OSS在部分地區已全面支援單帳號內網頻寬最高可達100 Gbps。本文將深入探討如何充分發揮OSS的百Gbps頻寬效能,包括關鍵要點分析,以及通過Go語言實現檔案下載並測試峰值頻寬的實踐案例。最後,還將介紹如何利用常用工具通過並發下載提升OSS的下載效能。
適用情境
在Object Storage Service的應用情境中,超過100 Gbps頻寬的需求通常出現在需要處理海量資料、支援高並發訪問或對即時性要求極高的特殊業務情境中。例如
巨量資料分析與計算:資料規模大,單次任務可能需要讀取TB級甚至PB級的資料,且即時性要求高,為提高計算效率,資料讀取速度必須足夠快,避免成為瓶頸。
AI訓練資料集載入:資料規模大,訓練資料集可能達到PB層級,有高輸送量需求,多個訓練節點同時載入資料,總頻寬需求可能達到百Gbps。
備份與恢複:資料規模大,備份和恢複操作涉及PB級資料,例如全量備份,若規定在有限時間內完成備份和恢複操作,為滿足時間要求,備份和恢複的頻寬需求可能達到百Gbps。
高效能科學計算:資料規模大,科學計算任務通常需要處理PB級甚至更大的資料集,多個研究團隊可能同時訪問同一份資料,從而產生高並發訪問和高頻寬需求。為了支援即時分析和團隊協作,確保資料轉送速度至關重要。
要點分析
要實現百Gbps寬頻,首先需要選擇合適ECS執行個體規格確保頻寬上限,其次,若涉及落盤操作,應選用高效能磁碟以提升效率。此外,訪問資料時建議通過VPC內網,以提高訪問速度,並在需要並發下載時,採用相應的最佳化技巧,以充分釋放下載頻寬的潛力。
網路接收能力
將OSS的用戶端安裝於ECS上時,資料下載速度會受ECS網路速度的制約。在阿里雲平台,當前網路能力最強的機型已能提供160 Gbps的頻寬。採用多機叢集模式時,在客戶側進行並發訪問的情況下,其總頻寬能夠達到100 Gbps;而在單機情形下,則優先選用大頻寬的網路增強型或者高主頻型(高主頻在接收大量資料包時具備速度優勢)。
需注意基於目前ECS的規格,單個彈性網卡最大支援100 Gbps的頻寬。根據ECS的規則,單機頻寬超過100 Gbps時需要掛載多個彈性網卡,具體操作請參見彈性網卡。
磁碟IO
資料下載至本地後,若執行資料落盤操作,下載速度便會受磁碟效能所限。例如ossutil、ossfs等工具在預設設定下均存在資料落盤行為,此時可考慮選用更高效能的磁碟或者記憶體盤來改善狀況,如圖所示。
儘管阿里雲ESSD雲端硬碟已可實現32 Gbps的單盤輸送量,然而與記憶體相比,仍存在顯著差距。為實現最大下載頻寬,應盡量避免資料落盤操作。有關ossfs如何避免資料落盤,提高讀取效能,請參見唯讀情境效能調優。

使用VPC網路
阿里雲內網針對網路資料請求進行了最佳化,在使用VPC內網網域名稱時,能夠擷取比公網更穩定的網路服務。若要達到最大頻寬,需採用VPC內網網路服務。
客戶的ECS運行於客戶的VPC網路之中,OSS提供了可供任意客戶VPC訪問的統一內網網域名稱(例如:oss-cn-beijing-internal.aliyuncs.com)。ECS與OSS之間的資料流會經過SLB負載平衡,請求被發送至後端的分布式叢集裡,從而將資料請求的壓力均勻分散到整個叢集,使OSS具備了強大的高並發處理能力。
並發下載
OSS採用HTTP協議傳輸資料,鑒於單個HTTP請求的效能存在局限,對OSS實施資料下載加速的一項基本策略為並發下載。即把一個檔案分割成多個range,讓每個請求僅訪問其中一個range,通過這種方式來擷取最大的下載頻寬。由於OSS依據API調用次數計費,所以並非將檔案切分得越細小越好。range越小,API調用次數就會越多,並且更小的range其單流下載速度也無法達到峰值。有關常用工具的並發下載技巧,請參見常用工具並發下載技巧。
實踐案例
為了測試最大頻寬的下載能力,我們專門構建了一個Go語言測試程式,用於從OSS下載一個100 GB大小的二進位bin檔案。在該程式的設計中,我們採用了特殊的資料處理策略,資料不進行落盤操作,即資料讀取一遍後便直接丟棄。同時,將大檔案的讀取過程拆分成多個range,並且把range的大小以及並發資料量設定為可調節的參數,這樣就能方便地通過調整這些參數來實現最大頻寬的下載效果。具體的實驗過程如下。
實驗環境
執行個體規格 | vCPU | 記憶體(GiB) | 網路頻寬基礎/突發(Gbit/s) | 網路收發包PPS | 串連數 | 多隊列 | 彈性網卡 | 單網卡私人IPv4/IPv6地址數 | 可掛載的雲端硬碟數 | 雲端硬碟IOPS基礎/突發 | 雲端硬碟頻寬基礎/突發(Gbit/s) |
ecs.hfg8i.32xlarge | 128 | 512 | 100/無 | 3000 萬 | 400 萬 | 64 | 15 | 50/50 | 64 | 90萬/無 | 64/無 |
測試步驟
配置環境變數。
export OSS_ACCESS_KEY_ID=<ALIBABA_CLOUD_ACCESS_KEY_ID> export OSS_ACCESS_KEY_SECRET=<ALIBABA_CLOUD_ACCESS_KEY_SECRET>程式碼範例。
package main import ( "context" "flag" "fmt" "io" "log" "time" "github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss" "github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/credentials" ) // 定義全域變數,用於儲存命令列參數 var ( region string // OSS 儲存桶所在的地區 endpoint string // OSS 服務的訪問網域名稱 bucketName string // OSS 儲存桶的名稱 objectName string // OSS 對象的名稱 chunkSize int64 // 分塊大小(位元組) prefetchNum int // 預取數量 ) // 初始化函數,用於解析命令列參數 func init() { flag.StringVar(®ion, "region", "", "The region in which the bucket is located.") flag.StringVar(&endpoint, "endpoint", "", "The domain names that other services can use to access OSS.") flag.StringVar(&bucketName, "bucket", "", "The `name` of the bucket.") flag.StringVar(&objectName, "object", "", "The `name` of the object.") flag.Int64Var(&chunkSize, "chunk-size", 0, "The chunk size, in bytes") flag.IntVar(&prefetchNum, "prefetch-num", 0, "The prefetch number") } func main() { // 解析命令列參數 flag.Parse() // 檢查必要的參數是否提供 if len(bucketName) == 0 { flag.PrintDefaults() log.Fatalf("invalid parameters, bucket name required") } if len(region) == 0 { flag.PrintDefaults() log.Fatalf("invalid parameters, region required") } // 配置 OSS 用戶端 cfg := oss.LoadDefaultConfig(). WithCredentialsProvider(credentials.NewEnvironmentVariableCredentialsProvider()). // 使用環境變數中的憑證 WithRegion(region) // 設定地區 // 如果提供了自訂 endpoint,則設定 if len(endpoint) > 0 { cfg.WithEndpoint(endpoint) } // 建立 OSS 用戶端 client := oss.NewClient(cfg) // 開啟 OSS 檔案 f, err := client.OpenFile(context.TODO(), bucketName, objectName, func(oo *oss.OpenOptions) { oo.EnablePrefetch = true // 啟用預取 oo.ChunkSize = chunkSize // 設定分塊大小 oo.PrefetchNum = prefetchNum // 設定預取數量 oo.PrefetchThreshold = int64(0) // 設定預取閾值 }) if err != nil { log.Fatalf("open fail, err:%v", err) } // 記錄開始時間 startTick := time.Now().UnixNano() / 1000 / 1000 // 將檔案內容讀取並丟棄(用於測試讀取速度) written, err := io.Copy(io.Discard, f) // 記錄結束時間 endTick := time.Now().UnixNano() / 1000 / 1000 if err != nil { log.Fatalf("copy fail, err:%v", err) } // 計算讀取速度(MiB/s) speed := float64(written/1024/1024) / float64((endTick-startTick)/1000) // 輸出平均讀取速度 fmt.Printf("average speed:%.2f(MiB/s)\n", speed) }啟動測試程式。
go run down_object.go -bucket yourbucket -endpoint oss-cn-hangzhou-internal.aliyuncs.com -object 100GB.file -region cn-hangzhou -chunk-size 419430400 -prefetch-num 256
測試結論
在測試實際下載耗時的過程中,我們通過調整並發度和chunk大小來觀察資料變化。一般來說,並發度設定為core的1-4倍較為合適,chunk大小則盡量與FileSize/Concurrency的值保持一致,且不能小於2 MB。按照這樣的參數設定,最終獲得了最短的下載耗時,測試中的峰值速度達到了100 Gbps。
序號 | Concurrency(並發數) | blcokSize(塊大小:MB) | 峰值頻寬(Gbps) | e2e(端到端時間:s) |
1 | 128 | 800 | 100 | 16.321 |
2 | 256 | 400 | 100 | 14.881 |
3 | 512 | 200 | 100 | 15.349 |
4 | 1024 | 100 | 100 | 19.129 |
常用工具並發下載技巧
以下為您介紹常用工具在最佳化Object Storage Service下載效能方面的具體方法與應用策略。
ossutil
參數說明
選項名稱
描述
--bigfile-threshold
開啟大檔案斷點續傳的檔案大小閾值,單位為Byte,預設值為100 MByte,取值範圍為0~9223372036854775807。
--range
下載檔案時,可以指定檔案內容的位元組範圍進行下載,位元組從0開始編號。
可以指定一個區間,例如3-9表示從第3個位元組到第9個位元組(包含第3和第9位元組)。
可以指定從什麼欄位開始,例如3-表示從第3個位元組開始到檔案結尾(包含第3個位元組)。
可以指定從什麼欄位結束,例如-9表示從0位元組到第9個位元組(包含第9個位元組)。
--parallel
單檔案內部操作的並發任務數,取值範圍為1~10000,預設由ossutil根據操作類型和檔案大小自行決定。
--part-size
分區大小以位元組為單位,合適的取值範圍是2097152-16777216 B,也就是 2-16 MB。一般來說,當CPU核心數量較多時,可將分區大小設定得小一些;而當CPU核心數量較少時,則可適當調高分區大小。
參考樣本
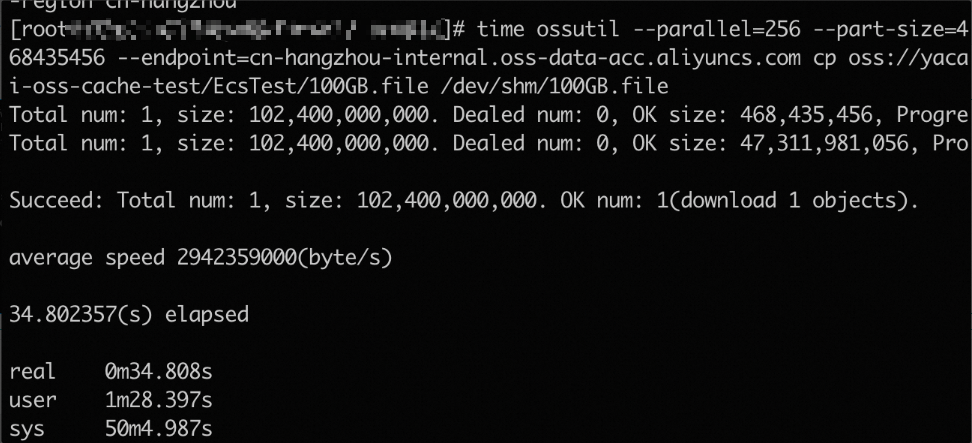
以下命令用於採用256並發處理以及468435456位元組的分塊策略,將目標Bucket中
100GB.file檔案下載到本地/dev/shm目錄,並統計耗時。time ossutil --parallel=256 --part-size=468435456 --endpoint=oss-cn-hangzhou-internal.aliyuncs.com cp oss://cache-test/EcsTest/100GB.file /dev/shm/100GB.file效能說明
端到端平均速度為2.94GB/s(約24 Gbps)。
ossfs
參數說明
選項名稱
描述
parallel_count
以分區模式上傳大檔案時,分區的並發數,預設值為5。
multipart_size
以分區模式上傳資料時分區的大小,單位是MB,預設值為10。該參數會影響最大支援的檔案大小。分區模式上傳時,最多的分區數為10000,預設值下,最大支援的檔案為100 GB。如果需要支援更大的檔案,需要根據需求調整這個值。
direct_read
預設情況下ossfs會使用磁碟空間來儲存上傳或下載的臨時資料。您可以通過設定該選項來直接從OSS讀取資料而不使用本地磁碟空間。預設不設定,您可以使用-odirect_read來開啟直讀模式。
說明當檔案在直讀過程中檢測到用write、rename或truncate操作時,該檔案會退出直讀模式直至檔案重新被開啟。
direct_read_prefetch_chunks
直讀模式下指定預讀到記憶體中chunk的數量,用來提升ossfs在順序讀情境下的效能,預設值是32。
該選項僅在開啟直讀模式,即使用-odirect_read選項時生效。
direct_read_chunk_size
直讀模式下指定一次讀請求從OSS中讀取的資料量大小,單位為MB,預設值是4。取值範圍為1~32。
該選項僅在開啟直讀模式,即使用-odirect_read選項時生效。
ensure_diskfree
控制預留磁碟空間大小。預設不預留。您可以通過該選項設定保留的可用硬碟空間大小,避免磁碟寫滿影響其他應用寫入,單位為MB。
例如,您需要設定ossfs保留1024 MB的可用磁碟空間,則可以在掛載時添加
-oensure_diskfree=1024。free_space_ratio
控制使用緩衝後的磁碟最小剩餘空間比例。例如,當磁碟空間為50GB時,如果配置為-o free_space_ratio=20,則保留50GB * 20% = 10 GB的空間。
max_stat_cache_size
用於指定檔案中繼資料的緩衝空間可緩衝多少個檔案的中繼資料。單位為個,預設值為100,000。當目錄下檔案比較多時,可以調整這個參數,加快ls的速度。如果要禁止使用中繼資料快取,可以設定為0。
stat_cache_expire
指定檔案中繼資料快取的失效時間,單位為秒,預設值為900秒。
readdir_optimize
控制是否使用緩衝最佳化,預設為不使用。
添加該掛載選項後ossfs在ls時不會發送HeadObject請求去擷取檔案項中繼資料如
gid、uid等,只有訪問檔案大小為0才發送HeadObject請求。不過,由於許可權檢查等原因,仍然可能產生一定數量的HeadObject請求,此參數請根據應用程式特性選擇。如需啟用,您可以在掛載時添加-oreaddir_optimize。參考樣本
說明具體參數大小請根據CPU處理能力和網路頻寬逐步進行調整,不建議設定過大。
預設模式:掛載名為cache-test的bucket到本地/mnt/cache-test檔案夾下,並設定分區並發數為128,每個分區大小32 MB。
ossfs cache-test /mnt/cache-test -ourl=http://oss-cn-hangzhou-internal.aliyuncs.com -oparallel_count=128 -omultipart_size=32直讀模式:掛載名為cache-test的bucket到本地/mnt/cache-test檔案夾下,同時開啟直讀模式,設定預取chunk數量為128,每個chunk大小32 MB。
ossfs cache-test /mnt/cache-test -ourl=http://oss-cn-hangzhou-internal.aliyuncs.com -odirect_read -odirect_read_prefetch_chunks=128 -odirect_read_chunk_size=32
效能說明
預設模式中資料會進行落盤。直讀模式資料儲存在記憶體中,訪問效果更高,但是記憶體開銷更大。
說明在直讀模式下,ossfs以chunk為單位管理下載資料,預設chunk大小為4 MB,可通過direct_read_chunk_size參數自行設定。ossfs會在記憶體中保留 [當前 chunk - 1, 當前 chunk + direct_read_prefetch_chunks] 區間內的資料。判斷是否適合採用直讀模式,可依據記憶體大小,尤其是pagecache空間來確定。一般來說,當pagecache不夠大時更適合直讀模式。比如,機器總記憶體為16 GB,pagecache可以使用6 GB,那麼直讀模式適合6 GB以上的檔案。有關直讀模式詳細介紹,請參見直讀模式。
模式
Concurrency(並發數)
blcokSize(塊大小:MB)
峰值頻寬(Gbps)
e2e 頻寬(Gbps)
e2e 耗時(s)
預設
128
32
24
11.3
72.01
直讀
128
32
24
16.1
50.9
針對模型讀取的最佳化:
模型大小(GB)
預設模式(耗時:s,限制記憶體6 GB)
混合直讀模式(耗時:s)
混合直讀模式(耗時:s,調整chunk保留視窗[-32, +32])
1
8.19
8.20
8.56
2.4
24.5
20.43
20.02
5
26.5
22.3
19.89
5.5
22.8
23.1
22.98
8.5
106.0
36.6
36.00
12.6
154.6
42.1
41.9
Python SDK
在AI模型訓練情境裡,Python SDK預設是以串列方式訪問後端儲存服務的。 通過Python的並發庫進行多線程改造,頻寬獲得了極為顯著的提升。
實驗情境
測試選用的模型檔案大小約為5.6 GB,測試機器的規格為ECS48vCPU、具備16 Gbps頻寬以及180 GB記憶體。
測試樣本
import oss2 import time import os import threading from io import BytesIO # 配置參數(通過環境變數擷取) OSS_CONFIG = { "bucket_endpoint": os.environ.get('OSS_BUCKET_ENDPOINT', 'oss-cn-hangzhou-internal.aliyuncs.com'), # 預設Endpoint樣本 "bucket_name": os.environ.get('OSS_BUCKET_NAME', 'bucket_name'), #Bucket 名稱 "access_key_id": os.environ['ACCESS_KEY_ID'], # RAM使用者ACCESS_KEY_ID "access_key_secret": os.environ['ACCESS_KEY_SECRET'] # RAM使用者ACCESS_KEY_SECRET } # 初始化 OSS Bucket 對象 def __bucket__(): auth = oss2.Auth(OSS_CONFIG["access_key_id"], OSS_CONFIG["access_key_secret"]) return oss2.Bucket( auth, OSS_CONFIG["bucket_endpoint"], OSS_CONFIG["bucket_name"], enable_crc=False ) # 擷取對象大小 def __get_object_size(object_name): simplifiedmeta = __bucket__().get_object_meta(object_name) return int(simplifiedmeta.headers['Content-Length']) # 擷取遠程模型最後修改時間 def get_remote_model_mmtime(model_name): return __bucket__().head_object(model_name).last_modified # 列出遠程模型檔案 def list_remote_models(ext_filter=('.ckpt',)): # 添加預設副檔名過濾 dir_prefix = "" output = [] for obj in oss2.ObjectIteratorV2( __bucket__(), prefix=dir_prefix, delimiter='/', start_after=dir_prefix, fetch_owner=False ): if not obj.is_prefix(): _, ext = os.path.splitext(obj.key) if ext.lower() in ext_filter: output.append(obj.key) return output # 分段下載線程函數 def __range_get(object_name, buffer, offset, start, end, read_chunk_size, progress_callback, total_bytes): chunk_size = int(read_chunk_size) with __bucket__().get_object(object_name, byte_range=(start, end)) as object_stream: s = start while True: chunk = object_stream.read(chunk_size) if not chunk: break buffer.seek(s - offset) buffer.write(chunk) s += len(chunk) # 計算已下載位元組數並調用進度回調 if progress_callback: progress_callback(s - start, total_bytes) # 讀取遠程模型(增加進度回調選擇性參數) def read_remote_model( checkpoint_file, start=0, size=-1, read_chunk_size=2*1024*1024, # 2MB part_size=256*1024*1024, # 256MB progress_callback=None # 進度回調 ): time_start = time.time() buffer = BytesIO() obj_size = __get_object_size(checkpoint_file) end = (obj_size if size == -1 else start + size) - 1 s = start tasks = [] # 進度計算 total_bytes = end - start + 1 downloaded_bytes = 0 while s <= end: current_end = min(s + part_size - 1, end) task = threading.Thread( target=__range_get, args=(checkpoint_file, buffer, start, s, current_end, read_chunk_size, progress_callback, total_bytes) ) tasks.append(task) task.start() s += part_size for task in tasks: task.join() time_end = time.time() # 顯示總耗時 print(f"Downloaded {checkpoint_file} in {time_end - time_start:.2f} seconds.") # 計算並列印下載檔案的大小(單位:GB) file_size_gb = obj_size / (1024 * 1024 * 1024) print(f"Total downloaded file size: {file_size_gb:.2f} GB") buffer.seek(0) return buffer # 進度回呼函數 def show_progress(downloaded, total): progress = (downloaded / total) * 100 print(f"Progress: {progress:.2f}%", end="\r") # 調用樣本 if __name__ == "__main__": # 調用 list_remote_models 方法列出遠程模型檔案 models = list_remote_models() print("Remote models:", models) if models: # 選擇第一個模型檔案進行下載 first_model = models[0] buffer = read_remote_model(first_model, progress_callback=show_progress) print(f"\nDownloaded {first_model} to buffer.")實驗結論
版本
OSS耗時 /s
OSS平均頻寬 MB/s
OSS峰值頻寬MB/s
OSS pythonSDK
109
53
100
OSS pythonSDK(並發下載)
11.1
516
600
從實驗結果資料能夠明顯看出,相較於串列模式下的OSS Python SDK,並發下載模式下的耗時僅為前者的約0.2%,平均頻寬是前者的約9.7倍,峰值頻寬達到了前者的6倍。由此可見,在使用Python SDK進行AI模型訓練時,採用並發下載的方式能夠極大地提高處理效率,並大幅提升頻寬效能。
其他方案
除了單獨直接調用 SDK 這種方式,阿里雲還專門提供了一個名為osstorchconnector的Python庫,它主要用於在PyTorch訓練任務中高效地訪問和儲存OSS資料。該庫已經為使用者完成了並發的二次封裝,使用者可以直接使用。下面是有關使用osstorchconnector進行AI模型載入的測試結果。更多有關osstorchconnector的效能測試內容,請參見效能測試。
專案
詳細資料
實驗情境
模型載入與聊天問答
模型名稱
gpt3-finnish-3B
模型大小
11 GB
應用情境
聊天問答
硬體設定
高規格ECS:96核(vCPU)、384 GiB記憶體、30 Gbps內網頻寬
實驗結論
平均頻寬約為10 Gbps,OSS服務端可支援10個任務同時載入模型