您可以在體驗中心通過可視化方式體驗文檔解析、圖片內容提取、文檔切片等各類服務,協助您快速評估服務是否滿足業務訴求。
功能介紹
體驗中心提供以下服務:
服務類別 | 服務說明 |
文檔內容解析 | 通用文檔解析服務,支援從非結構化文檔(文本、表格、圖片等)中提取標題、分段等邏輯層級結構,以結構化格式輸出。 |
圖片內容解析 | 圖片內容理解服務:基於多模態大模型對圖片內容進行解析理解以及文字識別,解析後的文本可用於圖片檢索、問答情境。 |
圖片文本識別服務:OCR圖片文本識別,識別後的文本可用於圖片檢索問答情境。 | |
文檔切片 | 提供通用文本切片服務,支援基於文檔段落、文本語義、指定規則,對HTML、Markdown、TXT格式的結構化資料進行拆分,同時支援以富文本形式提取文檔中的代碼、圖片以及表格。 |
文本向量化 |
|
多模態向量化 |
|
文本稀疏向量化 提供將文本資料轉化為稀疏向量形式表達的服務,稀疏向量儲存空間更小,常用於表達關鍵詞和詞頻資訊,可與稠密向量搭配進行混合檢索,提升檢索效果。 | OpenSearch文本稀疏向量化服務:提供多語言(100+)文本向量化服務,輸入文本最大長度8192 token。 |
向量降維 | 向量降維embedding-dim-reduction:提供向量模型調優服務,可通過定製訓練向量降維等模型,在不帶來過多檢索效果損失的情況下,輔助將高維度向量降低維度,以便提升性價比。 |
查詢分析 提供Query內容分析服務,基於大語言模型及NLP能力,可對使用者輸入的查詢內容進行意圖識別、相似問題擴充、NL2SQL處理等,有效提升RAG情境中檢索問答效果。 | 通用Query分析服務,基於大語言模型對使用者輸入Query進行意圖理解以及相似問題擴充。 |
排序服務 |
|
語音辨識 | 語音辨識服務001:提供語音轉文本能力,可將視頻或音頻中的語音內容快速轉化為結構化文本。該服務支援多種語言。 |
視頻截幀 | 視頻截幀服務001:提供視頻內容提取能力,可從視頻中捕獲主要畫面格畫面。結合多模態向量服務或圖片解析能力,實現跨模態檢索。 |
大模型 |
|
連網搜尋 | 搜尋過程中,當私人知識庫無法給出相應的答案時,可拓展連網搜尋,擷取更多互連網資訊,補充私人知識庫,結合大語言模型給出更豐富的回答。 |
功能體驗
文檔解析
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服务类别選擇文档解析/图片解析(document-analyze),選擇具體的体验服务。
體驗資料可以使用系統提供的示例数据,支援通過管理数据上傳您自己的資料,檔案類型支援Txt、Pdf、Html、Doc、Docx、Ppt、Pptx格式,大小不超過20M。
文件:上傳本地檔案,7天后自動清除, 平台不會長期儲存您的資料。
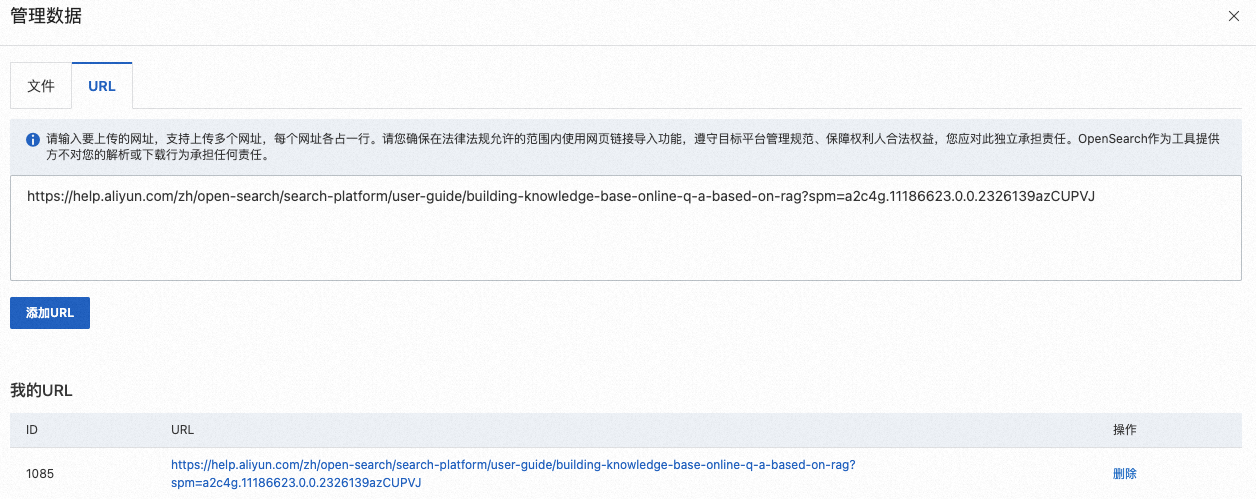
URL:提供檔案URL地址和對應的檔案類型,支援上傳多個網址,每個網址各佔一行。
說明資料格式選擇錯誤會導致文檔解析失敗,請根據檔案資料選擇正確的檔案類型。
 重要
重要請您確保在法律法規允許的範圍內使用網頁連結匯入功能,遵守目標平台管理規範、保障權利人合法權益,您應對此獨立承擔責任。AI搜尋開放平台作為工具提供方不對您的解析或下載行為承擔任何責任。
如您使用自己的資料,從下拉式清單中選擇提前上傳的檔案或者URL。
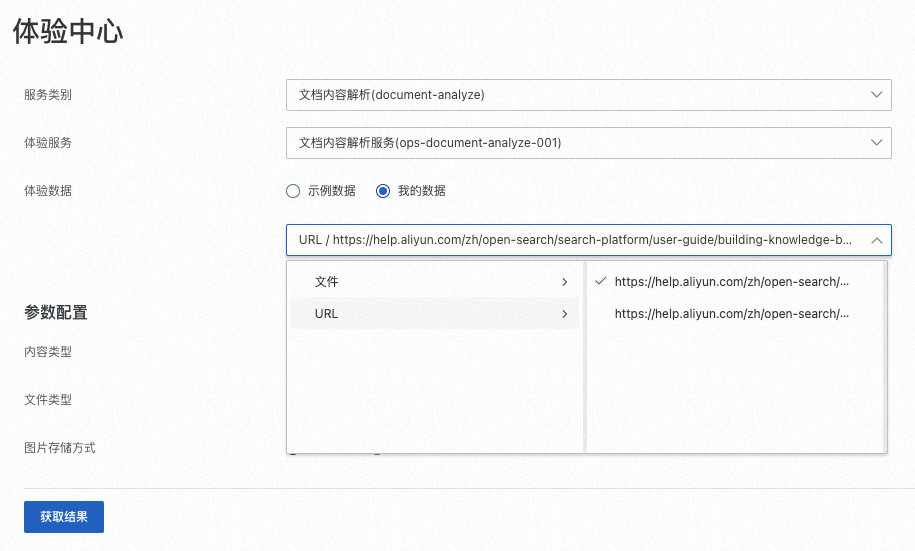
單擊获取结果,系統調用服務解析文檔。
结果:展示解析進度和解析結果
结果源码:查看結果響應代碼、通過复制代码或者下载文件將代碼下載到本地。
示例代码:查看和下載調用常值內容解析服務的示例代码。

文檔切片
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服务类别選擇文档切片(document-split),選擇具體的体验服务。
體驗資料可以使用系統提供的示例数据,也支援選擇我的数据,輸入您自己的資料,並選擇正確的資料格式Txt、Html、MarkDown。
說明資料格式選擇錯誤會導致文檔解析失敗,請根據上傳的資料正確選擇格式。
設定切片最大长度,預設值為300,最大長度為1024,單位為Token。
可根據需要設定是否需要返回句级别切片,單擊获取结果,系統調用服務對文檔進行切片。
结果:展示切片進度和結果。
结果源码:查看結果響應代碼、通過复制代码或者下载文件可以將代碼下載到本地。
示例代码:查看和下載調用文檔切片服務的示例代码。
文本向量/稀疏向量
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服务类别選擇文本向量化(text-embedding),選擇具體的体验服务。
向量化内容类型支援文檔document和query。
支援通過添加一组文本或者直接输入JSON添加待向量化文本。
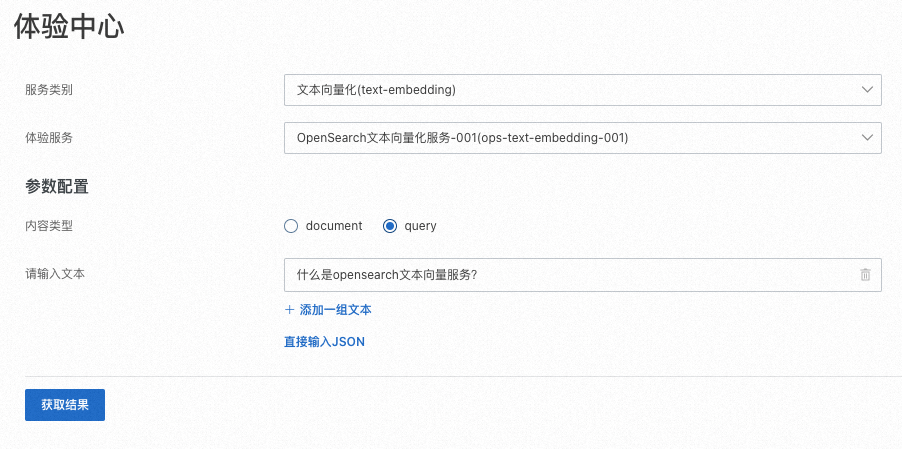
單擊获取结果,擷取文本進行向量化結果。
结果:展示向量化結果

结果源码:查看結果響應代碼、通過複製代碼或者下載檔案將代碼下載到本地。
示例代码:查看和下載調用文本向量化服務的示例代码。
多模態向量
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服务类别選擇多模态向量(multi-modal-embedding),選擇具體的体验服务,選擇文本、图片或者文本+图片。
 說明
說明上傳本地圖片進行向量化時,圖片將在7天后自動清除, 平台不會長期儲存您的資料。
單擊获取结果,擷取多模態向量化結果。
结果:展示向量化結果
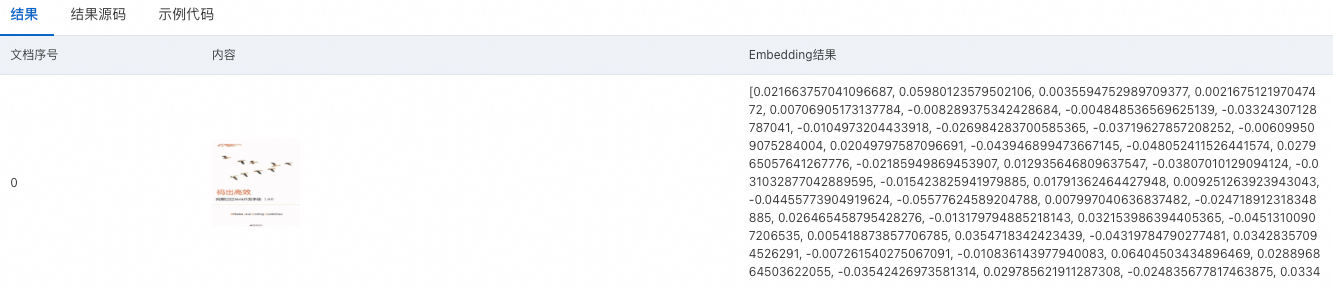
结果源码:查看結果響應代碼、通過复制代码或者下载文件將代碼下載到本地。
示例代码:查看和下載調用文本向量化服務的示例代码。
排序服務
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服务类别選擇排序服务(ranker),選擇具體的体验服务。
體驗資料可以使用系統提供的示例数据,也支援輸入您自己的資料。
在Query中輸入文本。
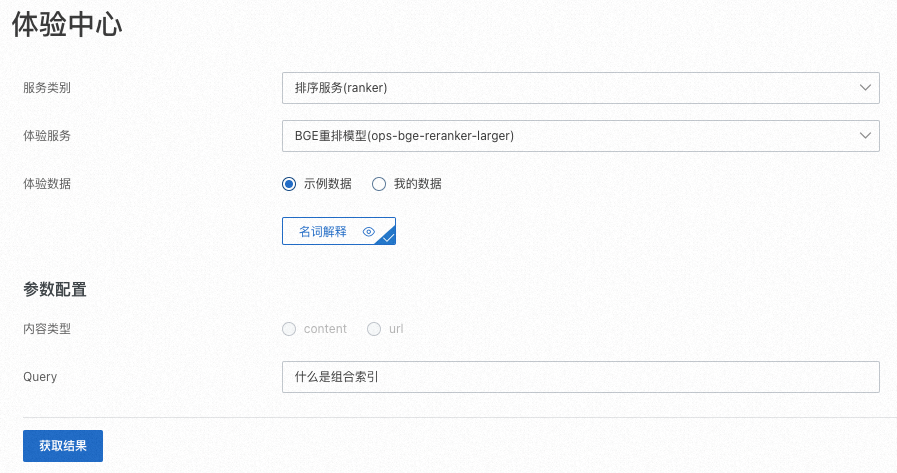
單擊获取结果,系統調用排序服務,根據查詢(query)和文檔內容的相關性對文檔排序,並輸出打分結果。
结果:展示排序打分結果
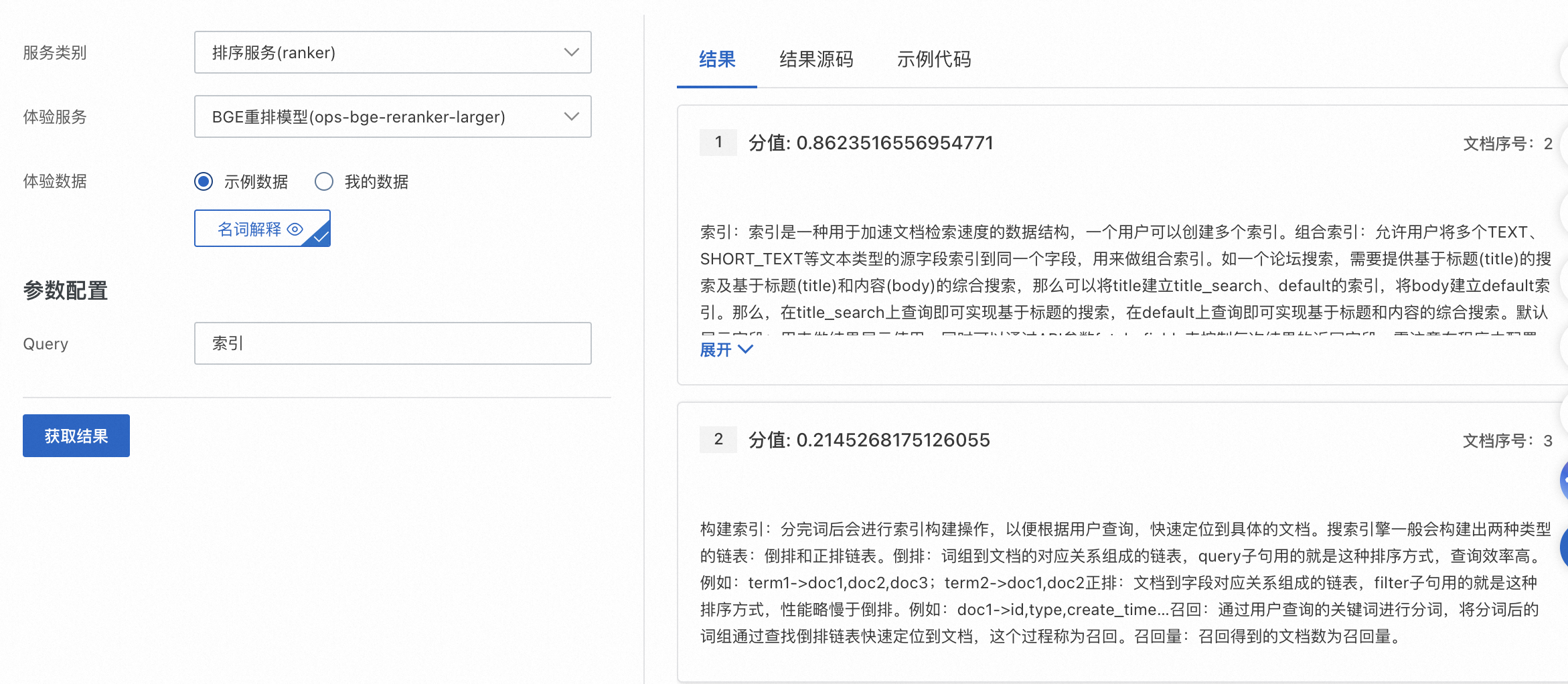
结果源码:查看結果響應代碼、通過复制代码或者下载文件將代碼下載到本地。
示例代码:查看和下載調用排序服務的示例代码。
視頻截幀
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服務類別選擇视频截帧(video-snapshot)。
體驗資料可以使用系統提供的示例数据,也支援上傳您自有的視頻資料。
單擊获取结果,系統調用視頻截幀服務,截取目標視頻的主要畫面格畫面。
語音辨識
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服務類別選擇语音识别(audio-asr)。
體驗資料可以使用系統提供的示例数据,也支援上傳您自有的語音資料。
單擊获取结果,系統調用語音辨識服務,將目標資料中的語音內容轉化為結構化文本。
大語言模型(LLM)服務
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服务类别選擇大模型(text-generation),選擇具體的体验服务,可單擊
 開啟联网搜索服務,系統根據使用者問題判斷是否進行連網搜尋。
開啟联网搜索服務,系統根據使用者問題判斷是否進行連網搜尋。輸入問題並提交,大模型理解輸入問題並給出答案。
重要產生的所有內容均由人工智慧模型產生,其產生內容的準確性和完整性無法保證,不代表我們的態度或觀點。
大模型回答結果頁面展示本輪問答的輸入和輸出Token數,並可刪除本輪對話及複製全文。
圖片內容解析
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服务类别選擇图片内容解析(image-analyze),在体验服务中選擇图片内容理解服务001或者图片文本识别服务001。
體驗資料可以使用系統提供的樣本圖片,也支援輸入您自己的圖片。

單擊获取结果,系統調用圖片內容解析服務,對圖片內容進行理解並輸出,或者識別並輸出圖片關鍵資訊。
结果:展示識別結果

结果源码:查看結果響應代碼、通過复制代码或者下载文件將代碼下載到本地。
示例代码:查看和下載調用圖片內容解析服務的示例代码。
查詢分析
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服务类别選擇查询分析(query-analyze)。
您可以直接輸入Query進行查詢意圖識別,或者在历史消息地區構造多輪對話並輸入Query,模型結合多輪對話和Query進行查詢意圖識別。
開啟显示NL2SQL服務並選擇已建立的服務配置,實現將自然語言查詢轉換為SQL語句。
單擊获取结果,查看模型效果。
结果:展示識別結果
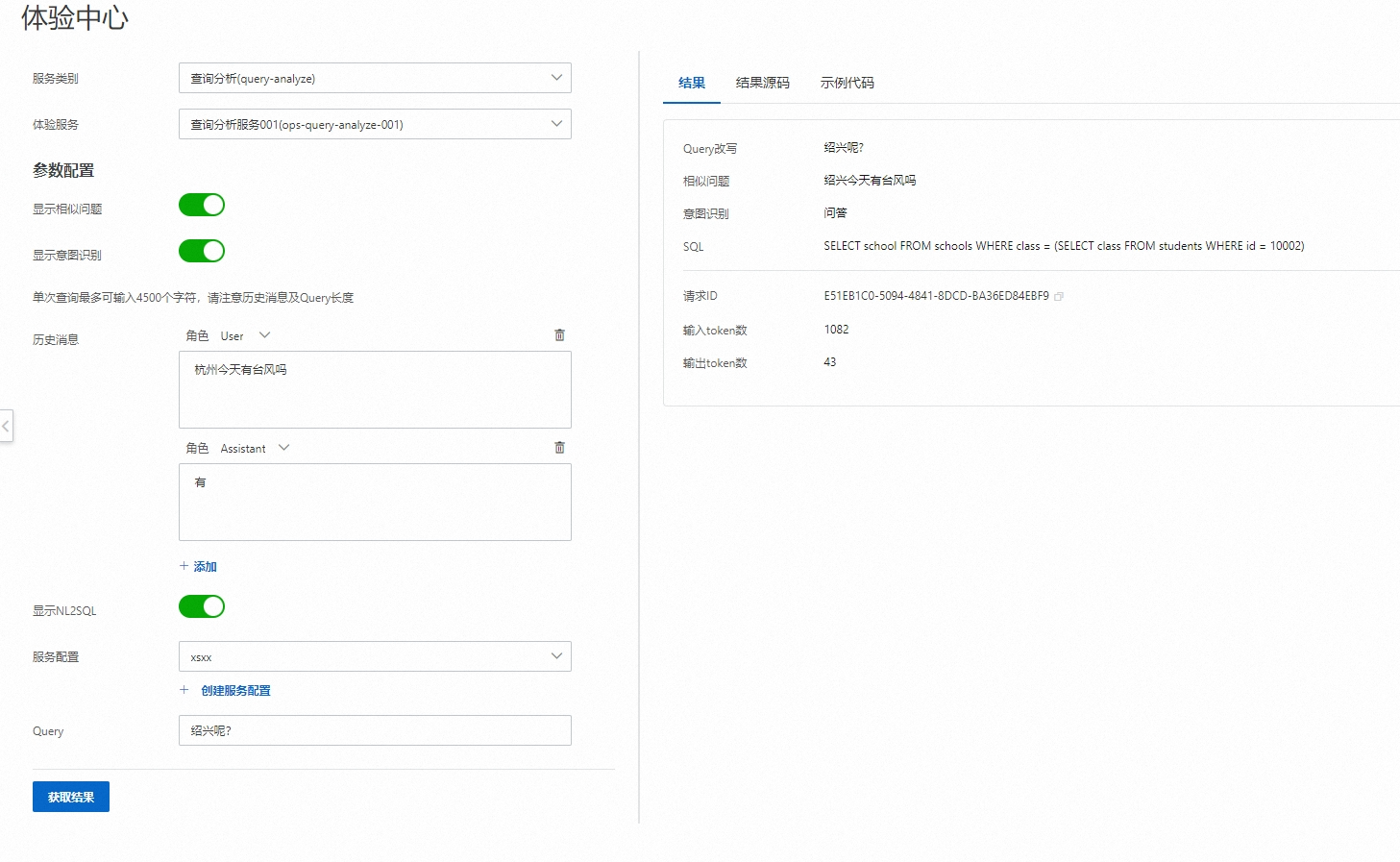
结果源码:查看結果響應代碼、通過复制代码或者下载文件將代碼下載到本地。
示例代码:查看和下載調用查詢分析服務的示例代码。
向量微調
登入AI搜尋開放平台控制台。
在左側導覽列選擇体验中心。
服务类别選擇向量降维(embedding-dim-reduction)。
選擇模型名稱(您基於自己的業務資料微調訓練後的模型),填寫输出向量维度,輸出向量維度應小於或者等於實際模型訓練時選擇的向量欄位的維度,讓後请输入原始向量。
單擊获取结果,查看模型效果。
如何進行降維模型訓練請參見服務定製。
連網搜尋
支援通過以下兩種方式使用連網搜尋:
直接調用連網搜尋服務。
使用LLM模型時啟用連網搜尋。
登入AI搜尋開放平台控制台。
選擇目標地區,切換到AI搜索开放平台。
在左側導覽列選擇体验中心。
服务类别選擇联网搜索服务(web-search)。
輸入問題Query,如“杭州怎麼玩”,返回結果。