模型簡介
阿里雲於3月6日開源推出的千問QwQ-32B推理模型,基於大規模強化學習實現了數學、代碼與通用能力的突破性提升。整體效能比肩DeepSeek-R1,同時顯著降低了部署使用成本。
在測數學能力的AIME24評測集上和評估代碼能力的LiveCodeBench中,千問QwQ-32B表現與DeepSeek-R1相當,遠勝於o1-mini及相同尺寸的R1蒸餾模型。
在由Meta首席科學家楊立昆領銜的“最難LLMs評測榜”LiveBench、Google等提出的指令遵循能力IFEval評測集、由加州大學伯克利分校等提出的評估準確調用函數或工具方面的BFCL測試中,千問QwQ-32B的得分均超越了DeepSeek-R1。
千問QwQ-32B創新整合了智能體Agent相關能力,使其能夠在使用工具的同時進行批判性思考,並根據環境反饋調整推理過程。
當前PAI-Model Gallery已全面支援 QwQ-32B 模型的一鍵部署、微調、評測能力(部署需要96G顯存GPU)。同時也支援量化版本模型 QwQ-32B-GGUF、QwQ-32B-AWQ(使用單卡A10等更低成本GPU即可部署服務)。
模型部署
進入Model Gallery頁面。
登入PAI控制台,在頂部左上方根據實際情況選擇地區(可以切換地區來擷取合適的計算資產庫存)。
在左側導覽列選擇工作空間列表,單擊指定工作空間名稱,進入對應工作空間。
在左側導覽列選擇快速開始 > Model Gallery。
在 Model Gallery 頁面的模型列表中,找到QwQ-32B模型卡片,單擊進入模型詳情頁面。
單擊右上方部署,選擇部署架構、配置推理服務名稱以及部署使用的資源資訊後,即可一鍵部署服務,將模型部署到 PAI-EAS 推理服務平台。當前平台已支援多種部署架構,包括SGLang加速部署、vLLM加速部署、BladeLLM加速部署(阿里雲PAI自研高效能推理架構)。

使用推理服務。部署成功後,在服務頁面點擊“查看調用資訊”擷取調用的Endpoint和Token,想瞭解服務調用方式可以點擊預訓練模型連結,返回模型介紹頁查看調用方式說明。

您也可以在 PAI-EAS 推理服務平台上線上調試已部署好的QwQ-32B模型服務。

模型微調
PAI-Model Gallery為 QwQ-32B 模型配置了 SFT(監督微調)演算法,支援LoRA微調、全參微調2種方式,使用者可以以開箱即用的方式對模型進行微調。
準備訓練資料。SFT 訓練演算法支援使用 JSONL 等格式的訓練資料集(更多格式要求可以參考模型文檔中描述)。JSONL格式訓練資料樣本如下:
{"messages": [{"role": "system", "content": "你是個有用無害的助理"}, {"role": "user", "content": "你是?"}, {"role": "assistant", "content": "我是小派,由PAI訓練的人工智慧助手。我的目標是為使用者提供有用、準確和及時的資訊,並通過各種方式協助使用者進行有效溝通。請告訴我有什麼可以協助您的呢?"}]} {"messages": [{"role": "system", "content": "你是個有用無害的助理"}, {"role": "user", "content": "你是誰!"}, {"role": "assistant", "content": "您好!我是PAI開發的人工智慧語言模型,名為小派。我可以回答您的問題、提供資訊、進行對話並協助解決問題。如果您有任何疑問或需要協助,請隨時告訴我!"}]}配置訓練參數。當完成資料的準備,使用者可以將資料上傳到Object Storage Service Bucket 中。由於32B模型較大,演算法需要使用至少96GB顯存的 GPU 資源,請確保選擇使用的資源配額內有充足的計算資源。
訓練演算法支援的超參資訊如下,使用者可以根據使用的資料,計算資源等調整超參,或是使用演算法預設配置的超參。
參數名
參數描述
更多說明
learning_rate
學習率,用於控制模型權重的調整幅度。
過大的學習率可能導致訓練過程不穩定,損失值劇烈波動,無法收斂到一個較小的值。過小的學習率會使損失值下降緩慢,需要很長時間才能收斂。合適的學習率可以使模型快速且穩定地收斂到一個較優的解。
num_train_epochs
訓練資料集被重複使用的次數。
epoch過小可能導致欠擬合,epoch過大可能導致過擬合。若樣本量少,可增加epoch數以避免欠擬合; 較小的learning rate通常需要更多的epochs。
per_device_train_batch_size
每個 GPU 卡在一次訓練迭代中處理的樣本數量。
較大的批次大小可以提高訓練速度,也會增加顯存的需求。理想的batch size 通常是硬體顯存不溢出的最大值。可以在訓練詳情頁的任務監控頁面查看 GPU Memory 的使用方式。
gradient_accumulation_steps
梯度累積步驟數。
較小的 batch size 會增加梯度估計的方差,影響收斂速度。引入梯度累積(gradient accumulation)會在積累 gradient_accumulation_steps 個 batch 的梯度後再進行模型最佳化。請保證 gradient_accumulation_steps 為 GPU 卡數的倍數。
max_length
模型在一次訓練中處理的輸入資料的最大token長度。
訓練資料經過分詞器(tokenizer)處理後,會得到一個token序列,可以使用 token 估算工具來估算訓練資料中文本的長度。
lora_rank
LoRA維度。
lora_alpha
LoRA權重。
LoRA縮放係數,一般情況下取值為lora_rank * 2。
lora_dropout
LoRA訓練的丟棄率。通過在訓練過程中隨機丟棄神經元,來防止神經網路過擬合。
lorap_lr_ratio
LoRA+ 學習率比例(λ = ηB/ηA)。ηA, ηB分別是adapter matrices A與B的學習率。
相比於 LoRA,LoRA+可以為過程中的關鍵區段使用不同的學習率來實現更好的效能和更快的微調,而無需增加計算需求。當lorap_lr_ratio設為0時,表示使用普通的LoRA而非LoRA+。
advanced_settings
除了上述參數之外,我們還支援自訂一些其他參數,如果需要可以在此欄位中用 "--key1 value1 --key2 value2" 的方式進行配置;如果不需要,請保持該項空白。
save_strategy: 模型儲存策略,可選值為:"steps"、"epoch"、"no"。預設值為 "steps"。
save_steps: 模型儲存間隔。預設值為 500。
save_total_limit: 最多儲存的checkpoint數,會將到期的checkpoint進行刪除,預設為2。若為 None,儲存所有checkpoint。
warmup_ratio: 用於控制學習率預熱階段的超參數。預熱階段是指在訓練開始時,學習率從一個較小的值逐漸增加到設定的初始學習率的過程。warmup ratio 決定了這個預熱階段在整個訓練過程中的比例。預設為0。
單擊“訓練”按鈕,開始進行訓練,使用者可以查看訓練任務狀態和訓練日誌。訓練完成的模型同樣可以部署成線上服務。
模型評測
PAI-Model Gallery內建了常見評測演算法,支援使用者以開箱即用的方式對預訓練模型以及微調後的模型進行評測。通過評測能協助使用者評估模型效能,同時支援多模型的評測對比,指導使用者精準地選擇合適的模型。
模型評測入口:
直接對預訓練模型進行評測 |
|
在訓練任務詳情頁對微調後的模型進行評測 |
|


模型評測支援自訂資料集評測和公開資料集評測:


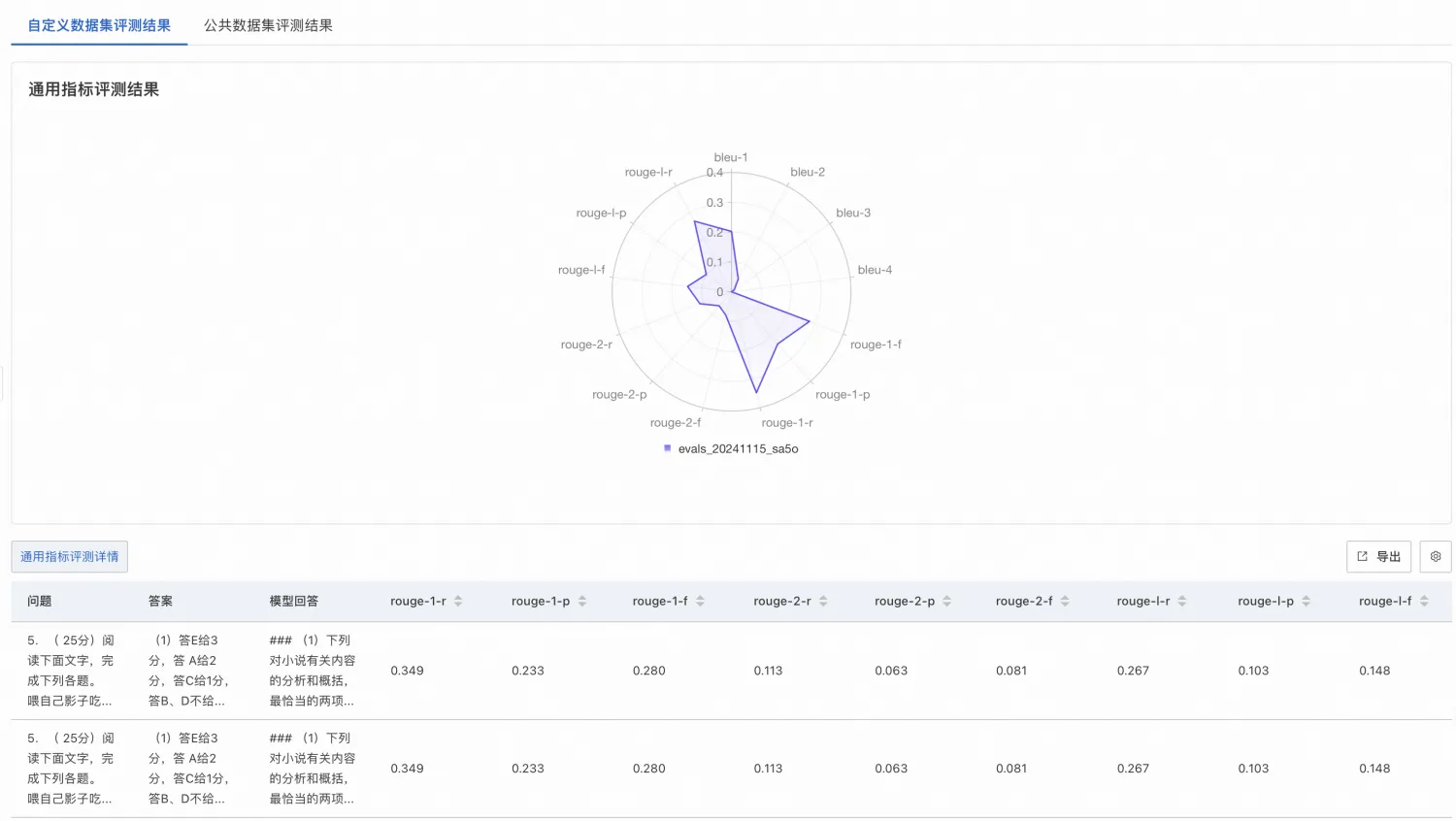
自訂資料集評測
模型評測支援NLP任務常用的文本匹配指標BLEU/ROUGE,以及球證模型評測(僅專家模式支援,用球證LLM來評測LLM)並給出打分及原因。使用者可以基於自己情境的獨特資料,評測所選模型是否適合自己的情境。
評測需要提供JSONL格式的評測集檔案,每行資料是一個JSON,使用question標識問題列,answer標識答案列。樣本檔案:evaluation_test.jsonl。
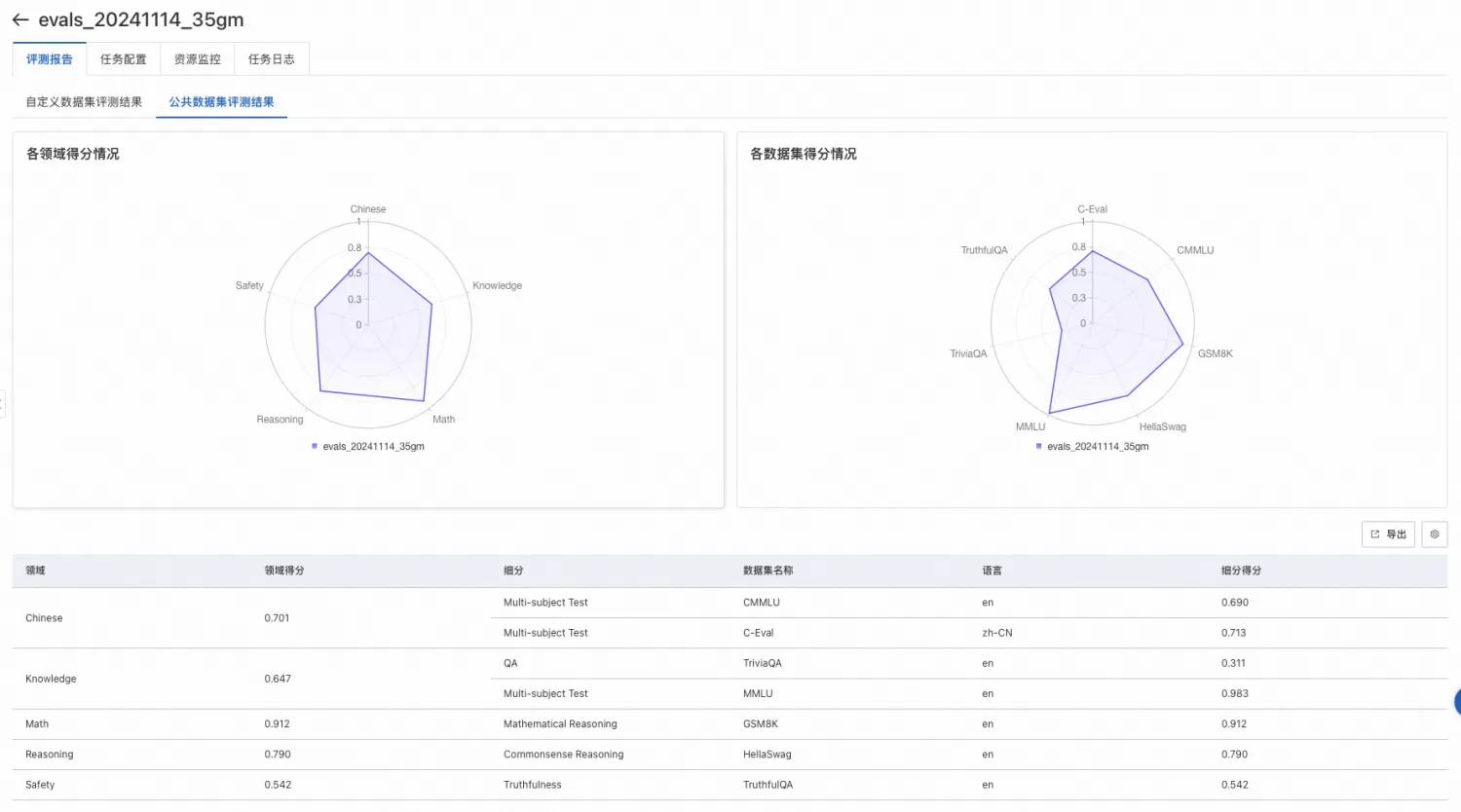
公開資料集評測
通過對開源的評測資料集按領域分類,對大模型進行綜合能力評估。目前PAI維護了CMMLU、GSM8K、TriviaQA、MMLU、C-Eval、TruthfulQA、HellaSwag等資料集,涵蓋數學、知識、推理等多個領域,其他公開資料集陸續接入中。(注意:GSM8K、TriviaQA、HellaSwag資料集評測會耗時較長,請按需選擇)
之後選擇評測結果輸出路徑,並根據系統推薦選擇相應計算資源,最後提交評測任務。等待任務完成,在任務頁面查看評測結果。如果選擇的資料集較多,由於模型會逐個資料集跑結果,所以等待時間可能較長,可以通過查看日誌的方式看到任務運行到了哪一步。

查看評測報告:自訂資料集和公開資料集評測結果樣本如下
聯絡我們
歡迎各位小夥伴持續關注使用 PAI-Model Gallery,平台會不斷上線 SOTA 模型,如果您有任何模型需求,也可以聯絡我們。您可通過搜尋DingTalk群號79680024618,加入PAI-Model Gallery使用者交流群。