PolarDB MySQL版叢集的每種叢集規格都有對應的最大儲存容量,儲存空間會因資料、日誌及臨時檔案的持續增長而趨於飽和,這可能導致叢集被鎖定為唯讀狀態,影響業務正常運行。為了協助您有效管理儲存資源並保障叢集的穩定性,本文將詳細介紹儲存空間的構成,並提供查看用量、清理各類檔案及回收空間的具體方法。
儲存空間構成
通過瞭解PolarDB MySQL版儲存空間的構成,您可以進行有效管理,從而準確地定位問題並採取恰當的最佳化措施。
資料檔案:儲存您的資料表和索引等業務資料。
記錄檔:主要包括Binlog日誌、Redo日誌和Undo日誌,在執行大事務或高並發的寫入操作時會使這些記錄檔快速增長。
說明PolarDB MySQL版叢集的Binlog日誌預設關閉,使用更高效的物理日誌(Redo Log)作為替代。若您的叢集未開啟Binlog,可無需關注。
臨時檔案:在執行排序(ORDER BY)、分組(GROUP BY)或關聯查詢等操作時,會產生暫存資料表檔案。此外,未提交的大事務也會產生臨時的Binlog快取檔案。
系統檔案:儲存資料庫運行所必需的核心組件,如資料字典、事務資訊、雙寫緩衝區等。這部分檔案是InnoDB引擎自我管理的基礎,對保障資料一致性和叢集恢複至關重要,您無法直接操作。
查看儲存空間使用方式
您可以通過以下兩種方式查看叢集的儲存空間使用方式:
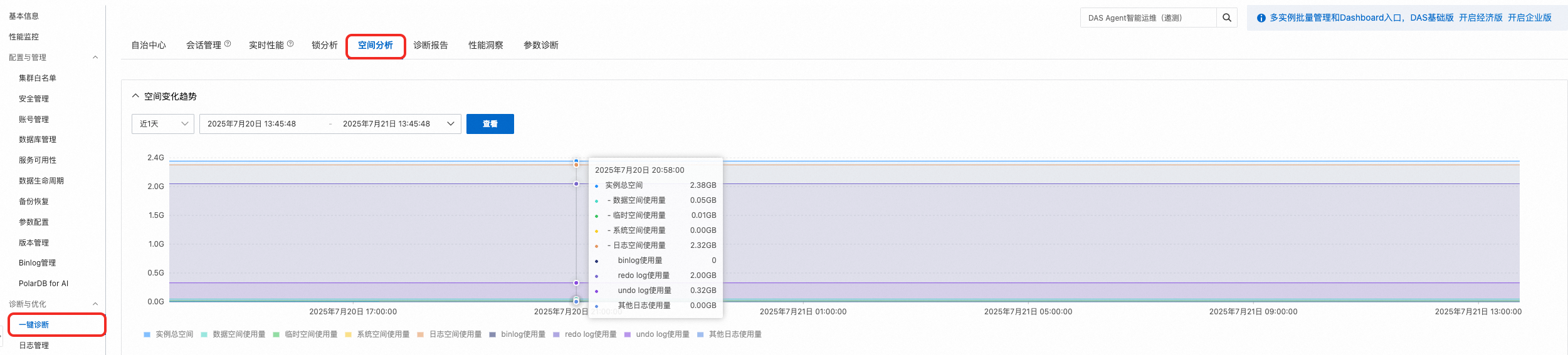
前往PolarDB控制台,在目的地組群的基本信息頁面的資料庫分布式儲存地區,查看當前叢集的儲存容量。

前往PolarDB控制台,在目的地組群的頁面的空间分析頁簽中,查看指定時間點的儲存空間使用方式。
清理資料檔案與回收資料表空間
PolarDB MySQL版可能因資料檔案長時間未進行整理而導致儲存空間佔用過多。此外,在使用DELETE命令刪除資料後,系統僅會將記錄的位置或資料頁標記為可複用,並不會直接縮小表檔案的大小,這將導致大量空間片段的產生,從而使儲存空間持續被佔用。
在進行清理資料檔案時,控制台介面更新有延遲,請您耐心等待。
清理檔案
對於不再需要的表,使用TRUNCATE TABLE或DROP TABLE命令可以迅速釋放其佔用的全部空間。
操作前請確保資料已備份,以免造成資料丟失。
回收資料表空間
對於存在大量片段且需要保留的表,可以在業務低峰期執行OPTIMIZE TABLE命令。該操作會重建表,消除片段並回收空閑空間。您也可以通過DMS工具執行此最佳化,DMS支援限流,對業務負載的影響更小,但執行速度相對較慢。
注意事項
當目標表的片段率較低時,執行
OPTIMIZE TABLE命令不能顯著降低資料表空間大小。您可以在information_schema.tables視圖中的DATA_FREE欄位來查看目標表的片段率。執行
OPTIMIZE TABLE命令時,表資料會複製到建立的暫存資料表中,這會臨時增加叢集的儲存空間使用率。對於不包含全文索引的表,
OPTIMIZE TABLE語句使用Online DDL方式執行,支援並發讀寫。對大表執行
OPTIMIZE TABLE操作會帶來突發的IO和Buffer使用量,可能會導致鎖表和搶佔資源,在業務高峰期執行該操作可能會導致叢集不可用以及監控斷點,建議在業務低峰期執行該操作。
方案對比
您可以根據實際業務情境選擇適合您的回收方式。
回收資料表空間的方式 | 是否允許並發讀寫 | 執行速度 | 是否支援限流 | 適用情境 |
| 是 | 快 | 否 | 在業務負載較輕、對執行效率要求較高的情況下, |
DMS回收資料表空間 | 是 | 慢 | 是 | 在對叢集負載敏感、對執行效率不敏感的情況下,DMS工具能夠以對業務影響較低的方式對錶空間進行回收,降低空間回收操作對叢集效能的影響。 |
操作流程
OPTIMIZE TABLE命令回收資料表空間
您可以通過以下命令來回收資料表空間
OPTIMIZE TABLE [Database1].[Table1],[Database2].[Table2][Database1]和[Database2]為資料庫名稱,[Table1]和[Table2]為表名。在InnoDB引擎中執行
OPTIMIZE TABLE命令時,會出現提示資訊Table does not support optimize, doing recreate + analyze instead,該資訊是正常返回的結果,您可以忽略該資訊,確認返回ok即可。關於更多OPTIMIZE TABLE語句的詳細資料,請參見OPTIMIZE TABLE Statement。
DMS回收資料表空間
登入資料庫:您可以前往PolarDB控制台,單擊目的地組群基本信息頁面右上方的登录数据库按鈕,在Data Management平台中登入PolarDB MySQL版叢集。
回收資料表空間:在左側選擇目的地組群ID,雙擊目標庫,按右鍵任意表名,然後選擇大量操作表。在大量操作表頁面,勾選需要釋放空間的表名,並單擊表維護>最佳化表。
清理記錄檔
PolarDB MySQL版叢集可能由於大事務的處理而快速產生Binlog日誌、Redo日誌或Undo日誌,從而導致儲存空間被大量佔用或佔滿的情況。在此情況下,建議您優先考慮擴充儲存空間容量,隨後再排查快速組建記錄檔檔案的原因。
在進行清理Binlog日誌、Undo日誌或Redo日誌時,控制台介面更新有延遲,請您耐心等待。
Binlog日誌
PolarDB MySQL版叢集的Binlog日誌預設關閉,使用更進階別的物理日誌(Redo Log)作為替代。若您的叢集未開啟Binlog日誌,請參考Redo日誌與Undo日誌的清理方案。
保留原則
Binlog檔案有如下兩種儲存策略:
開啟Binlog後,檔案預設儲存3天,超過3天的檔案會被自動刪除。
說明在2023年11月23日前購買的PolarDB MySQL版叢集,其Binlog檔案預設儲存兩周(14天)。
在2024年1月17日前購買的PolarDB MySQL版叢集,其Binlog檔案預設儲存一周(7天)。
關閉Binlog後,已有的Binlog記錄檔會一直保留,不會自動刪除。
說明若需要刪除Binlog檔案,您需要在開始Binlog的狀態下,將Binlog的儲存時間長度參數(
loose_expire_logs_hours或binlog_expire_logs_seconds)設定為一個較小的值,等檔案超過儲存時間長度自動刪除後再關閉Binlog。
修改儲存時間長度
修改Binlog檔案的儲存時間長度不會造成串連閃斷,也不需要重啟叢集。
如果修改儲存時間長度而導致大量Binlog檔案需要被清除(如10 TB),則在清除時可能會造成短時間的資料庫寫入異常。因此,在Binlog檔案較大的情況下,建議在業務低峰期進行操作,並分多次縮短Binlog的儲存時間長度,每次清除一部分Binlog資料。
已被清除的Binlog檔案被刪除後無法進行恢複。
您可以通過如下方式修改Binlog檔案儲存時間長度:
MySQL 5.6:您可以通過修改
loose_expire_logs_hours(取值範圍為0~2376,單位為小時,預設值為72)的參數值來設定Binlog的儲存時間長度。0表示不自動刪除Binlog檔案。MySQL 5.7或MySQL 8.0:您可以通過修改
binlog_expire_logs_seconds(取值範圍為0~4294967295,單位為秒,預設值為259200)的參數值來設定Binlog的儲存時間長度。0表示不自動刪除Binlog檔案。
清理歷史檔案
修改Binlog儲存時間長度參數(loose_expire_logs_hours或binlog_expire_logs_seconds)後,叢集中的歷史Binlog檔案不會立即自動清除。在此情況下,如需清除歷史檔案,您可以通過以下三種方法之一進行操作:
等待自動清除:當叢集中最後一個Binlog檔案達到最大儲存大小(參數
max_binlog_size)時,切換至新的Binlog檔案後,這些歷史Binlog檔案將會被自動清除。手動清除:使用高許可權帳號執行
flush binary logs命令可以立即觸發Binlog檔案切換並清除到期的Binlog檔案。重啟叢集:重啟叢集後,系統將自動清除歷史的Binlog檔案。
Undo日誌
PolarDB MySQL版叢集的Undo日誌承擔著多版本並發控制(MVCC)中歷史版本的作用。因此,當存在未提交的事務(無論在唯讀節點還是讀寫節點)持有舊的讀視圖(Read View)時,將會阻礙Undo日誌的清理過程,從而導致空間的持續積累。
識別並終止未提交的事務
登入資料庫:您可以前往PolarDB控制台,單擊目的地組群基本信息頁面右上方的登录数据库按鈕,在Data Management平台中登入PolarDB MySQL版叢集。
尋找未提交的事務:執行如下命令,檢查當前是否存在長時間未提交的事務。
SELECT * FROM INFORMATION_SCHEMA.innodb_trx;需重點關注
trx_started(事務開始時間)時間很早,或trx_state(事務狀態)長時間處於RUNNING狀態的事務,並記錄其trx_mysql_thread_id(線程ID)的值。終止事務:在確認不影響業務的前提下,執行KILL命令終止目標事務。
kill [線程ID];
查看後台清理進展
在清理完成事務所對應的線程後,您需要確認當前Undo history的推進情況。如果發現Undo history長度依然持續快速增長,則需要調優後台清理(Purge)的效能。
當寫入壓力大時,PolarDB的策略是優先保證當前的寫入效能。此時,可能會導致Undo日誌的清理滯後。
監控清理進度:執行以下命令,觀察
Undo history的長度。SELECT COUNT FROM INFORMATION_SCHEMA.innodb_metrics WHERE name = 'trx_rseg_history_len';如果該值大於100萬,或者幾分鐘的時間內,該值還在不斷地上升,並且當前壓力確實比較大,說明清理速度跟不上寫入速度。
調整清理參數:提升清理效率。
將參數
innodb_purge_batch_size的值調大,使每次清理的批次更大。將參數
innodb_purge_threads的值調大,增加清理線程數,建議跟叢集規格中的CPU核心數保持一致。說明該操作會重啟叢集,建議在業務低峰期操作。
回收佔用空間
當Undo history長度下降並穩定後,若您希望清理Undo日誌所佔用的空間,可以開啟Undo truncate功能。
Redo日誌
PolarDB MySQL版叢集使用Redo日誌替代Binlog日誌,以實現主節點與唯讀節點之間的資料同步。
在不考慮記錄備份的情況下,本地Redo日誌會佔用範圍為2 GB至11 GB的儲存空間,最高可達11 GB。其中包括緩衝池中的8個Redo日誌(佔用8 GB)、正在寫入的Redo日誌(佔用1 GB)、提前建立的Redo日誌(佔用1 GB)以及最後一個Redo日誌(佔用1 GB)。
在考慮記錄備份的情況下,本地Redo日誌會在備份完成後保留約一個小時。如果寫入速度較快(例如超過35 MB/s),則可能導致本地Redo日誌的暫時性堆積。
清理規則
Redo日誌不支援手動清理,通常在記錄備份完成後會自動進行清理,無需手動幹預。
您可以在PolarDB控制台調整叢集的記錄備份策略(預設為7天)。
清理臨時檔案
PolarDB MySQL版叢集可能因複雜查詢或大事務而產生大量的臨時檔案,從而導致儲存空間被大量佔用或佔滿的情況。此時,可能會出現錯誤提示,例如:error: 1114 The table '/home/mysql/log/tmp/#sqlxxx_xxx_xxx' is full。
您可以通過以下兩種方式來進行處理:
終止會話
終止包含大量的Copy to tmp table或Sending data等資訊的會話。
登入資料庫:您可以前往PolarDB控制台,單擊目的地組群基本信息頁面右上方的登录数据库按鈕,在Data Management平台中登入PolarDB MySQL版叢集。
查看會話情況:執行如下命令查看資料庫內的會話情況。
SHOW PROCESSLIST;找到目標會話:在DMS中,您可以單擊查詢結果的
State列,對該列的資料進行排序,查看是否有大量的Copy to tmp table或Sending data等資訊,並記錄該會話的ID值。終止會話:執行如下命令以終止目標會話。
kill [會話ID];重要執行終止會話操作前,請確保該會話不會影響正常啟動並執行業務。
若通過以上步驟仍然不能釋放儲存空間,您可以重啟叢集中的各個節點,來釋放臨時檔案佔用的儲存空間。
調整參數
前往PolarDB控制台,在目的地組群的頁面中,修改參數tmp_table_size和max_heap_table_size,以增加暫存資料表空間大小。