千問-影像編輯模型支援多圖輸入和多圖輸出,可精確修改圖內文字、增刪或移動物體、改變主體動作、遷移圖片風格及增強畫面細節。
快速開始
本樣本將示範如何使用qwen-image-2.0-pro模型,根據3張輸入映像和提示詞,產生2張編輯後的映像。
輸入提示詞:圖1中的女生穿著圖2中的黑色裙子按圖3的姿勢坐下。
輸入映像1 | 輸入映像2 | 輸入映像3 | 輸出映像(多張映像) | |
|
|
|
|
|


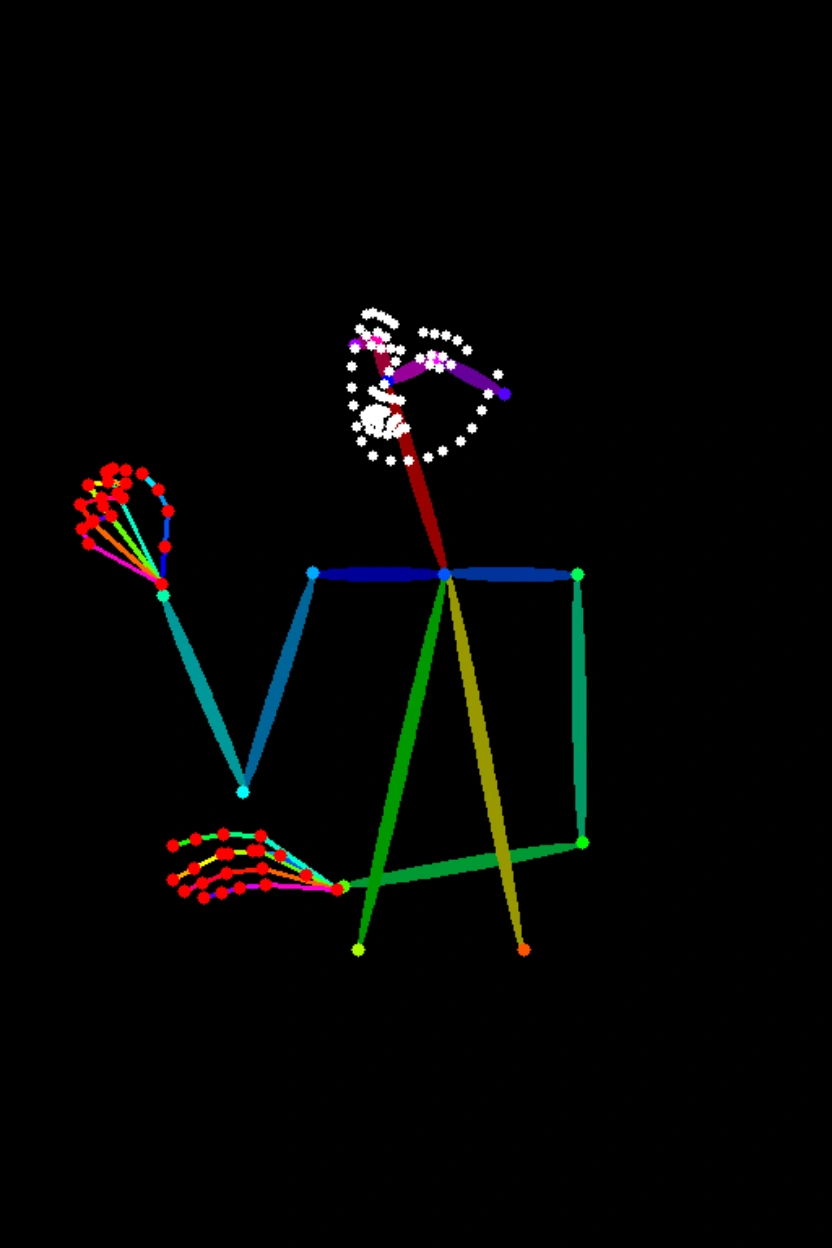


在調用前,您需要擷取API Key,再配置API Key到環境變數(準備下線,併入配置 API Key)。
如需通過SDK進行調用,請安裝DashScope SDK。目前,該SDK已支援Python和Java。
請將範例程式碼中的 DASHSCOPE_API_HOST 替換為擷取的 API Host。千問-影像編輯模型系列模型均支援傳入 1-3 張映像。其中,qwen-image-2.0系列、qwen-image-edit-max和qwen-image-edit-plus系列模型支援產生 1-6 張映像,qwen-image-edit 模型僅支援產生1張映像。產生的映像URL連結有效期間為24小時,請及時通過URL下載映像到本地。
Python
import json
import os
import dashscope
from dashscope import MultiModalConversation
# 以下為新加坡地區url,若使用北京地區的模型,需將url替換為:https://dashscope.aliyuncs.com/api/v1
dashscope.base_http_api_url = 'https://dashscope-intl.aliyuncs.com/api/v1'
# 模型支援輸入1-3張圖片
messages = [
{
"role": "user",
"content": [
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png"},
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png"},
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/gborgw/input3.png"},
{"text": "圖1中的女生穿著圖2中的黑色裙子按圖3的姿勢坐下"}
]
}
]
# 新加坡和北京地區的API Key不同。擷取API Key:https://www.alibabacloud.com/help/zh/model-studio/get-api-key
# 若沒有配置環境變數,請用百鍊API Key將下行替換為:api_key="sk-xxx"
api_key = os.getenv("DASHSCOPE_API_KEY")
# qwen-image-2.0系列、qwen-image-edit-max、qwen-image-edit-plus系列支援輸出1-6張圖片,此處以2張為例
response = MultiModalConversation.call(
api_key=api_key,
model="qwen-image-2.0-pro",
messages=messages,
stream=False,
n=2,
watermark=False,
negative_prompt=" ",
prompt_extend=True,
size="1024*1536",
)
if response.status_code == 200:
# 如需查看完整響應,請取消下行注釋
# print(json.dumps(response, ensure_ascii=False))
for i, content in enumerate(response.output.choices[0].message.content):
print(f"輸出映像{i+1}的URL:{content['image']}")
else:
print(f"HTTP返回碼:{response.status_code}")
print(f"錯誤碼:{response.code}")
print(f"錯誤資訊:{response.message}")
print("請參考文檔:https://www.alibabacloud.com/help/zh/model-studio/error-code")
Java
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.JsonUtils;
import com.alibaba.dashscope.utils.Constants;
import java.io.IOException;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.List;
public class QwenImageEdit {
static {
// 以下為新加坡地區url,若使用北京地區的模型,需將url替換為:https://dashscope.aliyuncs.com/api/v1
Constants.baseHttpApiUrl = "https://dashscope-intl.aliyuncs.com/api/v1";
}
// 新加坡和北京地區的API Key不同。擷取API Key:https://www.alibabacloud.com/help/zh/model-studio/get-api-key
// 若沒有配置環境變數,請用百鍊 API Key 將下行替換為:apiKey="sk-xxx"
static String apiKey = System.getenv("DASHSCOPE_API_KEY");
public static void call() throws ApiException, NoApiKeyException, UploadFileException, IOException {
MultiModalConversation conv = new MultiModalConversation();
// 模型支援輸入1-3張圖片
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(
Collections.singletonMap("image", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png"),
Collections.singletonMap("image", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png"),
Collections.singletonMap("image", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/gborgw/input3.png"),
Collections.singletonMap("text", "圖1中的女生穿著圖2中的黑色裙子按圖3的姿勢坐下")
)).build();
// qwen-image-2.0系列、qwen-image-edit-max、qwen-image-edit-plus系列支援輸出1-6張圖片,此處以2張為例
Map<String, Object> parameters = new HashMap<>();
parameters.put("watermark", false);
parameters.put("negative_prompt", " ");
parameters.put("n", 2);
parameters.put("prompt_extend", true);
parameters.put("size", "1024*1536");
MultiModalConversationParam param = MultiModalConversationParam.builder()
.apiKey(apiKey)
.model("qwen-image-edit-max")
.messages(Collections.singletonList(userMessage))
.parameters(parameters)
.build();
MultiModalConversationResult result = conv.call(param);
// 如需查看完整響應,請取消下行注釋
// System.out.println(JsonUtils.toJson(result));
List<Map<String, Object>> contentList = result.getOutput().getChoices().get(0).getMessage().getContent();
int imageIndex = 1;
for (Map<String, Object> content : contentList) {
if (content.containsKey("image")) {
System.out.println("輸出映像" + imageIndex + "的URL:" + content.get("image"));
imageIndex++;
}
}
}
public static void main(String[] args) {
try {
call();
} catch (ApiException | NoApiKeyException | UploadFileException | IOException e) {
System.out.println(e.getMessage());
}
}
}curl
以下為新加坡地區 URL ,若使用北京地區的模型,需將 URL 替換為:https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
curl --location 'https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation' \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--data '{
"model": "qwen-image-2.0-pro",
"input": {
"messages": [
{
"role": "user",
"content": [
{
"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png"
},
{
"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png"
},
{
"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/gborgw/input3.png"
},
{
"text": "圖1中的女生穿著圖2中的黑色裙子按圖3的姿勢坐下"
}
]
}
]
},
"parameters": {
"n": 2,
"negative_prompt": " ",
"prompt_extend": true,
"watermark": false,
"size": "1024*1536"
}
}'模型選型建議
qwen-image-2.0-pro系列(推薦):映像產生與編輯融合模型,文字渲染、真實質感、語義遵循能力更強。qwen-image-2.0系列:映像產生與編輯融合模型加速版,兼顧效果與效能。
各地區支援的模型請參見模型列表。
輸入說明
輸入映像(messages)
messages 是一個數組,且必須僅包含一個對象。該對象需包含 role 和 content 屬性。其中role必須設定為user,content需要同時包含image(1-3張映像)和text(一條編輯指令)。
輸入圖片必須滿足以下要求:
圖片格式:JPG、JPEG、PNG、BMP、TIFF、WEBP和GIF。
輸出映像為PNG格式,對於GIF動圖,僅處理其第一幀。
圖片解析度:為獲得最佳效果,建議映像的寬和高均在384像素至3072像素之間。解析度過低可能導致產生效果模糊,過高則會增加處理時間長度。
檔案大小:單張圖片檔案大小不得超過 10MB。
"messages": [
{
"role": "user",
"content": [
{ "image": "圖1的公網URL或Base64資料" },
{ "image": "圖2的公網URL或Base64資料" },
{ "image": "圖3的公網URL或Base64資料" },
{ "text": "您的編輯指令,例如:'圖1中的女生穿著圖2中的黑色裙子按圖3的姿勢坐下'" }
]
}
]映像輸入順序
多圖輸入時,按照數組順序定義映像順序,編輯指令需要與 content 中的映像順序對應(如“圖1”、“圖2”)。
輸入映像1 | 輸入映像2 | 輸出映像 | |
|
|
將圖1中女生的衣服替換為圖2中女生的衣服 |
將圖2中女生的衣服替換為圖1中女生的衣服 |




映像傳入方式
公網URL
提供一個公網可訪問的映像地址,支援 HTTP 或 HTTPS 協議。
樣本值:
https://xxxx/img.png。
Base64編碼
將影像檔轉換為 Base 64 編碼字串,並按格式拼接:data:{mime_type};base64,{base64_data}。
{mime_type}:映像的媒體類型,需與檔案格式對應。{base64_data}:檔案經過 Base 64 編碼後的字串。樣本值:
data:image/jpeg;base64,GDU7MtCZz...(樣本已截斷,僅做示範)
完整範例程式碼請參見Python SDK調用、Java SDK調用。
更多參數
可以通過以下可選參數調整產生效果:
n:指定輸出映像數量,預設值為1。qwen-image-2.0系列、qwen-image-edit-max和qwen-image-edit-plus系列模型支援輸出1-6張圖片,
qwen-image-edit模型僅支援輸出1張圖片。negative_prompt(反向提示詞):描述不希望在畫面中出現的內容,如“模糊”、“多餘的手指”等,用於輔助最佳化產生品質。
watermark:是否在映像右下角添加 "Qwen-Image" 浮水印。預設值為
false。浮水印樣式如下:
seed:隨機數種子。取值範圍是
[0, 2147483647]。如果不提供,則演算法自動產生一個隨機數作為種子。使用相同的 seed 值可協助產生內容保持相對穩定。
以下可選參數僅qwen-image-2.0系列、qwen-image-edit-max、qwen-image-edit-plus系列模型支援:
size:設定輸出映像的解析度,格式為
寬*高,例如"1024*2048"。對於qwen-image-2.0系列模型,支援自由設定寬高,輸出映像總像素需在512*512至2048*2048之間,預設解析度與輸入圖(多圖輸入時為最後一張圖)一致。對於qwen-image-edit-max、qwen-image-edit-plus系列模型,寬和高的取值範圍均為[512, 2048]像素,預設保持與原圖相似的長寬比,總像素接近1024*1024解析度。prompt_extend:是否開啟prompt智能改寫功能,預設值為
true。開啟後,模型將最佳化提示詞,對描述性不足、較為簡單的prompt提升效果較明顯。
完整參數列表請參考千問-影像編輯API。
效果概覽
多圖融合
輸入映像1 | 輸入映像2 | 輸入映像3 | 輸出映像 |
|
|
|
圖1中的女生戴著圖2中的項鏈,左肩挎著圖3中的包 |




主體一致性保持
輸入映像 | 輸出映像1 | 輸出映像2 | 輸出映像3 |
|
修改為藍底證件照,人物穿上白色襯衫,黑色西裝,打著條紋領帶 |
人物穿上白色襯衫,灰色西裝,打著條紋領帶,一隻手摸著領帶,淺色背景 |
人物穿著粗筆刷字型的“千問映像”的黑色衛衣,依靠在護欄邊,陽光照在髮絲上,身後是大橋和海 |
|
把這個空調放在客廳,沙發旁邊 |
在空調出風口增加霧氣,一直到沙發上,並且增加綠葉。 |
在上方增加白色的手寫體"自然新風 暢享呼吸" |








草圖創作
輸入映像 | 輸出映像 | |
|
產生一張映像,符合圖1所勾勒出的精緻形狀,並遵循以下描述:一位年輕的女子在陽光明媚的日子裡微笑著,她戴著一副棕色的圓形太陽鏡,鏡框上有豹紋圖案。她的頭髮被整齊地盤起,耳朵上佩戴著珍珠耳環,脖子上圍著一條帶有紫色星星圖案的深藍色圍巾,穿著一件黑色皮夾克。 |
產生一張映像,符合圖1所勾勒出的精緻形狀,並遵循以下描述:一位年老的老人朝著鏡頭微笑,他的臉上布滿皺紋,頭髮在風中淩亂,戴著一副圓框的老花鏡。脖子上戴著一條破舊的紅色圍巾,上面有星星圖案。穿著一件棉衣。 |



文創產生
輸入映像 | 輸出映像 | ||
|
讓這隻熊坐在月亮下(用白色背景上的淺灰彎月輪廓表示),抱著吉他,周圍漂浮著小星星和詩句氣泡,如“Be Kind”。 |
將這個圖案印在一件T恤和一個手提紙袋上。一個女模特正在展示這些物品。這個女生還戴著一頂鴨舌帽,帽子上寫著"Be kind”。 |
一個超逼真的1/7比例角色模型,設計為商業產品成品,放置在一台帶有白色拇指鍵盤的iMac電腦桌上。模型站在一個乾淨、圓形的透明亞克力底座上,沒有標籤或文字。專業的攝影棚燈光凸顯了雕刻細節。在背景的iMac螢幕上,展示同一模型的ZBrush建模過程。在模型旁邊,放置一個封裝盒,前面帶有透明窗戶,僅顯示內部透明塑料殼,其高度略高於模型,尺寸合理以容納模型。 |
這隻熊穿著宇航服,伸出手指向遠方 |
這隻熊穿著華麗的舞裙,雙臂展開,做出優雅的舞蹈動作 |
這隻熊穿著運動服,手裡拿著籃球,單腿彎曲 | |







根據深度圖產生映像
輸入映像 | 輸出映像 | |
|
產生一張映像,符合圖1所勾勒出的深度圖,並遵循以下描述:在一條街邊的小巷中停放著一輛藍色的單車,背景中有幾株從石縫中長出來的雜草 |
產生一張映像,符合圖1所勾勒出的深度圖,並遵循以下描述:一輛紅色的破舊的單車停在一條泥濘的小路上,背景是茂密的原始森林 |



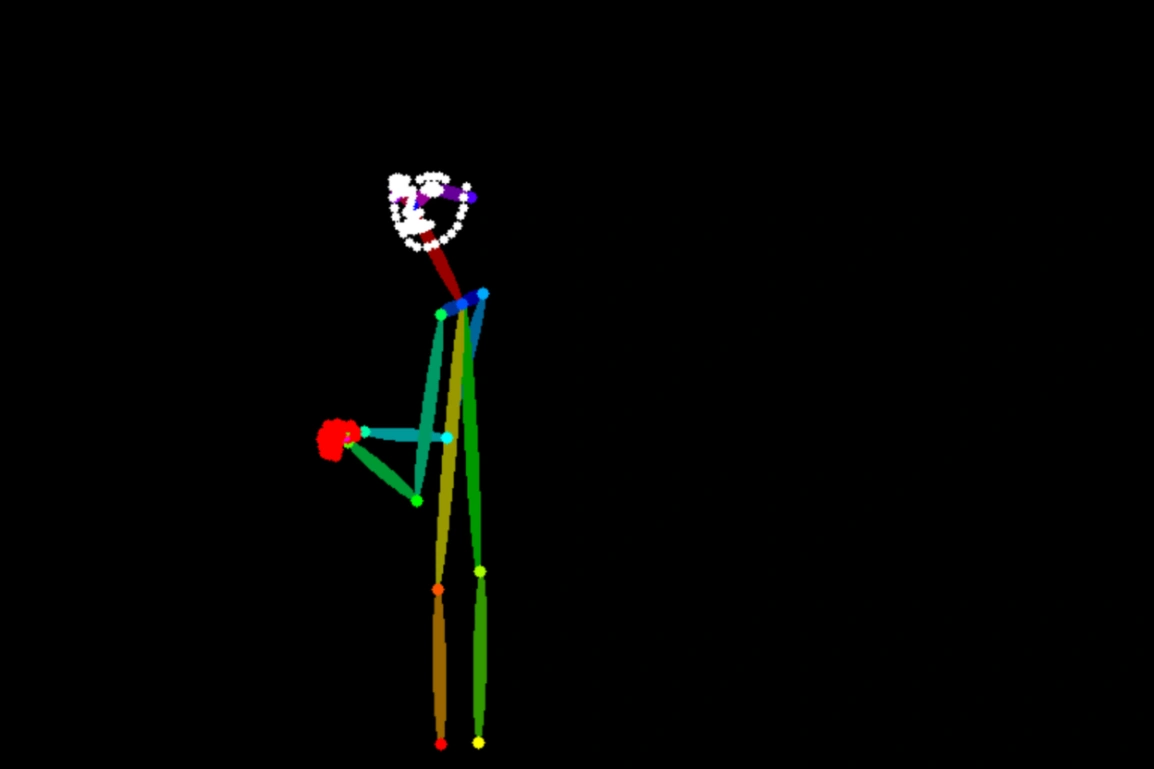
根據關鍵點產生映像
輸入映像 | 輸出映像 | |
|
產生一張映像,符合圖1所勾勒出的人體姿態,並遵循以下描述:一位身穿著漢服的中國美女,在雨中撐著油紙傘,背景是蘇州園林。 |
產生一張映像,符合圖1所勾勒出的人體姿態,並遵循以下描述:一位男生,站在地鐵月台上,他頭上戴著一頂棒球帽,穿著T恤和牛仔褲。背後是飛馳而過的列車。 |


文字編輯
輸入映像 | 輸出映像 | 輸入映像 | 輸出映像 |
|
將拼字遊戲方塊上'HEALTH INSURANCE’ 替換為'明天會更好' |
|
將便條上的短語“Take a Breather”更改為“Relax and Recharge” |




輸入映像 | 輸出映像 | ||
|
將“Qwen-Image”換成黑色的滴墨字型 |
將“Qwen-Image”換成黑色的手寫字型 |
將“Qwen-Image”換成黑色的像素字型 |
將“Qwen-Image”換成紅色 |
將“Qwen-Image”換成藍紫漸層色 |
將“Qwen-Image”換成糖果色 | |
將“Qwen-Image”材質換成金屬 |
將“Qwen-Image”材質換成雲朵 |
將“Qwen-Image”材質換成玻璃 | |










增刪改及替換
能力 | 輸入映像 | 輸出映像 |
新增元素 |
|
在企鵝前方添加一個小型木製標牌,上面寫著“Welcome to Penguin Beach”。 |
刪除元素 |
|
刪除餐盤上的頭髮 |
替換元素 |
|
把桃子變成蘋果 |
人像修改 |
|
讓她閉上眼睛 |
姿態修改 |
|
她舉起雙手,手掌朝向鏡頭,手指張開,做出一個俏皮的姿勢 |










視角轉換
輸入映像 | 輸出映像 | 輸入映像 | 輸出映像 |
|
獲得正視視角 |
|
朝向左側 |
|
獲得後側視角 |
|
朝向右側 |








背景替換
輸入映像 | 輸出映像 | |
|
將背景更改為海灘 |
將原圖背景替換為真實的現代教室情境,背景中央為一塊深綠色或墨黑色的傳統黑板,黑板表面用白色粉筆工整地寫著中文“千問” |



老照片處理
能力 | 輸入映像 | 輸出映像 |
老照片修複及上色 |
|
修複老照片,去除劃痕,降低噪點,增強細節,高解析度,畫面真實,膚色自然,面部特徵清晰,無變形。 |
|
根據內容智能上色,使映像更生動 |




計費與限流
模型免費額度和計費單價請參見模型列表與價格。
模型限流請參見千問(Qwen-Image)。
計費說明:
按成功產生的 映像張數 計費。模型調用失敗或處理錯誤不產生任何費用,也不消耗免費額度。
您可開啟“免費額度用完即停”功能,以避免免費額度耗盡後產生額外費用。詳情請參見免費額度。
API參考
API的輸入輸出參數,請參見千問-影像編輯。
錯誤碼
如果模型調用失敗並返回報錯資訊,請參見錯誤資訊進行解決。
常見問題
Q:千問影像編輯模型支援哪些語言?
A:目前正式支援簡體中文和英文;其他語言可自行嘗試,但效果存在不確定性。
Q: 如何查看模型調用量?
A: 模型調用完一小時後,請在 模型监控(新加坡)或模型监控(北京)頁面,查看模型的調用次數、成功率等指標。詳情請參見賬單查詢與成本管理。
Q:如何擷取映像儲存的訪問網域名稱白名單?
A: 模型產生的映像儲存於阿里雲OSS,API將返回一個臨時的公網URL。若需要對該下載地址進行防火牆白名單配置,請注意:由於底層儲存會根據業務情況進行動態變更,為避免到期資訊影響訪問,文檔不提供固定的OSS網域名稱白名單。如有安全管控需求,請聯絡客戶經理擷取最新OSS網域名稱列表。
更多問題請參見映像產生常見問題。