RAG效果最佳化
如果您在使用阿里雲百鍊應用的 RAG 功能時遇到知識召回不完整或內容不準確的問題,可以參考本文的建議和樣本以提升 RAG 效果。
1. RAG 工作流程簡介
RAG(Retrieval Augmented Generation,檢索增強產生)是一種結合了資訊檢索和文本產生的技術,能夠在大模型產生答案時利用外部知識庫中的相關資訊。
其工作流程包含解析與切片、向量儲存、檢索召回、產生答案等幾個關鍵階段。
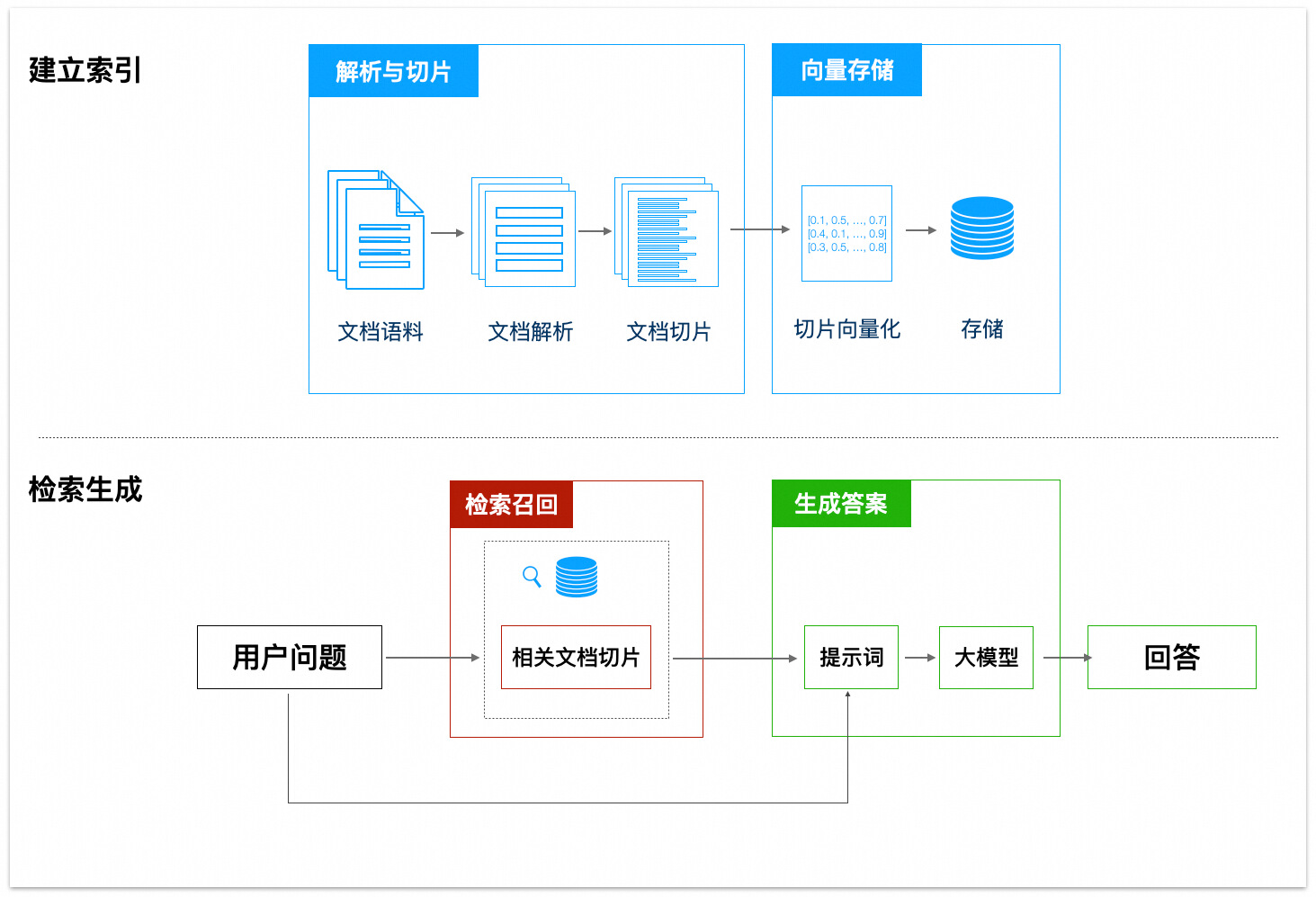
接下來,本文將從 RAG 的解析與切片、檢索召回、產生答案階段入手,協助您最佳化 RAG 的效果。
2. RAG 效果最佳化
2.1 準備工作
首先,請確保匯入阿里雲百鍊知識庫的文檔符合以下要求:
-
包含相關知識:如果知識庫中沒有相關知識,那麼大模型大機率無法回答相關問題。解決方案就是更新知識庫,補充相關知識。
-
使用Markdown格式(推薦):PDF內容格式複雜,解析效果可能不佳,建議先轉成文字文件(Markdown/DOC/DOCX等)。例如,您可以使用阿里雲百鍊的DashScopeParse先將PDF轉成Markdown格式,然後再使用大模型整理格式,同樣可以取得不錯的效果。更多說明請參見阿里雲大模型ACP課程的 RAG 章節。
知識庫當前不支援文檔中視頻和音頻內容的解析。
-
內容表達清晰、結構合理、無特殊樣式:文檔的內容排版也會顯著影響 RAG 的效果,具體請參見文檔應如何格式化排版有利於RAG。
-
與提示詞語言一致:如果使用者的提示詞更多使用外語(例如英語),建議您的文檔內容也使用相應語言。如有必要(例如文檔中的專業術語),可進行雙語言或多語言處理。
-
消除實體歧義:對文檔中相同實體的表述進行統一。例如,“ML”、“Machine Learning”和“機器學習”可以統一規範為“機器學習”。
您可以嘗試將文檔輸入到大模型中,讓大模型來協助您統一規範(如果文檔較長,可先將其拆為多個部分,再逐一輸入)。
上述五項準備工作是保證接下來 RAG 最佳化效果的基礎。如果您已經做好準備,就可以著手深入瞭解並最佳化 RAG 應用的各個環節了。
2.2 解析與切片階段
本段落僅介紹在 RAG 的切片階段,阿里雲百鍊支援最佳化的配置項。
首先,您匯入知識庫的文檔會被解析和切片。切片的主要目的是在後續向量化過程中盡量減少幹擾資訊影響,同時保持語義的完整性。因此,您在建立知識庫時所選擇的文檔切分chunk策略會對 RAG 的效果產生很大影響。如果切片方式不當,可能會導致下述問題:
|
文本切片過短 |
文本切片過長 |
明顯的語義截斷 |
|
|
|
|
|
文本切片過短會出現語義缺失,導致檢索時無法匹配。 |
文本切片過長會包含不相關主題,導致召回時返回無關資訊。 |
文本切片出現了強制性的語義截斷,導致召回時缺失內容。 |



因此,在實際應用中,您應當盡量讓文本切片包含的資訊完整,同時避免包含過多的幹擾資訊。阿里雲百鍊建議您:
-
在建立知識庫時,文檔切分chunk選擇智能切分。
-
將文檔成功匯入知識庫後,對文本切片的內容進行人工檢查和修正。
2.2.1 智能切分
選擇適合您知識庫的文本切片長度並非易事,因為這必須考慮多種因素,例如:
-
文檔的類型:例如,對於專業類文獻,增加長度通常有助於保留更多上下文資訊;而對於社交類文章,縮短長度則能更準確地捕捉語義。
-
提示詞的複雜度:一般來說,如果使用者的提示詞較複雜且具體,則可能需要增加長度;反之,縮短長度會更為合適。
當然,上述結論並不一定適用於所有情況,您需要選擇合適的工具反覆實驗(例如LlamaIndex提供對不同切片方法的評估功能),才能找到合適的文本切片長度,但顯然這並非易事。
如果您希望在短時間內獲得良好的效果,建議您在建立知識庫時,文檔切分chunk選擇智能切分。

應用這一策略時,知識庫會:
-
首先利用系統內建的分句標識符將文檔劃分為若干段落。
-
基於劃分的段落,根據語義相關性自適應地選擇切片點進行切分(語義切分),而非根據固定長度進行切分。
在上述過程中,知識庫將努力確保文檔各部分的語義完整性,盡量避免不必要的劃分和切分。這一策略將應用於該知識庫中的所有文檔(包括後續匯入的文檔)。
2.2.2 修本文本切片內容
當然,在實際切片的過程中,仍然存在一定幾率會出現意外的切分,或者出現其它問題(例如文本中的空格有時切片後會被解析為%20)。

因此,阿里雲百鍊建議您在成功將文檔匯入知識庫後,進行一次人工檢查,以確認文本切片內容的語義完整性和正確性。如果發現意外的切分或其他解析錯誤,您可以直接編輯文本切片進行修正(儲存後,文本切片原有的內容將失效,新的內容將用於知識庫檢索)。
請注意,此處您只是修改了知識庫中的文本切片,並未修改您在資料管理(臨時儲存)中的原文檔或資料表。因此,後續再次匯入知識庫時,仍需您進行人工檢查和修正。
2.3 檢索召回階段
本段落僅介紹在檢索召回階段,阿里雲百鍊支援最佳化的配置項。
檢索召回階段面臨主要問題是:難以從知識庫眾多的文本切片中,找出與提示詞最相關且包含正確答案相關資訊的文本切片。在此基礎上進一步細化:
|
問題類型 |
改進策略 |
|
在多輪會話情境中,使用者輸入的提示詞有時可能不夠完整,或者存在歧義。 |
開啟多輪會話改寫,知識庫會自動將使用者的提示詞改寫為更完整的形式,從而更好地匹配知識。 |
|
知識庫中包含多個類別的文檔。希望在A類文檔中檢索時,召回結果中卻包含其他類別(比如B類)的文本切片。 |
建議為文檔添加標籤。知識庫檢索時,會先根據標籤篩選相關文檔。 僅文檔搜尋類知識庫支援為文檔添加標籤。 |
|
知識庫中有多篇結構內容相似的文檔,例如都包含“功能概述”。希望在A文檔的“功能概述”中檢索,召回結果中卻包含其他相似文檔中的資訊。 |
提取中繼資料。知識庫會在向量檢索前使用中繼資料進行結構化搜尋,從而精準找到目的文件並提取相關資訊。 僅文檔搜尋類知識庫支援建立文檔中繼資料。 |
|
知識庫的召回結果不完整,沒有包含全部相關的文本切片。 |
|
|
知識庫的召回結果中包含大量無關的文本切片。 |
建議提高相似性閾值,以排除與使用者提示詞相似性低的資訊。 |
2.3.1 多輪對話改寫
在多輪會話中,假設使用者某次使用了類似“阿里雲百鍊手機X1”這樣提示詞進行提問。看似簡短,卻可能導致 RAG 系統在檢索時缺乏必要的上下文資訊,原因是:
-
一款手機產品通常會有多個代際版本同時在售。
-
對於同一代產品,廠家通常會提供多種儲存容量選項,比如128GB、256GB等。
...
而這些關鍵資訊可能使用者在之前的會話中已經給出,如果能夠有效利用,將能夠協助 RAG 更準確地進行檢索。
針對這種情況,您可以使用阿里雲百鍊的多轮对话改写功能。系統會根據之前的會話,自動將使用者的提示詞改寫為更完整的形式。
比如使用者提問:
阿里雲百鍊手機X1。在啟用多輪對話改寫功能的情況下,系統會根據與該使用者此前的歷史會話,在檢索前對該使用者的提示詞進行改寫(僅樣本):
請提供產品庫中所有在售版本的阿里雲百鍊手機X1及其具體參數資訊。顯然,這樣改寫後的提示詞可以協助 RAG 更好地理解使用者的意圖,讓回答更加準確。
下圖為您展示了如何開啟多輪對話改寫功能(選擇圖中的推薦配置時,同樣也會開啟本功能)。

請注意,多輪對話改寫功能是與知識庫綁定的,開啟後僅對當前知識庫相關的查詢生效。且如果您在建立知識庫時未啟用該配置,則後續無法再為該知識庫開啟,除非重新建立知識庫。
2.3.2 標籤過濾
本段落內容僅適用於文檔搜尋類知識庫。
想象一下,您在使用一些音樂APP時,可能有時會通過歌手名稱來篩選歌曲,從而快速找到同一類(該歌手唱的)歌曲。
類似地,為您的非結構化文檔添加標籤可以引入額外的結構化資訊。這樣應用在檢索知識庫時,會先根據標籤篩選文檔,從而提升檢索的準確性和效率。
目前阿里雲百鍊支援以下兩種方式設定標籤:
-
在上傳文檔時設定標籤:控制台操作步驟請參見匯入資料。
-
在資料管理頁面編輯標籤:對於已上傳的文檔,可單擊文檔右側的标签進行編輯。


目前阿里雲百鍊支援以下兩種方式使用標籤:
-
通過API調用阿里雲百鍊應用時,可以在請求參數
tags中指定標籤。 -
在控制台編輯應用時設定標籤(但本方式僅適用於智能體應用)。
請注意,此處的設定將應用於該智能體應用後續的所有使用者問答。

2.3.3 提取中繼資料
本段落內容僅適用於文檔搜尋類知識庫。
將中繼資料嵌入文本切片,可以有效增強每個切片的上下文資訊。在特定情境下,這種方法能夠顯著提升文檔搜尋類知識庫的 RAG 效果。
假設以下情境:
某知識庫中有大量手機產品說明文檔,文檔名稱為手機的型號(比如阿里雲百鍊X1、阿里雲百鍊Zephyr Z9等),且所有文檔都包含「功能概述」章節。
當該知識庫未啟用中繼資料時,使用者輸入以下提示詞進行檢索:
阿里雲百鍊手機X1的功能概述。通過點擊測試,您可以查看檢索實際召回了哪些切片(如下圖所示)。由於所有文檔都包含“功能概述”,因此知識庫會召回一些與查詢實體(阿里雲百鍊手機X1)無關但和提示詞相似的文本切片(如下圖中的切片1、切片2),它們的排名甚至高於我們實際需要的文本切片。這顯然會影響到 RAG 的效果。
點擊測試的召回結果只保證排名,相似值的絕對值大小僅供參考。當絕對值的差別不大時(5%以內),可基本認為召回機率一樣。

接下來,我們將手機名稱,按照metadata抽取中提到的步驟,設定為中繼資料(相當於讓每篇文檔相關的文本切片帶上各自對應的手機名稱資訊),然後再進行一次相同的測試作為對比。

此時,知識庫會在向量檢索前增加一層結構化搜尋,完整過程如下:
-
從提示詞中提取中繼資料 {"key": "name", "value": "阿里雲百鍊手機X1"}。
-
根據提取的中繼資料,找到所有包含“阿里雲百鍊手機X1”中繼資料的文本切片。
-
再進行向量(語義)檢索,找到最相關的文本切片。
啟用中繼資料後的點擊測試實際召回效果如下圖所示。可以看到,知識庫此時已經可以精準找到與“阿里雲百鍊手機X1”相關且包含“功能概述”的文本切片。

除此以外,中繼資料的一個常見應用是在文本切片中嵌入日期資訊,以便過濾最近的內容。更多中繼資料用法,請參見metadata抽取。
2.3.4 調整相似性閾值
當知識庫找到和使用者提示詞相關的文本切片後,會先將它們發送給Rank模型(在建立知識庫的自訂參數設定中)進行重排序,而相似性閾值則用於篩選經過Rank模型重排序後返回的文本切片,只有相似性分數超過此閾值的文本切片才有可能被提供給大模型。

調低此閾值,預期可能會召回更多文本切片,但也可能導致召回一些相關度較低的文本切片;提高此閾值,可能會減少召回的文本切片。
若設定得過高(如下圖所示),則可能導致知識庫丟棄所有相關的文本切片,這將限制大模型擷取足夠背景資訊產生回答。

沒有最好的閾值,只有最適合您情境的閾值。您需要通過點擊測試反覆實驗不同的相似性閾值,觀察召回結果,找到最適合您需求的方案。
|
點擊測試建議步驟 |
|
|
|

2.3.5 提高召回片段數
召回片段數即多路召回策略中的K值。經過前面的相似性閾值過濾後,如果文本切片數量超過K,系統最終會選取相似性分數最高的 K 個文本切片提供給大模型。也正因為此,不合適的K值也可能會導致 RAG 漏掉正確的文本切片,從而影響大模型產生完整的回答。
比如下面的這個例子,使用者通過以下提示詞進行檢索:
阿里雲百鍊X1手機有什麼優勢?從下方示意圖可以看到,目標知識庫中實際與使用者提示詞相關,需要返回的文本切片總共有7個(下圖左側,已用綠色標出),但由於已經超出了當前設定的最大召回片段數K,因此包含優勢5(超長待機)和優勢6(拍照清晰)的文本切片被捨棄,沒有提供給大模型。
由於 RAG 本身無法判斷需要多少個文本切片才能給出“完整”的答案,因此即使最終提供的文本切片有遺漏,隨後大模型仍然會基於缺失的文本切片產生不完整的回答。
大量實驗結果表明:在諸如“列舉...”、“總結...”,“比較一下X、Y...”等情境中,提供更多高品質的文本切片(例如K=20)給大模型,比僅提供前10個或前5個文本切片效果更好。雖然這樣做可能會引入雜訊資訊,但如果文本切片品質較高的話,大模型通常能夠有效抵消雜訊資訊的影響。
您可以在編輯阿里雲百鍊應用時調整召回片段数。

請注意,召回片段數也並非越大越好。因為有時召回的文本切片在拼裝後,其總長度會超出大模型的輸入長度限制,導致部分文本切片被截斷,反而影響了 RAG 的效果。
因此,推薦您選擇智能拼装。這一策略會在不超過大模型最大輸入長度的前提下,儘可能多地為您召回相關的文本切片。
2.4 產生答案階段
本段落僅介紹在產生答案階段,阿里雲百鍊支援最佳化的配置項。
至此,大模型已經可以根據使用者的提示詞以及從知識庫檢索召回的內容,產生最終的回答。然而,返回結果有可能還是不及您的預期。
|
問題類型 |
改進策略 |
|
大模型並未理解知識和使用者提示詞之間的關係,感覺答案是生硬拼湊的。 |
建議選擇合適的大模型,從而有效地理解知識和使用者的提示詞之間的關係。 |
|
返回的結果沒有按照要求,或者不夠全面。 |
建議最佳化提示詞模板。 |
|
返回的結果不夠準確,其中包含了大模型自身的通用知識,並未完全基於知識庫。 |
建議開啟拒識,僅限於根據知識庫檢索到的知識回答。 |
|
相似的提示詞,希望每次返回的結果相同或不同。 |
建議調整大模型參數。 |
2.4.1 選擇合適的大模型
由於不同大模型在指令遵循、語言支援、長文本、知識理解等方面存在能力差異,可能導致:
模型A未能有效理解檢索到的知識與提示詞之間的關係,從而產生的答案無法準確回應使用者的提示詞。在更換為參數更多或者專業能力更強的模型B後,該問題可能就能得到解決。
您可以在編輯阿里雲百鍊應用時,根據實際需求选择模型。

您可以在編輯阿里雲百鍊應用時,根據實際需求选择模型。建議選擇千問的商業模型,例如千問Max、千問Plus等大模型。這些商業大模型相比開源版本,具備最新的能力和改進。
-
如果只是簡單的資訊查詢總結,小參數量的大模型足以滿足需求,例如
千問Turbo。 -
如果您希望RAG能完成較為複雜的邏輯推理,建議選擇參數量更大、推理能力更強的大模型,例如
千問Max。 -
如果您的問題需要查閱大量的文檔片段,建議選擇上下文長度更大的大模型,例如
千問Plus。 -
如果您構建的 RAG 應用面向一些非通用領域,例如法律領域,建議使用面向特定領域訓練的大模型,例如
通義法睿。
2.4.2 最佳化提示詞模板
我們知道,大模型本身是基於給定的文本來預測下一個Token的。這意味著您可以通過調整提示詞來影響大模型的行為(例如怎樣利用檢索到的知識等),間接提升 RAG 的效果。
以下為您介紹三種比較常見的最佳化方法:
方法一:對輸出的內容進行限定
您可以在提示詞模板中提供上下文資訊、指令以及預期的輸出形式,用於指示大模型完成任務。例如,您可以加入以下輸出指示要求大模型:
如果所提供的資訊不足以回答問題,請明確告知“根據現有資訊,我無法回答這個問題”。切勿編造答案。來減少大模型出現幻覺的幾率。
方法二:添加樣本
使用少樣本提示(Few-Shot Prompting)的方法,將希望大模型模仿的問答樣本添加到提示詞中,引導大模型正確利用檢索到的知識(下方樣本使用的是千問-Plus)。
|
提示詞模板 |
使用者提示詞和阿里雲百鍊應用返回的結果 |
|
|
|
|


方法三:新增內容分隔標記
檢索召回的文本切片如果隨意混雜在提示詞模板中,不利於大模型理解整個提示詞的結構。因此,建議您將提示詞和變數${documents}明確分開。
此外,為了保證效果,請確保您的提示詞模板中變數${documents}只出現一次(請參考下方左邊的正確樣本)。
|
正確樣本 |
錯誤樣本 |
|
|
瞭解更多提示詞最佳化方法,請參閱Prompt工程。
2.4.3 開啟拒識
如果您希望阿里雲百鍊應用返回的結果嚴格基於從知識庫中檢索到的知識,排除大模型自身通用知識的影響,您可以在編輯阿里雲百鍊應用時設定回答範圍為僅知識庫範圍。
對於在知識庫中找不到相關知識的情況,您還可以設定固定回複(自動)。
|
回答範圍:知识库+大模型知识 |
回答範圍:仅知识库范围 |
|
|
|
|
阿里雲百鍊應用返回的結果將綜合從知識庫中檢索到的知識和大模型自身的通用知識。 |
阿里雲百鍊應用返回的結果將嚴格基於從知識庫中檢索到的知識。 |


關於知識範圍判定,建議您選擇搜索阈值+大模型判断的方式。這一策略會先通過相似性閾值過濾潛在文本切片,再由一個大模型裁判,通過您設定的判斷Prompt對關聯度進行深入分析,從而進一步提高了判定的準確性。

以下是一個判斷Prompt的樣本,供您參考。此外,當在知識庫中未找到相關知識時,設定一個固定回複:抱歉,未找到相關的手機型號。
# 判斷規則:
- 問題和文檔匹配的前提是問題中涉及的實體與文檔描述的實體完全相同。
- 問題在文檔中完全沒有提到。|
使用者提示詞和阿里雲百鍊應用返回的結果(命中知識時) |
使用者提示詞和阿里雲百鍊應用返回的結果(未命中知識時) |
|
|
|


2.4.4 調整大模型參數
相似的提示詞,如果您希望每次返回的結果相同或不同,您可以在編輯阿里雲百鍊應用時,修改参数配置來調整大模型參數。

上圖中的溫度係數可以控制大模型產生內容的隨機性:溫度越高,產生的文本越多樣,反之,產生的文本越確定。
-
具有多樣性的文本,適用於創意寫作(如小說、廣告文案)、頭腦風暴、聊天應用等情境。
-
具有確定性文本,適用於有明確答案(如問題分析、選擇題、事實查詢)或要求用詞準確(如技術文檔、法律文本、新聞報道、學術論文)的情境。
其他兩個參數:
最長回複長度:此參數用於控制大模型產生的最多Token個數。如果您希望產生詳細的描述可以將該值調高;如果希望產生簡短的回答可以將該值調低。
攜帶上下文輪數:此參數用於控制大模型參考歷史對話的輪數,設為1時表示模型在回答時不會參考歷史對話資訊。
3. 常見問題
文檔內容排版建議
-
文檔的各級標題層次分明,各標題下的內容表達清晰。
-
文檔中盡量不要有浮水印。
-
列表中間的某一條之下盡量不要再分級。
-
文檔中盡量不要有表格和圖片(複雜表格會影響整體文檔解析結果)。
文檔標題層級不夠清晰-樣本
原文檔
一級標題為“四、獎品使用規則:”,內容有“獎品1:...”和“獎品2:...”。

處理後會出現的問題
將“獎品2:...”解析為“獎品1:...”的下一級標題。 建議將文檔中的“獎品1:...”以及“獎品2:...”設定為帶序號的二級標題。
文檔中有浮水印-樣本
原文檔
文檔帶有浮水印,總體內容有三條。

處理後會出現的問題
第三條會被分到一個chunk,但是由於浮水印部分被識別成文字,導致“(五)十一等耕地12萬元/畝”後會多出“政府公報”幾個字,並且由於“政府公報”的浮水印位置比較靠前,會導致(一)(二)(三)(四)(五)的順序被打亂,變成(一)(五)(三)(四)(二)。
列表中間的某一條之下再分級-樣本
原文檔
一級標題“活動規則”下是一個有序列表,其中的第3條“活動介紹”之下又是一個列表(分為a和b)。

處理後會出現的問題
一級標題“活動規則”下是一個有序列表,其中的第3條“活動介紹”之下又是一個列表。這會導致“活動介紹”被當成二級標題,其之後的所有內容被誤當成“活動介紹”二級標題之下的內容。 建議不要在列表之下再分級,如果需要盡量把需要分級的點放置在列表的最後一條。
一個比較好的樣本
-
各標題下內容相對獨立且清晰。
-
無浮水印。
-
標題之下是列表,但列表之下不再分級。
-
無表格、無圖片。
