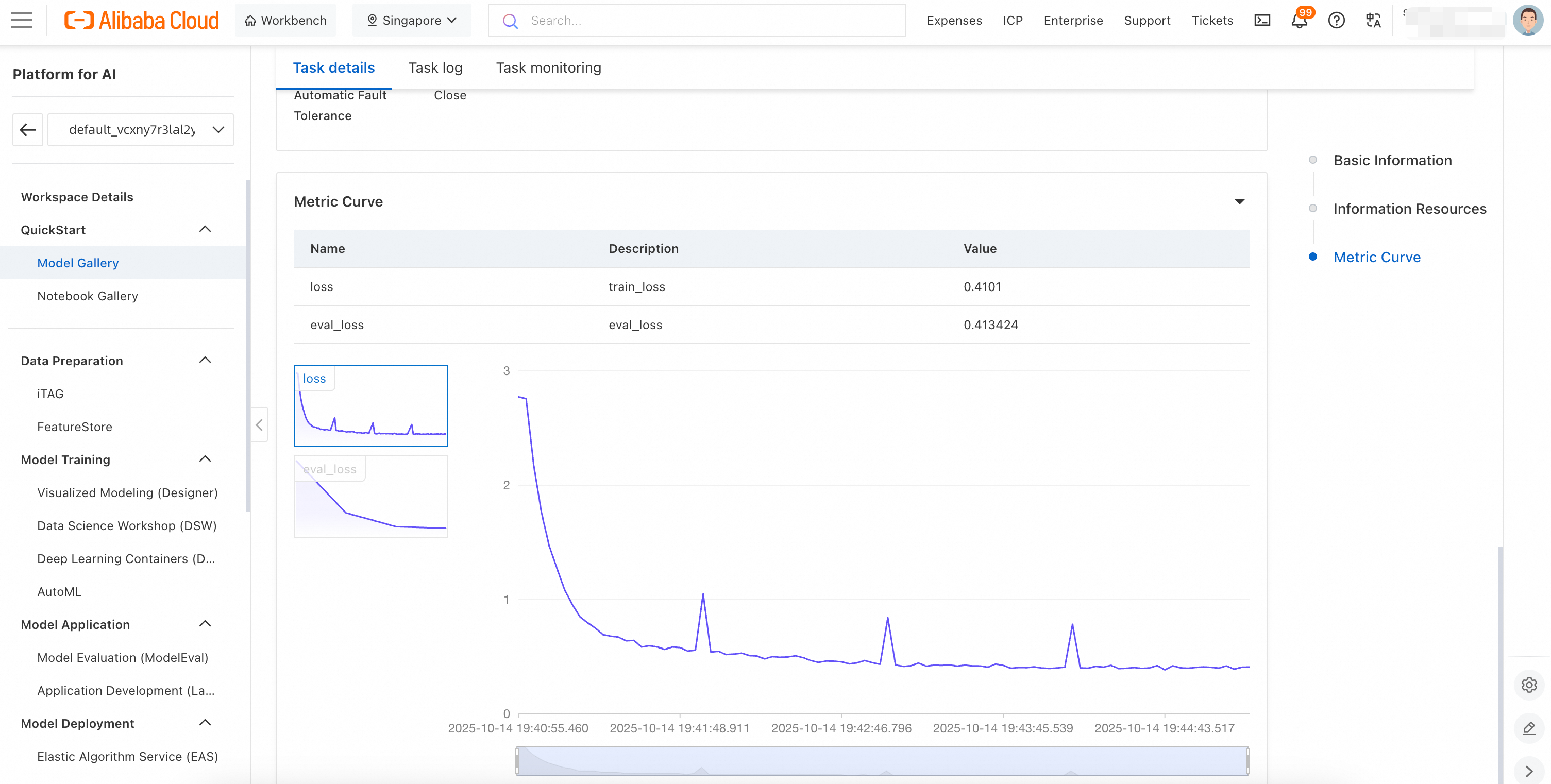
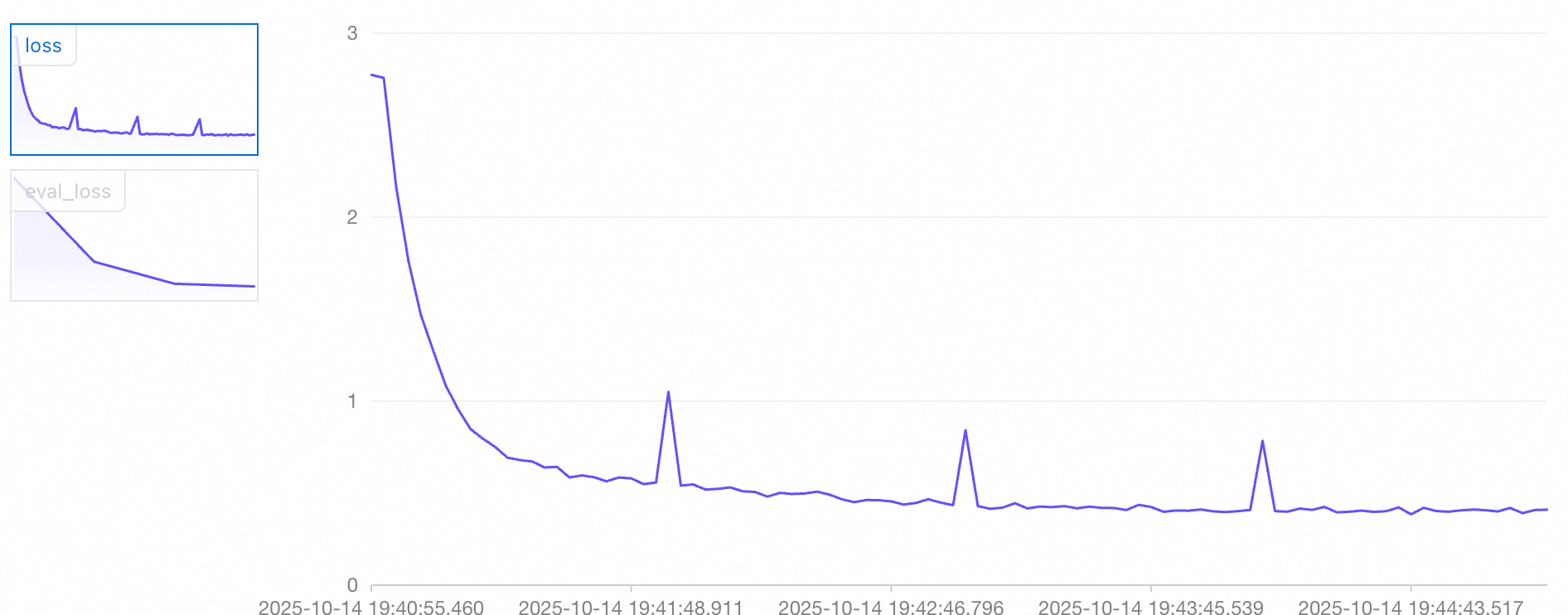
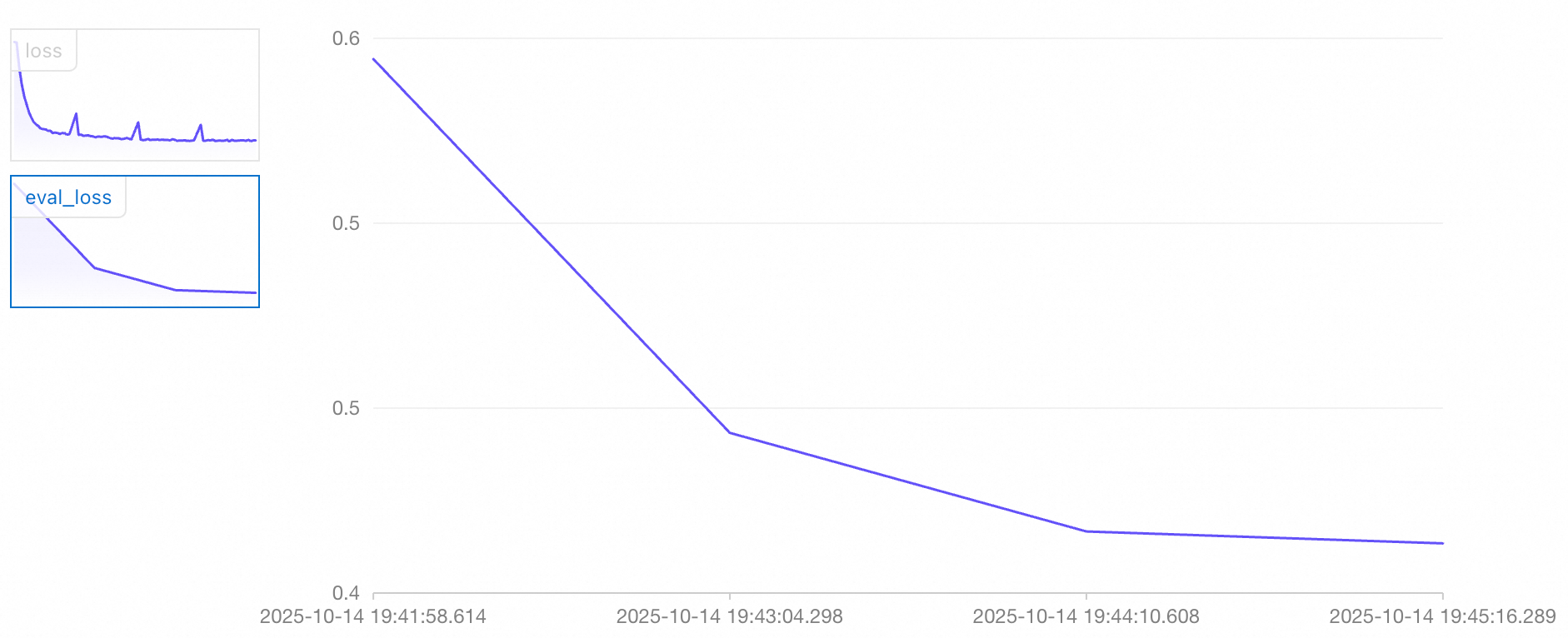
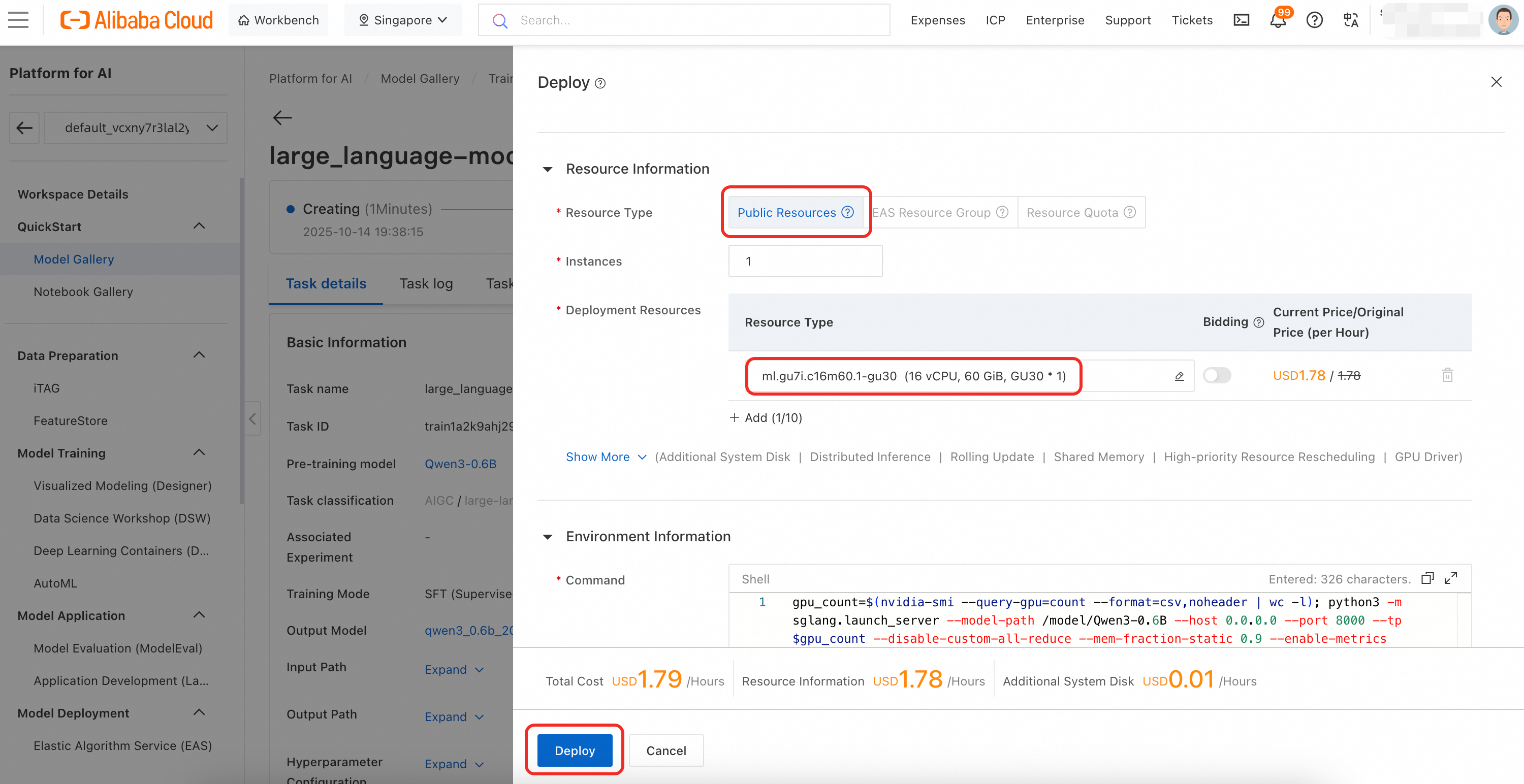
本範例程式碼將調用阿里雲百鍊中的大模型服務,您需要擷取百鍊API Key。代碼中使用 qwen-plus-latest 產生業務資料,使用qwen3-235b-a22b 模型進行打標。
# -*- coding: utf-8 -*-
import os
import asyncio
import random
import json
import sys
from typing import List
import platform
from openai import AsyncOpenAI
# Create an asynchronous client instance
# NOTE: This script uses the DashScope-compatible API endpoint.
# If you are using a different OpenAI-compatible service, change the base_url.
client = AsyncOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# List of US States and Territories
us_states = [
"Alabama", "Alaska", "Arizona", "Arkansas", "California", "Colorado", "Connecticut", "Delaware",
"Florida", "Georgia", "Hawaii", "Idaho", "Illinois", "Indiana", "Iowa", "Kansas", "Kentucky",
"Louisiana", "Maine", "Maryland", "Massachusetts", "Michigan", "Minnesota", "Mississippi",
"Missouri", "Montana", "Nebraska", "Nevada", "New Hampshire", "New Jersey", "New Mexico",
"New York", "North Carolina", "North Dakota", "Ohio", "Oklahoma", "Oregon", "Pennsylvania",
"Rhode Island", "South Carolina", "South Dakota", "Tennessee", "Texas", "Utah", "Vermont",
"Virginia", "Washington", "West Virginia", "Wisconsin", "Wyoming", "District of Columbia",
"Puerto Rico", "Guam", "American Samoa", "U.S. Virgin Islands", "Northern Mariana Islands"
]
# Recipient templates
recipient_templates = [
"To: {name}", "Recipient: {name}", "Deliver to {name}", "For: {name}",
"ATTN: {name}", "{name}", "Name: {name}", "Contact: {name}", "Receiver: {name}"
]
# Phone number templates
phone_templates = [
"Tel: {phone}", "Tel. {phone}", "Mobile: {phone}", "Phone: {phone}",
"Contact number: {phone}", "Phone number {phone}", "TEL: {phone}", "MOBILE: {phone}",
"Contact: {phone}", "P: {phone}", "{phone}", "Call: {phone}",
]
# Generate a plausible US-style phone number
def generate_us_phone():
"""Generates a random 10-digit US phone number in (XXX) XXX-XXXX format."""
area_code = random.randint(201, 999) # Avoid 0xx, 1xx area codes
exchange = random.randint(200, 999)
line = random.randint(1000, 9999)
return f"({area_code}) {exchange}-{line}"
# Use LLM to generate recipient and address information
async def generate_recipient_and_address_by_llm(state: str):
"""Uses LLM to generate a recipient's name and address details for a given state."""
prompt = f"""Please generate recipient information for a location in {state}, USA, including:
1. A realistic full English name (can be common or less common, aim for diversity).
2. A real city name within that state.
3. A specific street address (e.g., street number + name, apartment number, etc., should be realistic).
4. A corresponding 5-digit ZIP code for that city/area.
Please return only the JSON object in the following format:
{{"name": "Recipient Name", "city": "City Name", "street_address": "Specific Street Address", "zip_code": "ZIP Code"}}
Do not include any other text, just the JSON. Ensure names are diverse, not just John Doe.
"""
try:
response = await client.chat.completions.create(
messages=[{"role": "user", "content": prompt}],
model="qwen-plus-latest",
temperature=1.5, # Increase temperature for more diverse names and addresses
)
result = response.choices[0].message.content.strip()
# Clean up potential markdown code block markers
if result.startswith('```'):
result = result.split('\n', 1)[1]
if result.endswith('```'):
result = result.rsplit('\n', 1)[0]
# Try to parse JSON
info = json.loads(result)
print(info)
return info
except Exception as e:
print(f"Failed to generate recipient and address: {e}, using fallback.")
# Fallback mechanism
backup_names = ["Michael Johnson", "Emily Williams", "David Brown", "Jessica Jones", "Christopher Davis",
"Sarah Miller"]
return {
"name": random.choice(backup_names),
"city": "Anytown",
"street_address": f"{random.randint(100, 9999)} Main St",
"zip_code": f"{random.randint(10000, 99999)}"
}
# Generate a single raw data record
async def generate_record():
"""Generates one messy, combined string of US address information."""
# Randomly select a state
state = random.choice(us_states)
# Use LLM to generate recipient and address info
info = await generate_recipient_and_address_by_llm(state)
# Format recipient name
recipient = random.choice(recipient_templates).format(name=info['name'])
# Generate a phone number
phone = generate_us_phone()
phone_info = random.choice(phone_templates).format(phone=phone)
# Assemble the full address line
full_address = f"{info['street_address']}, {info['city']}, {state} {info['zip_code']}"
# Combine all components
components = [recipient, phone_info, full_address]
# Randomize the order of components
random.shuffle(components)
# Choose a random separator
separators = [' ', ', ', '; ', ' | ', '\t', ' - ', ' // ', '', ' ']
separator = random.choice(separators)
# Join the components
combined_data = separator.join(components)
return combined_data.strip()
# Generate a batch of data
async def generate_batch_data(count: int) -> List[str]:
"""Generates a specified number of data records."""
print(f"Starting to generate {count} records...")
# Use a semaphore to control concurrency (e.g., up to 20 concurrent requests)
semaphore = asyncio.Semaphore(20)
async def generate_single_record(index):
async with semaphore:
try:
record = await generate_record()
print(f"Generated record #{index + 1}: {record}")
return record
except Exception as e:
print(f"Failed to generate record #{index + 1}: {e}")
return None
# Concurrently generate data
tasks = [generate_single_record(i) for i in range(count)]
data = await asyncio.gather(*tasks)
successful_data = [record for record in data if record is not None]
return successful_data
# Save data to a file
def save_data(data: List[str], filename: str = "us_recipient_data.json"):
"""Saves the generated data to a JSON file."""
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print(f"Data has been saved to {filename}")
# Phase 1: Data Production
async def produce_data_phase():
"""Handles the generation of raw recipient data."""
print("=== Phase 1: Starting Raw Recipient Data Generation ===")
# Generate 2000 records
batch_size = 2000
data = await generate_batch_data(batch_size)
# Save the data
save_data(data, "us_recipient_data.json")
print(f"\nTotal records generated: {len(data)}")
print("\nSample Data:")
for i, record in enumerate(data[:3]): # Show first 3 as examples
print(f"{i + 1}. Raw Data: {record}\n")
print("=== Phase 1 Complete ===\n")
return True
# Define the system prompt for the extraction model
def get_system_prompt_for_extraction():
"""Returns the system prompt for the information extraction task."""
return """You are a professional information extraction assistant specializing in parsing US shipping addresses from unstructured text.
## Task Description
Based on the given input text, accurately extract and generate a JSON object containing the following six fields:
- name: The full name of the recipient.
- street_address: The complete street address, including number, street name, and any apartment or suite number.
- city: The city name.
- state: The full state name (e.g., "California", not "CA").
- zip_code: The 5 or 9-digit ZIP code.
- phone: The complete contact phone number.
## Extraction Rules
1. **Address Handling**:
- Accurately identify the components: street, city, state, and ZIP code.
- The `state` field must be the full official name (e.g., "New York", not "NY").
- The `street_address` should contain all details before the city, such as "123 Apple Lane, Apt 4B".
2. **Name Identification**:
- Extract the full recipient name.
3. **Phone Number Handling**:
- Extract the complete phone number, preserving its original format.
4. **ZIP Code**:
- Extract the 5-digit or 9-digit (ZIP+4) code.
## Output Format
Strictly adhere to the following JSON format. Do not add any explanatory text or markdown.
{
"name": "Recipient's Full Name",
"street_address": "Complete Street Address",
"city": "City Name",
"state": "Full State Name",
"zip_code": "ZIP Code",
"phone": "Contact Phone Number"
}
"""
# Use LLM to predict structured data from raw text
async def predict_structured_data(raw_data: str):
"""Uses an LLM to predict structured data from a raw string."""
system_prompt = get_system_prompt_for_extraction()
try:
response = await client.chat.completions.create(
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": raw_data}
],
model="qwen3-235b-a22b", # A powerful model is recommended for this task
temperature=0.0, # Lower temperature for higher accuracy in extraction
response_format={"type": "json_object"},
extra_body={"enable_thinking": False}
)
result = response.choices[0].message.content.strip()
# Clean up potential markdown code block markers
if result.startswith('```'):
lines = result.split('\n')
for i, line in enumerate(lines):
if line.strip().startswith('{'):
result = '\n'.join(lines[i:])
break
if result.endswith('```'):
result = result.rsplit('\n```', 1)[0]
structured_data = json.loads(result)
return structured_data
except Exception as e:
print(f"Failed to predict structured data: {e}, Raw data: {raw_data}")
# Return an empty structure on failure
return {
"name": "",
"street_address": "",
"city": "",
"state": "",
"zip_code": "",
"phone": ""
}
# Phase 2: Data Conversion
async def convert_data_phase():
"""Reads raw data, predicts structured format, and saves as SFT data."""
print("=== Phase 2: Starting Data Conversion to SFT Format ===")
try:
print("Reading us_recipient_data.json file...")
with open('us_recipient_data.json', 'r', encoding='utf-8') as f:
raw_data_list = json.load(f)
print(f"Successfully read {len(raw_data_list)} records.")
print("Starting to predict structured data using the extraction model...")
# A simple and clear system message can improve training and inference speed.
system_prompt = "You are an expert assistant for extracting structured JSON from US shipping information. The JSON keys are name, street_address, city, state, zip_code, and phone."
output_file = 'us_recipient_sft_data.json'
# Use a semaphore to control concurrency
semaphore = asyncio.Semaphore(10)
async def process_single_item(index, raw_data):
async with (semaphore):
structured_data = await predict_structured_data(raw_data)
print(f"Processing record #{index + 1}: {raw_data}")
conversation = {
"instruction": system_prompt + ' ' + raw_data,
"output": json.dumps(structured_data, ensure_ascii=False)
}
return conversation
print(f"Starting conversion to {output_file}...")
tasks = [process_single_item(i, raw_data) for i, raw_data in enumerate(raw_data_list)]
conversations = await asyncio.gather(*tasks)
with open(output_file, 'w', encoding='utf-8') as outfile:
json.dump(conversations, outfile, ensure_ascii=False, indent=4)
print(f"Conversion complete! Processed {len(raw_data_list)} records.")
print(f"Output file: {output_file}")
print("=== Phase 2 Complete ===")
except FileNotFoundError:
print("Error: us_recipient_data.json not found.")
sys.exit(1)
except json.JSONDecodeError as e:
print(f"JSON decoding error: {e}")
sys.exit(1)
except Exception as e:
print(f"An error occurred during conversion: {e}")
sys.exit(1)
# Main function
async def main():
print("Starting the data processing pipeline...")
print("This program will execute two phases in sequence:")
print("1. Generate raw US recipient data.")
print("2. Predict structured data and convert it to SFT format.")
print("-" * 50)
# Phase 1: Generate data
success = await produce_data_phase()
if success:
# Phase 2: Convert data
await convert_data_phase()
print("\n" + "=" * 50)
print("All processes completed successfully!")
print("Generated files:")
print("- us_recipient_data.json: Raw, unstructured data list.")
print("- us_recipient_sft_data.json: SFT-formatted training data.")
print("=" * 50)
else:
print("Data generation phase failed. Terminating.")
if __name__ == '__main__':
# Set event loop policy for Windows if needed
if platform.system() == 'Windows':
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
# Run the main coroutine
asyncio.run(main(), debug=False)
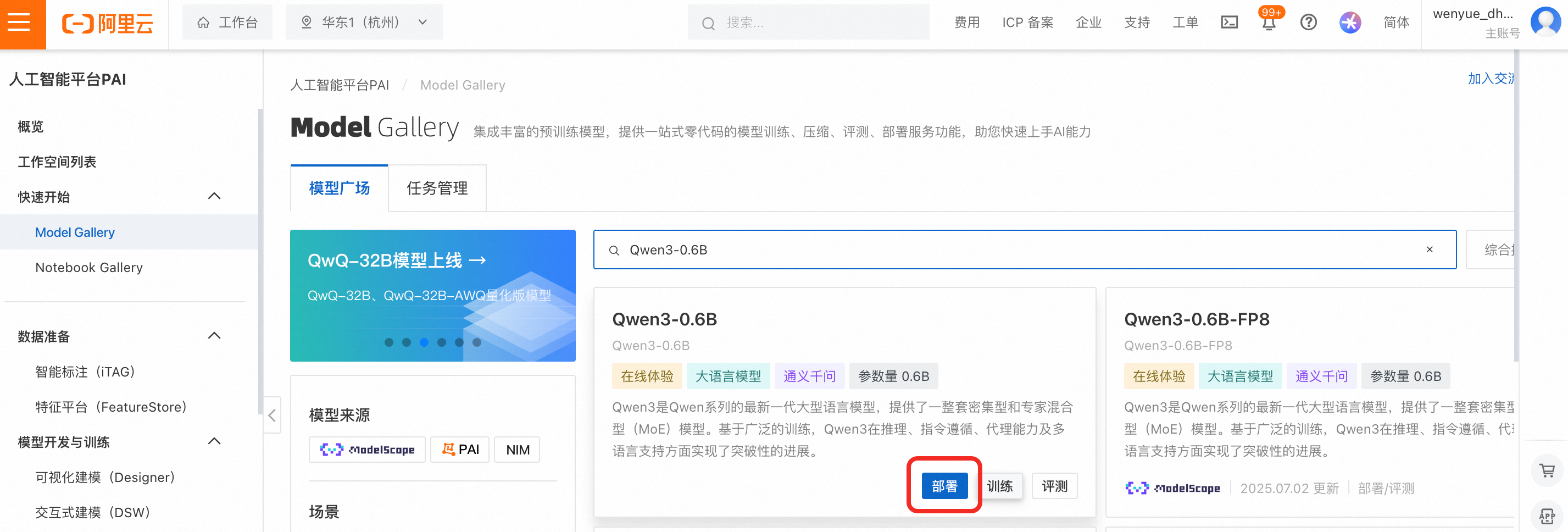
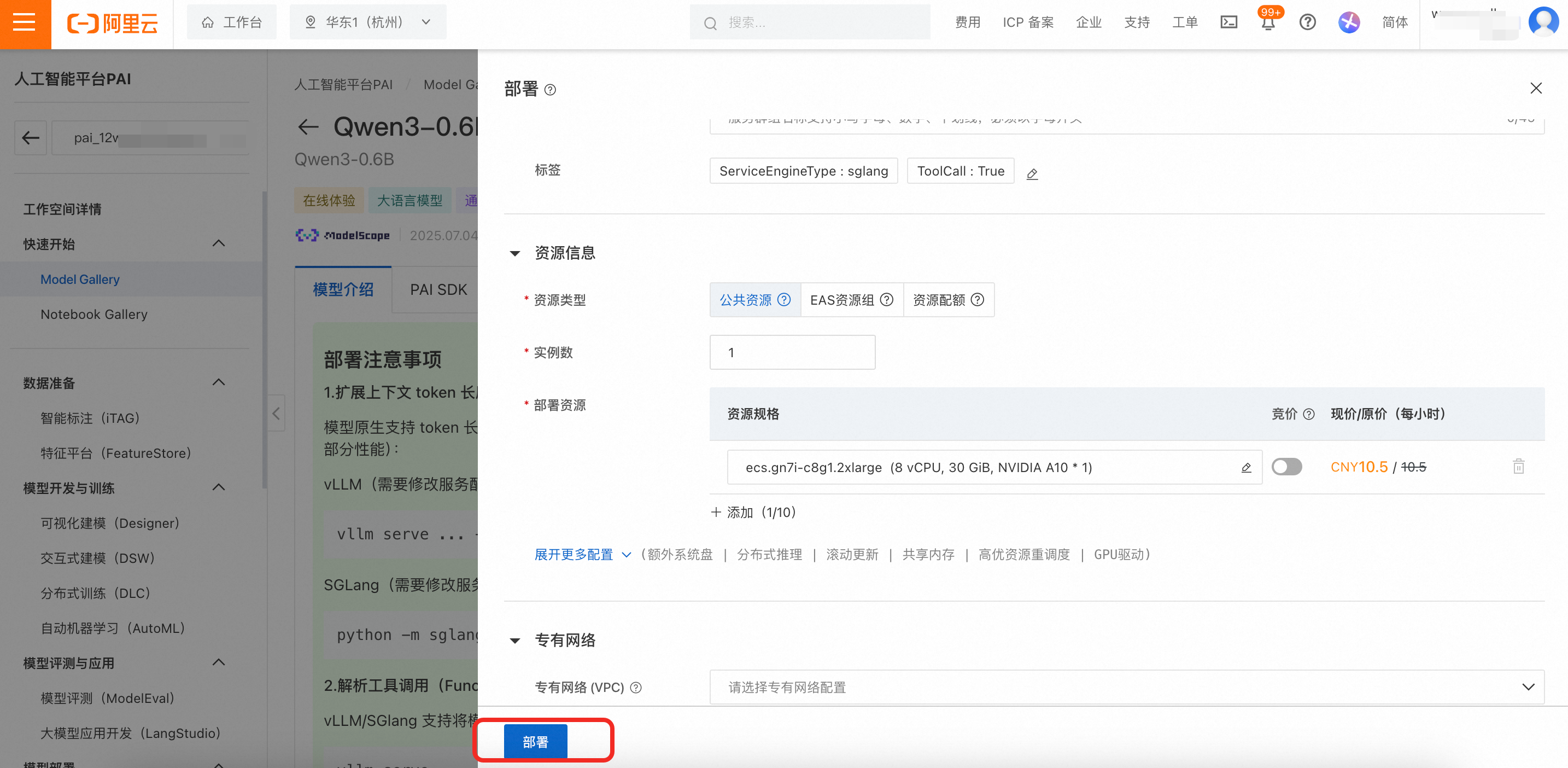

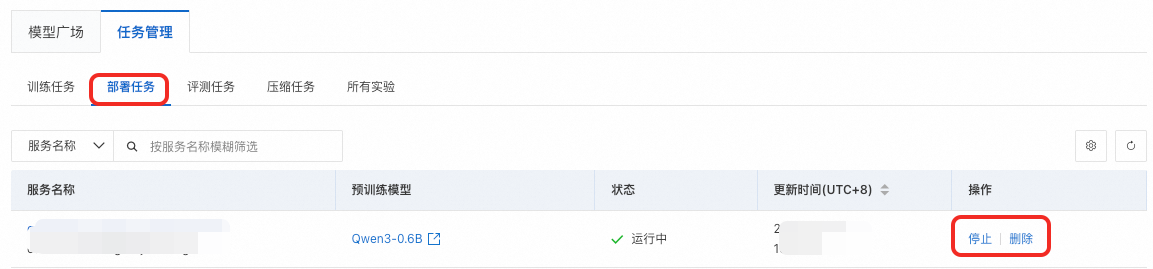
 設定按鈕,在模型服務欄中單擊添加。
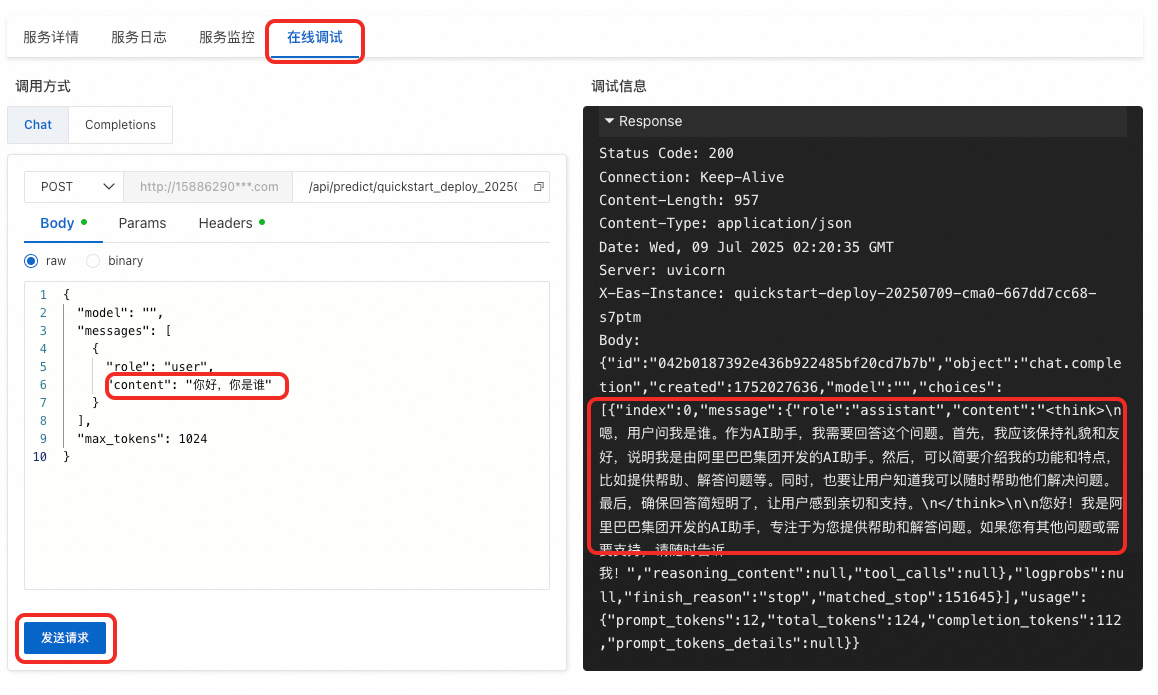
設定按鈕,在模型服務欄中單擊添加。 回到對話頁面,在視窗上方切換添加的Qwen3-0.6B模型即可開始對話。
回到對話頁面,在視窗上方切換添加的Qwen3-0.6B模型即可開始對話。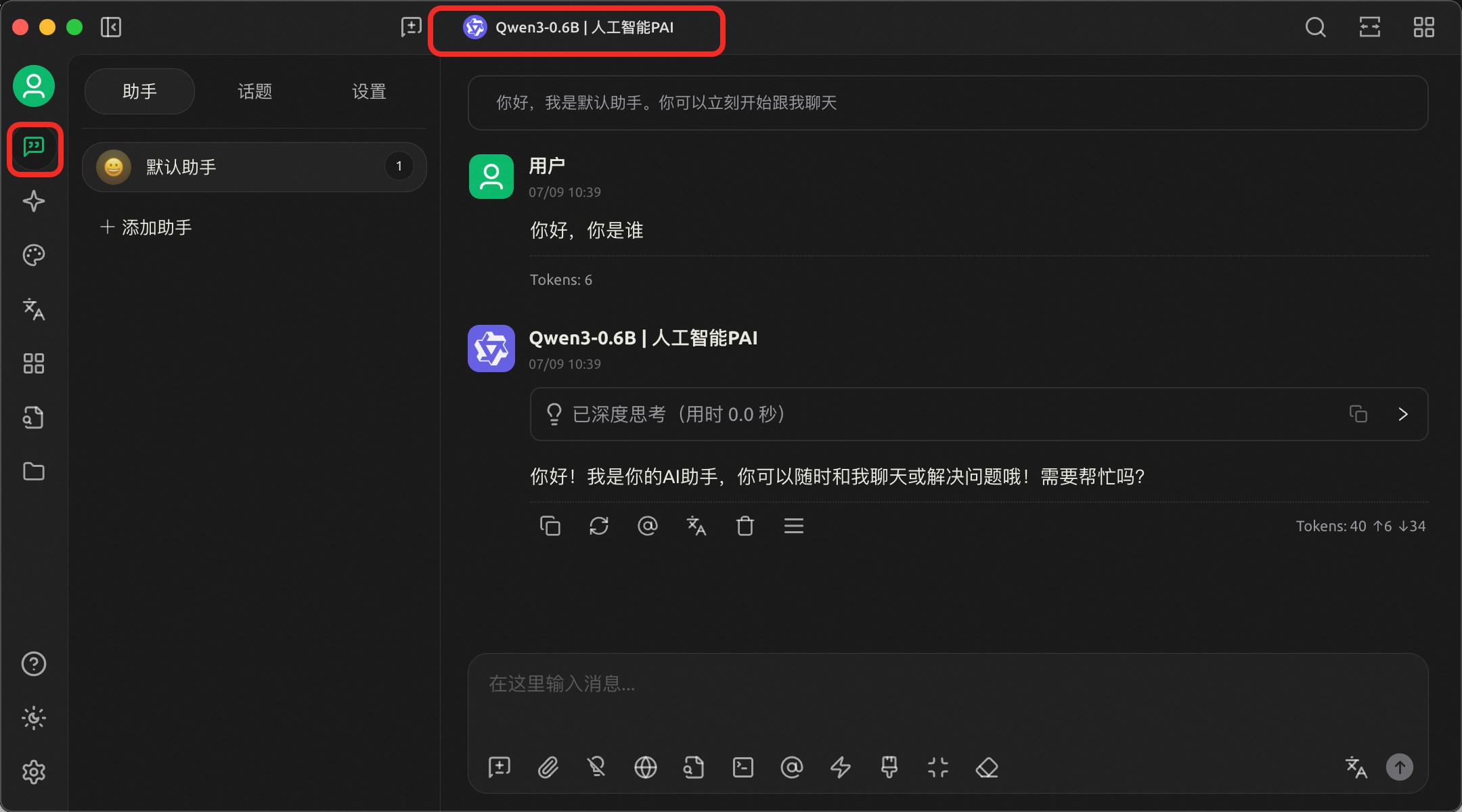
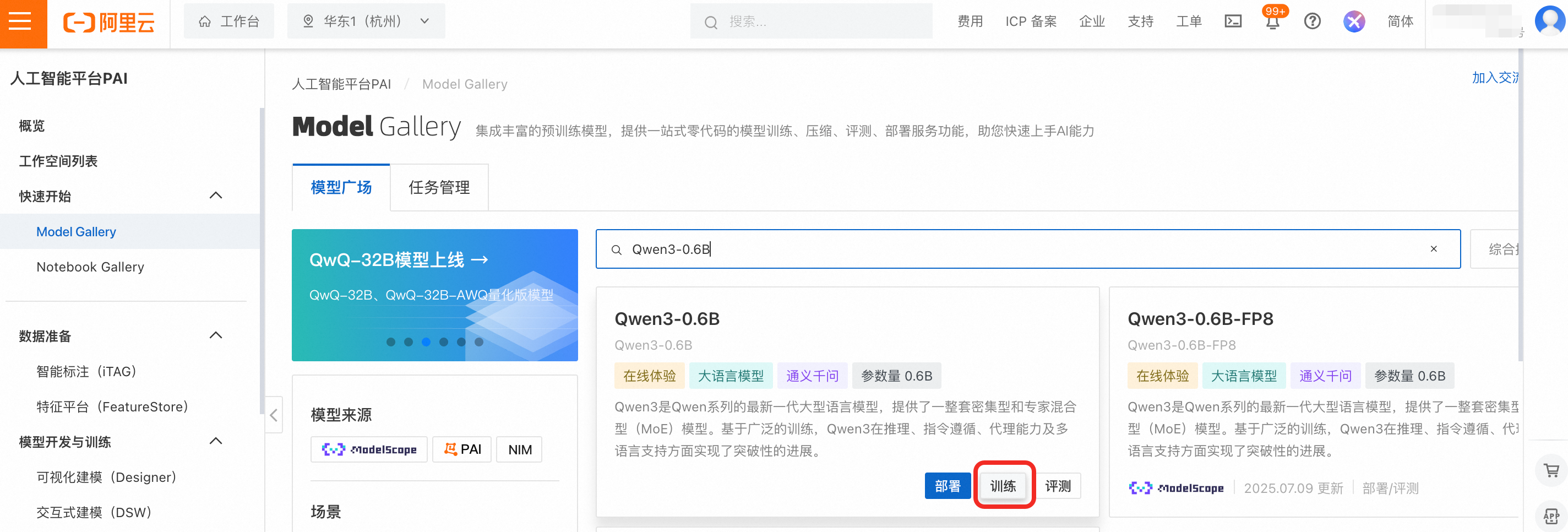
 表徵圖選擇Bucket,單擊上傳檔案將下載訓練集上傳到OSS中,並選擇該檔案。
表徵圖選擇Bucket,單擊上傳檔案將下載訓練集上傳到OSS中,並選擇該檔案。