CNP(Cloud Native Application Performance Optimizer),一站式雲原生應用效能評測、分析和最佳化的平台型產品,致力於提升雲上應用效能,自動化高效評測靈駿叢集訓練效能,提供效能最佳化建議。本文為您介紹如何使用CNP進行效能評測。
CNP平台入口
登入靈駿控制台。
在左側導覽列,點擊效能評測 > CNP效能評測平台。
您可以在CNP平台中發起效能評測、查看評測結果。
在頁面左下角,點擊返回可以快速回到靈駿控制台。
發起評測
第一步:選擇叢集
在歡迎頁面單擊開始評測或在效能評測頁單擊發起評測,進入評測流程第一步:選擇叢集。
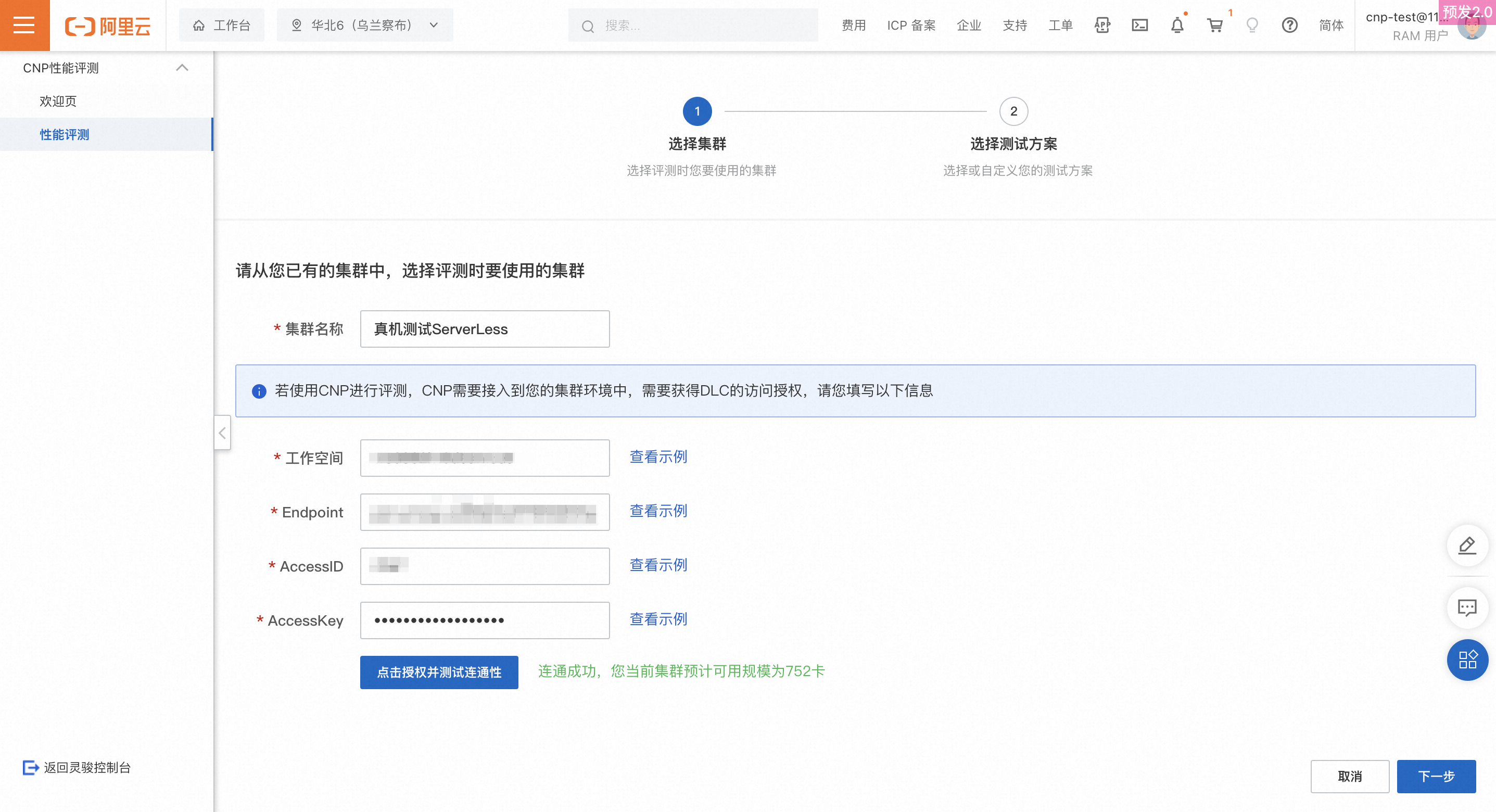
叢集名稱:從您當前所擁有的叢集中,選擇執行評測時要使用的一個叢集。
授權DLC訪問資訊:填寫完成後,單擊下方測試連通性,如果成功訪問則會返回連通成功,否則會給出失敗原因,常見的失敗原因如下所示:
失敗原因枚舉
建議操作
連線逾時
開通訪問CNP的白名單後再次嘗試
資訊填寫有誤
AccessID、Accesskey、工作空間、Endpoint至少有一個資訊填寫錯誤,檢查資訊後再次嘗試
擷取STS token失敗(D3001)
建立SLR失敗(D3002)
建立Arms執行個體失敗(D3003)
檢查Arms服務失敗(D3004)
開通ARMS服務
擷取Arms資訊失敗(D3005)
無許可權建立SLR(D3006)
授權SLR
連通性測試通過後,點擊下一步,進入第二步:選擇測試方案。
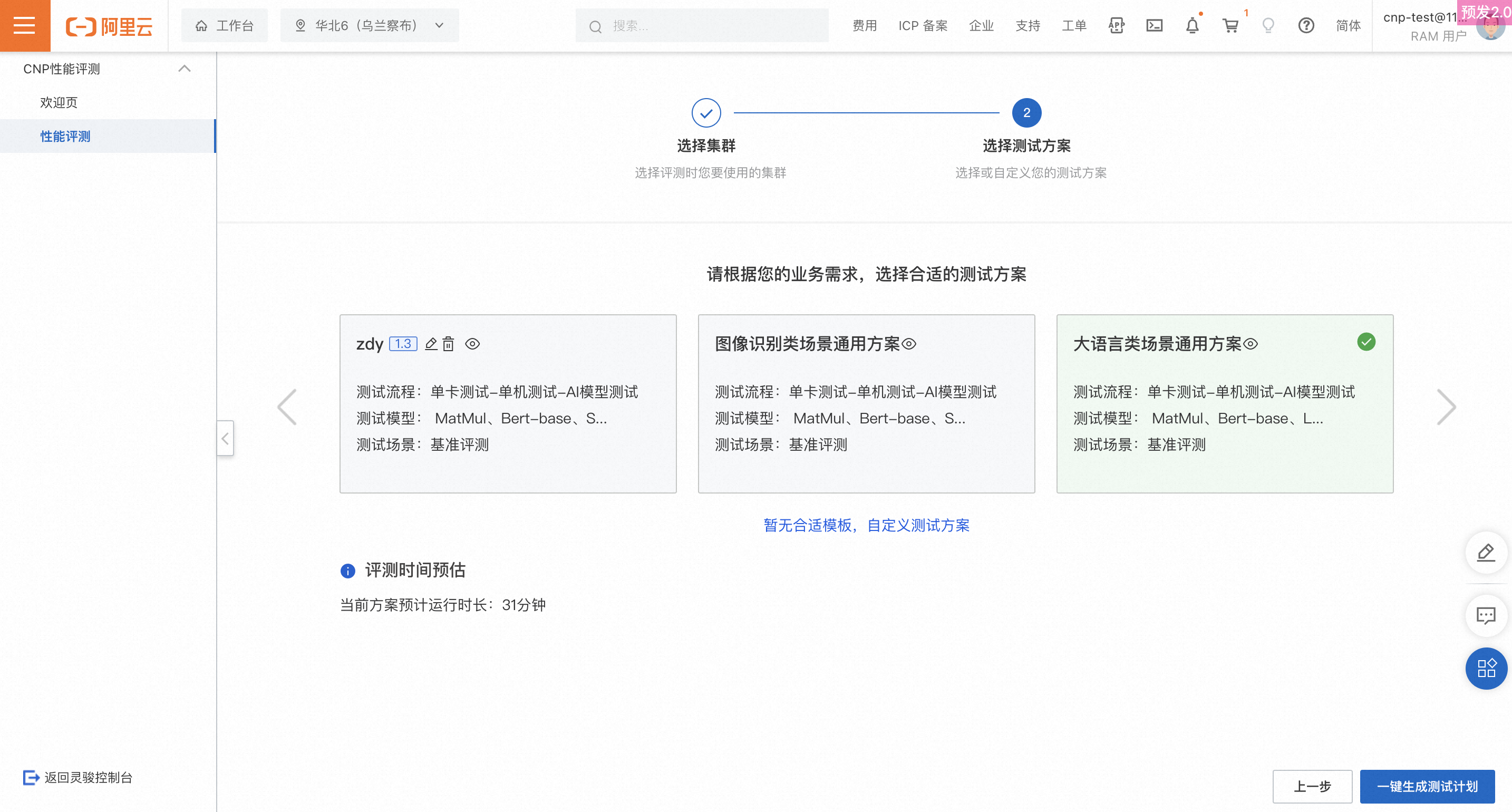
第二步:選擇測試方案
使用模板
系統預設提供兩套測試方案模板,您可根據實際業務情境選擇其中之一。
方案 | 包含的測試內容 | 測試的叢集規模 |
方案A:大語言類情境通用方案 |
|
|
方案B:Image Recognition類情境通用方案 |
|
|
自訂方案
若系統提供的模板均無法滿足測試需求,則可以選擇自訂測試方案。
單卡測試:節點數支援自訂,測試案例預設MatMul。
單機測試:節點數支援自訂,測試案例預設Bert-base。
AI模型測試:AI模型以及評測的叢集卡數支援自訂選擇。
當前已支援的模型包括:LLaMA-7B、Stable-Diffusion、Swin-Transformer、Bert-base、UNet。
預設參數配置均採用基準配置,具體配置可在頁面中查看。
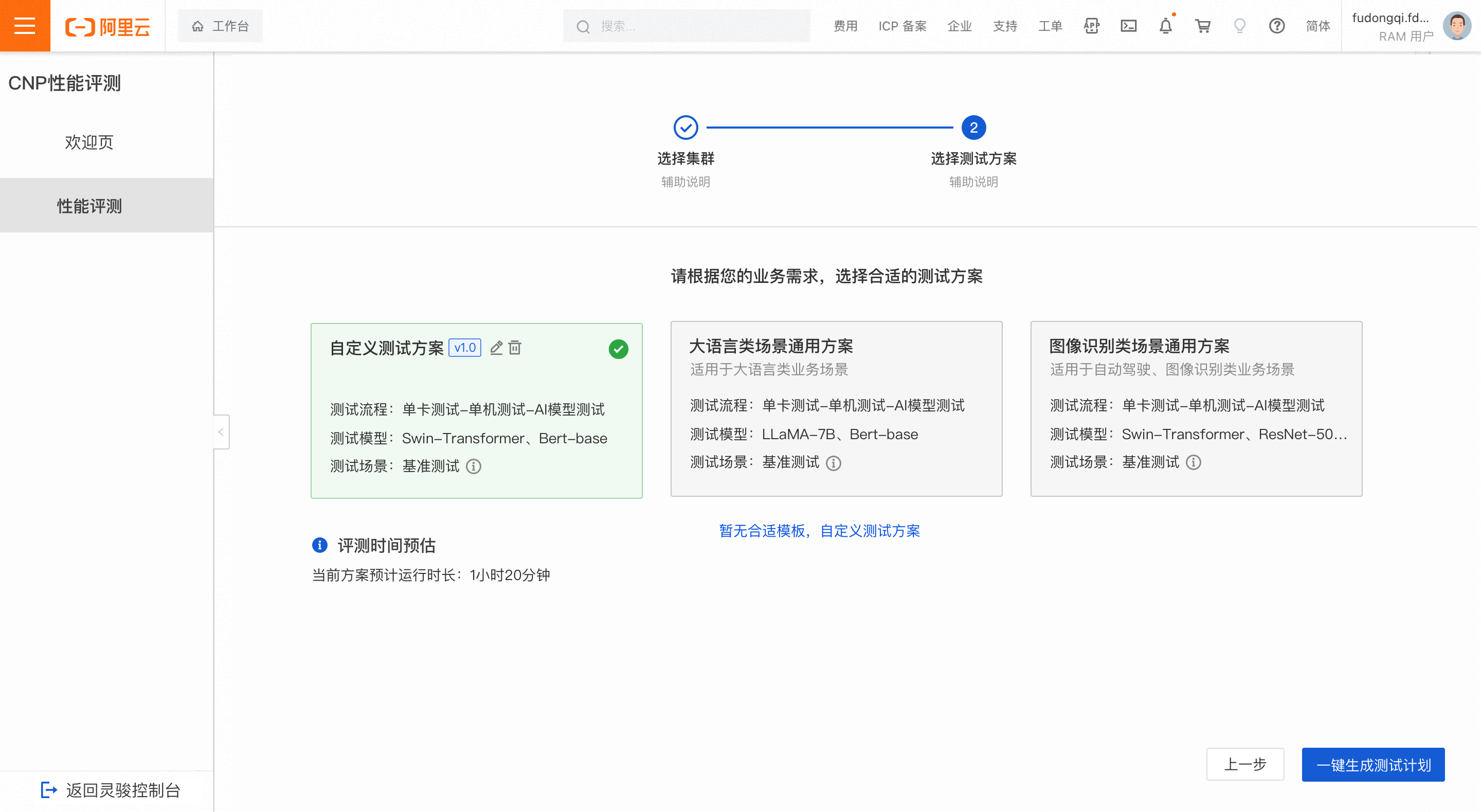
評測時間預估
選擇測試方案後,會根據方案中包含的測試內容,自動估算評測預計花費的時間。注意,此時間是根據您第一步所選叢集的最大規模進行的估算結果,若您可用叢集未達到最大規模,則實際評測時間將比預估時間耗時更長。
一鍵開始評測
完成第一步和第二步後,點擊一鍵開始評測,即可發起評測,等待評測結果。
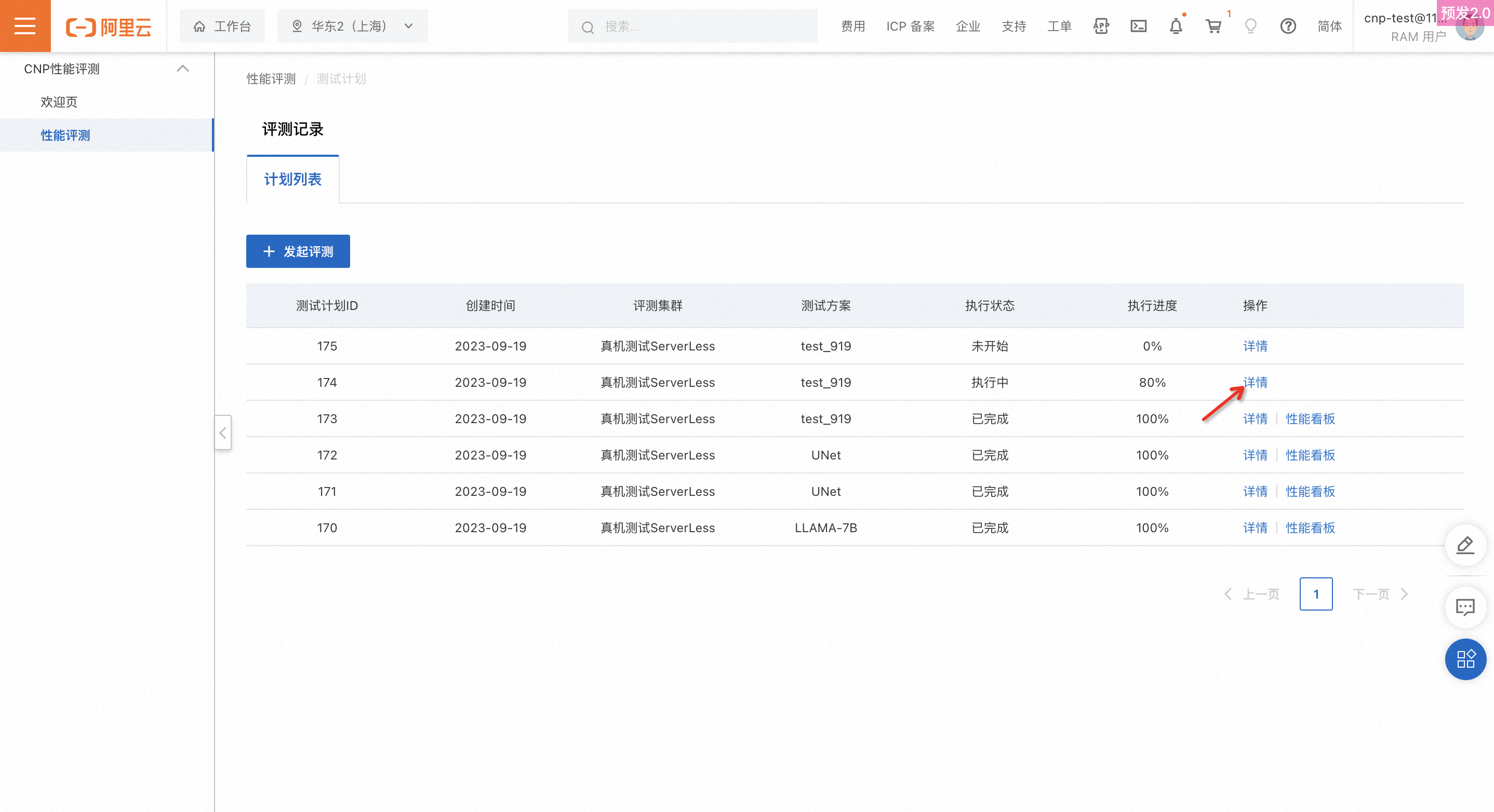
查看評測進度及結果
建立完成測試計劃後,在評測計劃列表頁可即時查看執行狀態和執行進度。點擊詳情,可進入評測計劃詳情,進一步查看每個環節的評測進度。
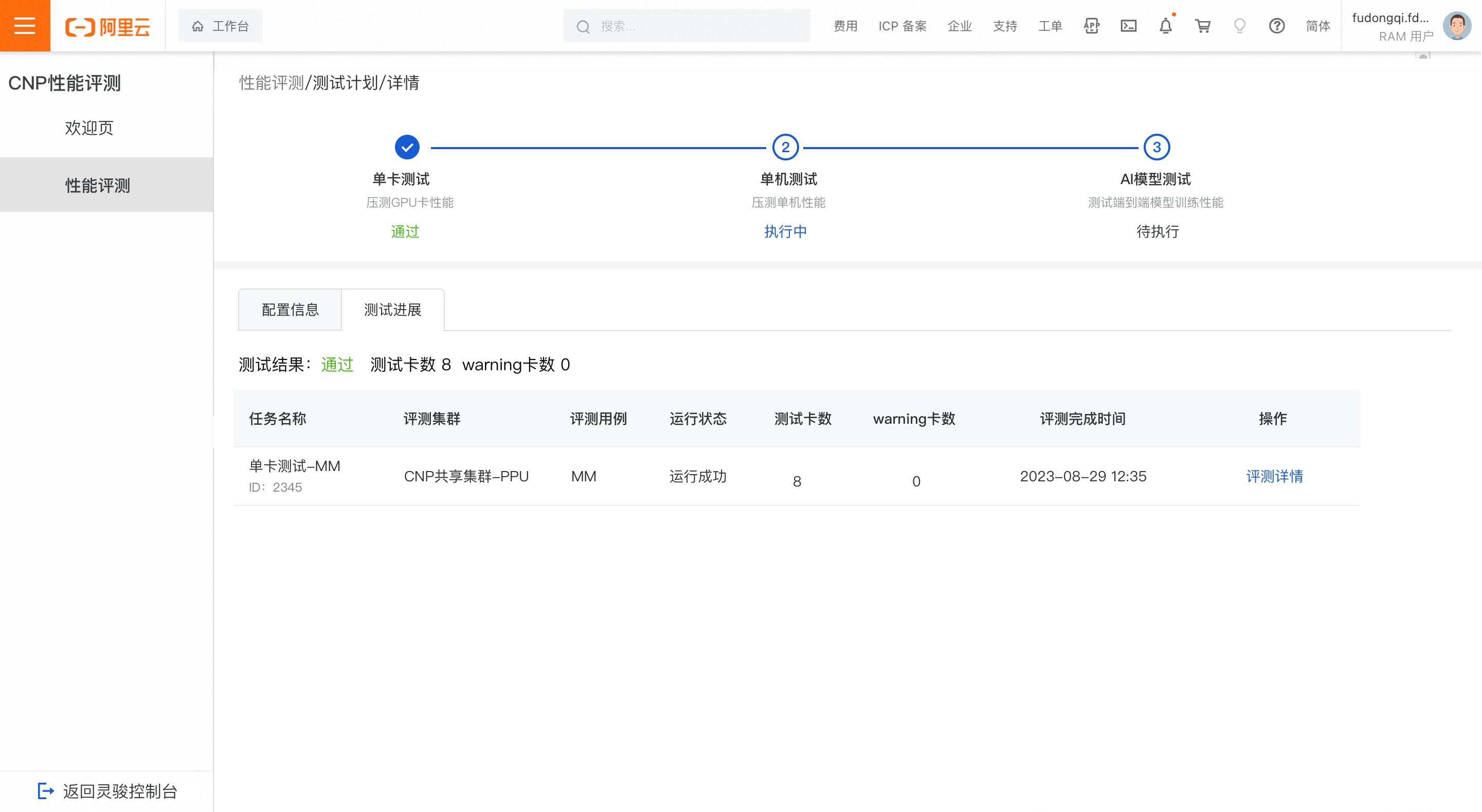
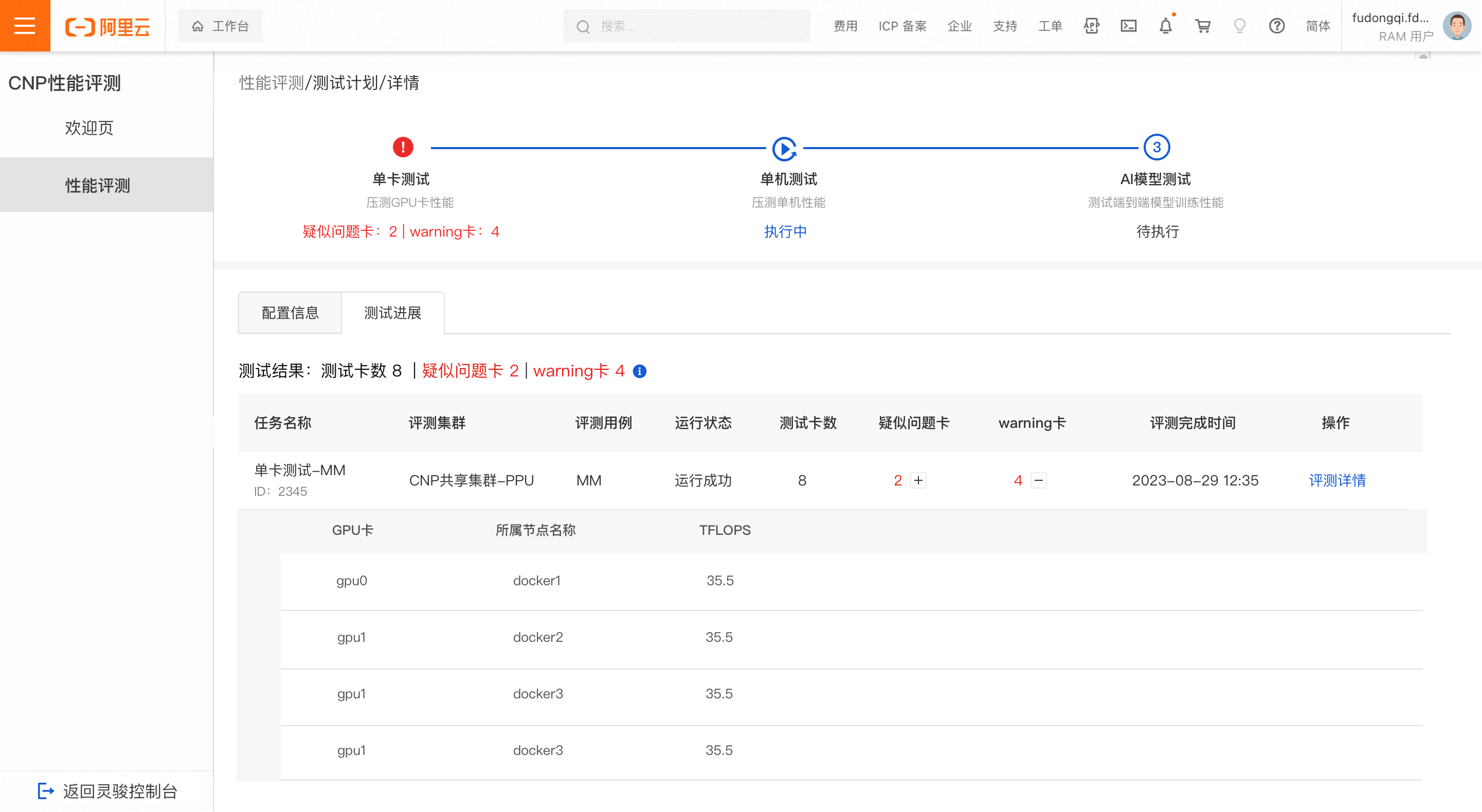
單卡測試
測試通過
當測試的卡未出現疑似問題卡且未出現warning卡時,判定為單卡測試結果通過。
說明疑似問題卡:表示該卡的任務運行失敗,卡疑似有問題;
warning卡:表示該卡的TFLOPS變化有超過5%的迭代數在正常閾值範圍之外
正常閾值的計算邏輯:取每個迭代所有卡的TFLOPS中位元作為基準,將基準上下3%與4*sigma(4*標準差) 進行比較,取值較大者作為正常閾值範圍。
測試結果異常
當測試的卡出現疑似問題卡或出現warning卡時,判定為單卡測試結果異常。
在評測工作清單中,點擊加號表徵圖可以展開疑似問題卡或warning卡查看明細,您可將異常節點上報給營運團隊進一步排查。點擊評測詳情,可查看此任務的詳細評測結果。
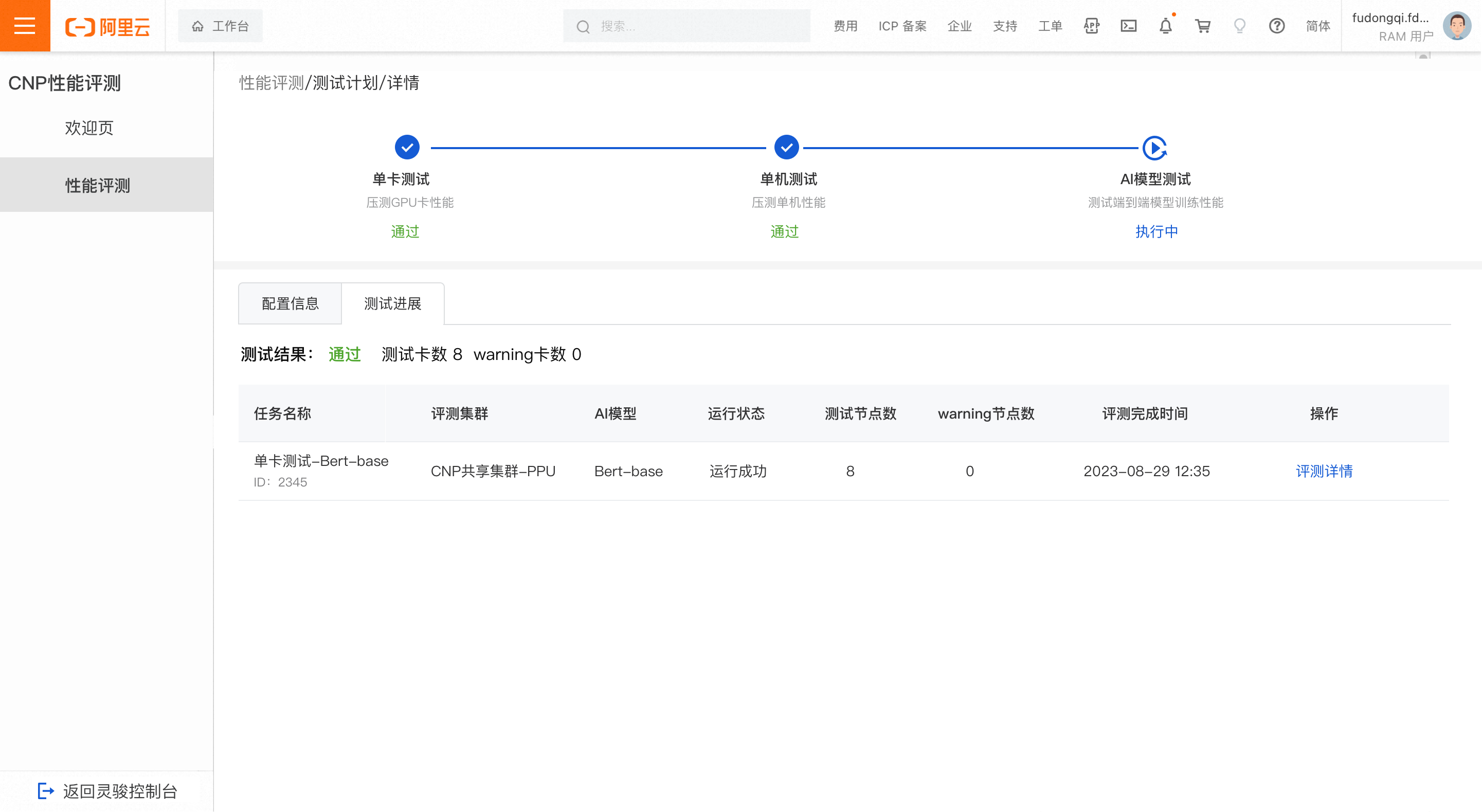
單機測試進度
測試通過
當測試的節點未出現疑似問題節點且未出現warning節點時,判定為單機測試結果通過。
說明疑似問題節點:表示該節點下的DLC任務運行失敗,節點疑似有問題;
warning卡:表示該節點的輸送量變化有超過5%的迭代數在正常閾值範圍之外
正常閾值的計算邏輯:取每個迭代所有節點的吞吐中位元作為基準,將基準上下3%與4*sigma(4*標準差) 進行比較,取值較大者作為正常閾值範圍。
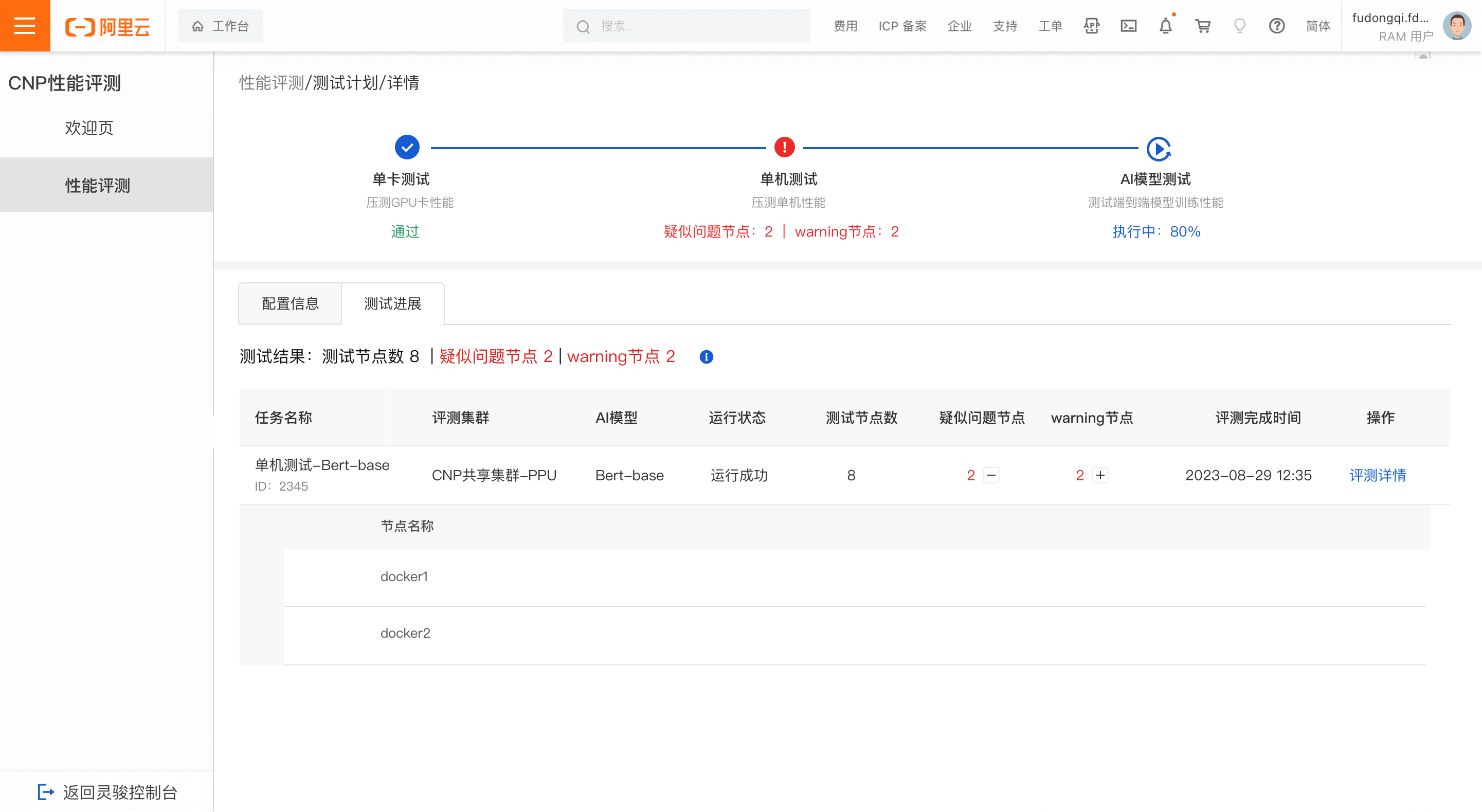
測試結果異常
當測試的節點出現疑似問題節點或出現warning節點時,判定為單機測試結果異常。
在評測工作清單中,點擊加號表徵圖可以展開疑似問題節點或warning節點查看明細,將異常節點上報給營運團隊進一步排查。點擊評測詳情,可查看此任務的詳細評測結果。
AI模型測試
測試進度
待執行:若所有任務都為待執行狀態
已完成:若所有任務均運行成功或運行失敗或已停止
已停止:若所有任務均為已停止狀態
執行中:部分任務已完成、部分任務待執行或執行中
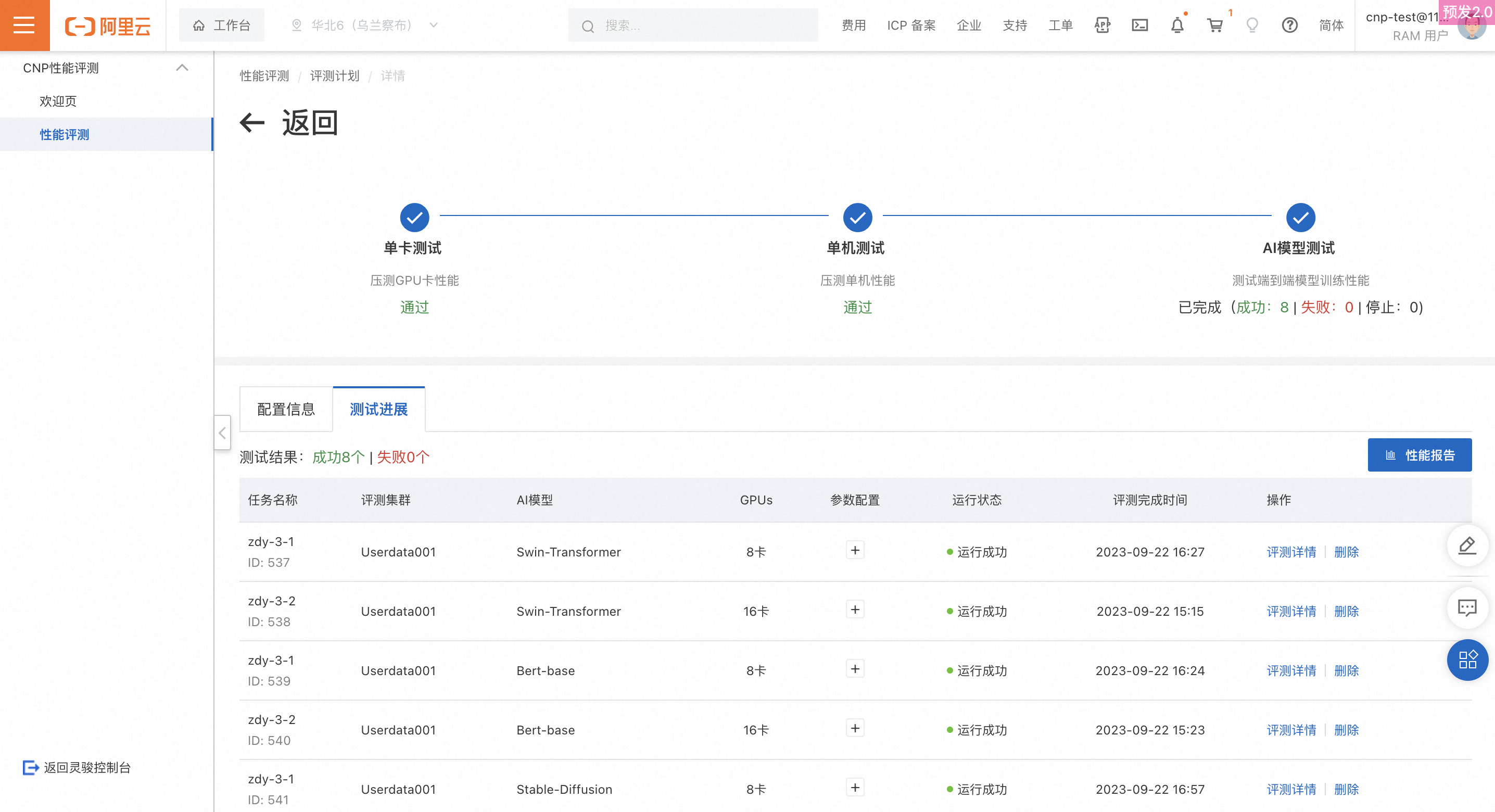
測試工作列表
可查看當前測試計劃在AI模型步驟中包含的所有任務,運行中的任務若想終止可以點擊停止操作,所有任務均可刪除。
警告已刪除和運行失敗的任務資料不會統計在效能看板dashboard中,請謹慎操作。
查看測試結果效能看板
操作入口
執行狀態為已完成的測試計劃,可以查看效能看板,效能看板中包含的資料為當前測試計劃中-AI模型測試環節運行成功的評測任務。
看板內容
Scalability of Test Model
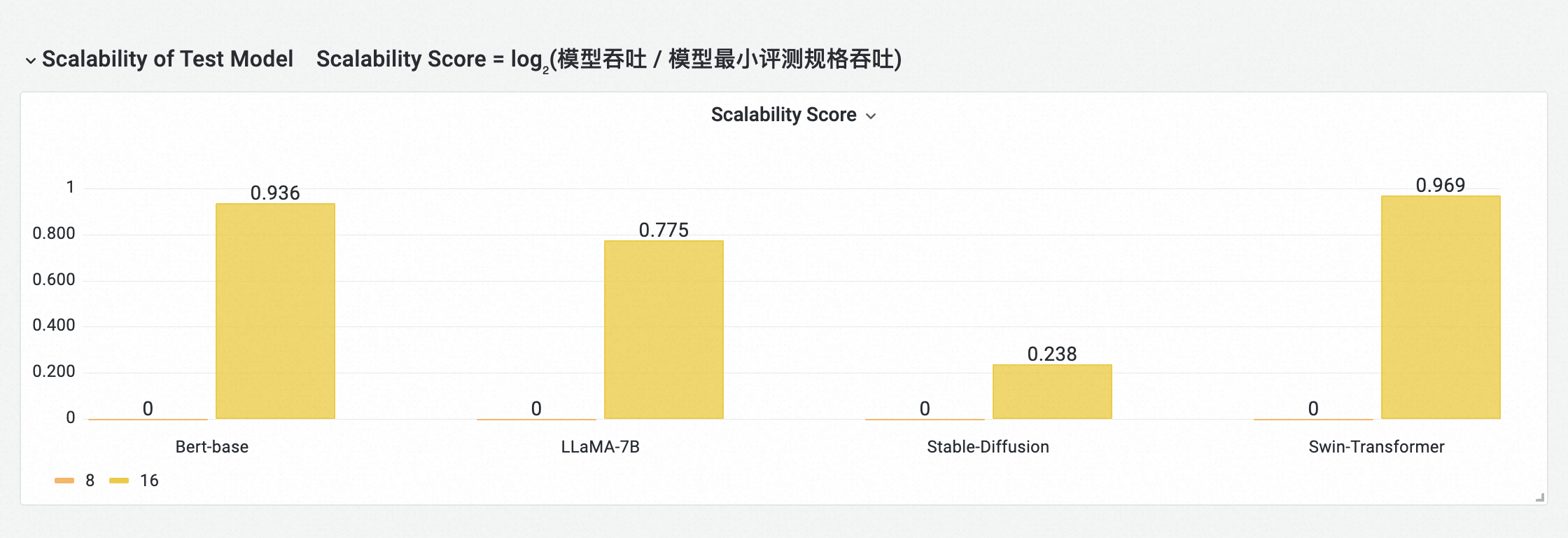
按模型顯示每個模型在當前測試計劃中所評測的卡數下,輸送量隨卡數的變化趨勢,體現模型在叢集上的效能擴充性(不同模型間結果不進行對比)。
計算公式:Scalability Score = log₂(模型吞吐 / 模型最小評測規格吞吐)
樣本:以GPT3-175B模型為例(MOCK資料、僅用作說明)
GPUs | 輸送量 | Scalability Score | 理論Scalability Score |
64 | 10 | ||
128 | 18 | log₂(18 / 10) | log₂ 2 |
256 | 35 | log₂(35 / 10) | log₂ 4 |
512 | 69 | log₂(69 / 10) | log₂ 8 |
1024 | 137 | log₂(137 / 10) | log₂ 16 |
註:Scalability Score越接近理論Scalability Score值,效能拓展性越好
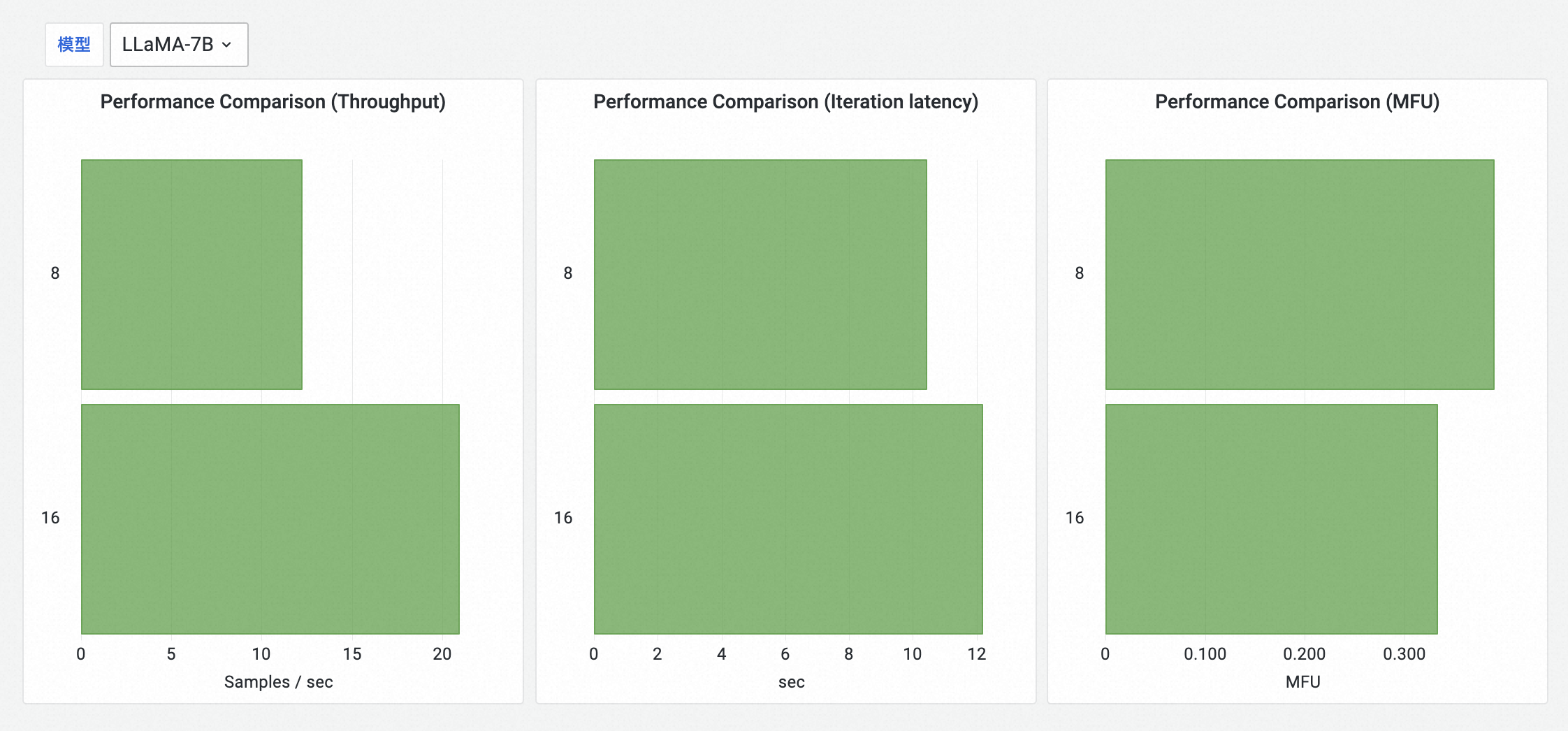
評測結果明細
按模型顯示每個模型在當前測試計劃中所評測的卡數下,throughput指標(輸送量)、MFU指標和iteration latency指標。縱座標表示卡數,橫座標表示指標值。