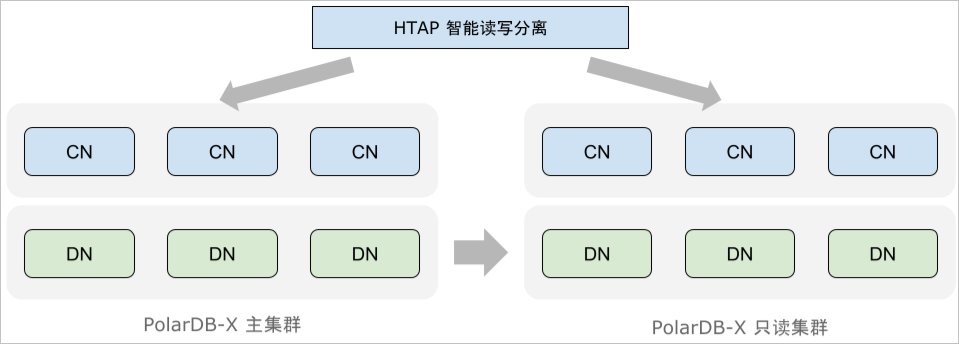
智能讀寫分離現階段,HTAP資料庫實際應用的一大障礙是AP類查詢對TP類查詢的影響。為瞭解決這一問題,PolarDB-X建議您部署獨立的唯讀執行個體,唯讀執行個體與原執行個體在硬體資源上完全分離,從而將AP類查詢對TP類查詢的影響降到最低。
PolarDB-X最佳化器支援基於代價將請求區分為TP與AP,其中AP查詢會被進一步改寫為分布式執行計畫,發往唯讀執行個體進行計算,避免它對主執行個體的TP類查詢造成影響,這個過程稱為智能讀寫分離。
分布式執行
全域一致性讀
傳統讀寫分離架構下,資料複製的延遲可能帶來的資料寫後讀(read-after-write)不一致問題。PolarDB-X中,對於路由給唯讀執行個體的查詢,預設開啟全域一致性讀能力,確保業務不會讀到到期的資料,向主執行個體寫入成功後能在唯讀庫讀到寫入的資料。