上下文緩衝(Context Cache)
調用大模型時,不同推理請求可能出現輸入內容的重疊(例如多輪對話或對同一本書的多次提問)。上下文緩衝(Context Cache)技術可以緩衝這些請求的公用首碼,減少推理時的重複計算。這能提升響應速度,並在不影響回複效果的前提下降低您的使用成本。
為滿足不同情境的需求,上下文緩衝提供兩種工作模式,可以根據對便捷性、確定性及成本的需求進行選擇:
顯式緩衝:需要主動開啟的緩衝模式。需要主動為指定內容建立緩衝,以在有效期間(5分鐘)內實現確定性命中。除了輸入 Token 計費,用於建立緩衝的 Token 按輸入 Token 標準單價的 125% 計費,後續命中僅需支付 10%的費用。
隱式緩衝:此為自動模式,無需額外配置,且無法關閉,適合追求便捷的通用情境。系統會自動識別請求內容的公用首碼並進行緩衝,但緩衝命中率不確定。對命中緩衝的部分,按輸入 Token 標準單價的 20% 計費。
專案 | 顯式緩衝 | 隱式緩衝 |
是否影響回複效果 | 不影響 | 不影響 |
用於建立緩衝Token計費 | 輸入 Token 單價的125% | 輸入 Token 單價的100% |
命中緩衝的輸入 Token 計費 | 輸入 Token 單價的10% | 輸入 Token 單價的20% |
緩衝最少 Token 數 | 1024 | 256 |
緩衝有效期間 | 5分鐘(命中後重設) | 不確定,系統會定期清理長期未使用的快取資料 |
顯式緩衝、隱式緩衝兩者互斥,單個請求只能應用其中一種模式。
預置吞吐(PTU)部署同樣支援上下文緩衝。命中緩衝時,PTU 額度消耗按緩衝折扣係數折算。詳見預置吞吐長輸入與緩衝。
本文內容適用 OpenAI Chat Completions 、 DashScope 與 Anthropic 相容介面。使用 Responses API 可通過 Session 緩衝降低推理延遲與成本,詳情參考Session 緩衝。
顯式緩衝
與隱式緩衝相比,顯式緩衝需要顯式建立並承擔相應開銷,但能實現更高的快取命中率和更低的訪問延遲。
使用方式
在 messages 中加入"cache_control": {"type": "ephemeral"}標記,系統將以每個cache_control標記位置為終點,向前回溯最多 20 個 content 塊,嘗試命中緩衝。
單次請求最多支援加入4 個快取標籤。
未命中緩衝
系統將從messages數組開頭到
cache_control標記之間的內容建立為新的緩衝塊,有效期間為 5 分鐘。緩衝建立發生在模型響應之後,建議在建立請求完成後再嘗試命中該緩衝。
緩衝塊的內容最少為 1024 Token。
命中緩衝
選取最長的匹配首碼作為命中的緩衝塊,並將該緩衝塊的有效期間重設為5分鐘。
以下樣本說明其使用方式:
發起第一個請求:發送包含超 1024 Token 文本 A 的系統訊息,並加入快取標籤:
[{"role": "system", "content": [{"type": "text", "text": A, "cache_control": {"type": "ephemeral"}}]}]系統將建立首個緩衝塊,記為 A 緩衝塊。
發起第二個請求:發送以下結構的請求:
[ {"role": "system", "content": A}, <其他 message> {"role": "user","content": [{"type": "text", "text": B, "cache_control": {"type": "ephemeral"}}]} ]若“其他message”不超過 20 條,則命中 A 緩衝塊,並將其有效期間重設為 5 分鐘;同時,系統會基於 A、其他message和 B 建立一個新的緩衝塊。
若“其他message”超過 20 條,則無法命中 A 緩衝塊,系統仍會基於完整上下文(A + 其他message + B)建立新緩衝塊。
支援的模型
新加坡
以下模型均為國際部署範圍。
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3.6-max-preview、qwen3-max
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus、qwen3.5-plus、qwen3.5-plus-2026-04-20、qwen-plus
千問 Flash:qwen3.6-flash、qwen3.5-flash、qwen-flash
千問 Coder:qwen3-coder-plus、qwen3-coder-flash
千問 VL:qwen3-vl-plus、qwen3-vl-flash
DeepSeek:deepseek-v3.2
Kimi:kimi-k2.7-code
美國(維吉尼亞)
以下模型均為美國部署範圍。
千問 Max:qwen3.7-max-us
華北2(北京)
以下模型均為中國內地部署範圍。
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3.6-max-preview、qwen3-max
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus、qwen3.5-plus、qwen3.5-plus-2026-04-20、qwen-plus
千問 Flash:qwen3.6-flash、qwen3.5-flash、qwen-flash
千問 Coder:qwen3-coder-plus、qwen3-coder-flash
千問 VL:qwen3-vl-plus、qwen3-vl-flash
DeepSeek:deepseek-v3.2
Kimi:kimi-k2.6、kimi-k2.5
GLM:glm-5.1
德國(法蘭克福)
不同服務部署範圍支援的模型不同。
全球服務部署範圍:
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus、qwen3.5-plus、qwen-plus
千問 Flash:qwen3.6-flash、qwen3.5-flash、qwen-flash
千問 VL:qwen3-vl-plus
千問 Coder:qwen3-coder-plus、qwen3-coder-flash
Kimi:kimi-k2.5
歐盟服務部署範圍:
千問 Max:qwen3-max
千問 Plus:qwen-plus
千問 Flash:qwen3.6-flash、qwen3.5-flash
千問 VL:qwen3-vl-plus
中國香港
不同服務部署範圍支援的模型不同。
全球服務部署範圍:
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus
千問 Flash:qwen3.6-flash
中國香港服務部署範圍:
千問 Max:qwen3-max
千問 Plus:qwen-plus
千問 Flash:qwen3.6-flash、qwen3.5-flash
千問 VL:qwen3-vl-plus
日本(東京)
不同服務部署範圍支援的模型不同。
日本服務部署範圍:
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26
全球服務部署範圍:
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen3.6-plus
千問 Flash:qwen3.6-flash
快速開始
以下樣本展示了在 OpenAI 相容、DashScope 和 Anthropic 相容協議中,緩衝塊的建立與命中機制。
OpenAI 相容
from openai import OpenAI
import os
client = OpenAI(
# 若沒有配置環境變數,請將下行替換為:api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 如果使用北京地區的模型,需要將base_url替換為:https://{WorkspaceId}.cn-beijing.maas.aliyuncs.com/compatible-mode/v1
base_url="https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1",
)
# 類比的代碼倉庫內容,最小可緩衝提示詞長度為 1024 Token
long_text_content = "<Your Code Here>" * 400
# 發起請求的函數
def get_completion(user_input):
messages = [
{
"role": "system",
"content": [
{
"type": "text",
"text": long_text_content,
# 在此處放置 cache_control 標記,將建立從 messages 數組的開頭到當前 content 所在位置的所有內容作為緩衝塊。
"cache_control": {"type": "ephemeral"},
}
],
},
# 每次的提問內容不同
{
"role": "user",
"content": user_input,
},
]
completion = client.chat.completions.create(
# 選擇支援顯式緩衝的模型
model="qwen3.7-max",
messages=messages,
)
return completion
# 第一次請求
first_completion = get_completion("這段代碼的內容是什麼")
print(f"第一次請求建立緩衝 Token:{first_completion.usage.prompt_tokens_details.cache_creation_input_tokens}")
print(f"第一次請求命中緩衝 Token:{first_completion.usage.prompt_tokens_details.cached_tokens}")
print("=" * 20)
# 第二次請求,代碼內容一致,只修改了提問問題
second_completion = get_completion("這段代碼可以怎麼最佳化")
print(f"第二次請求建立緩衝 Token:{second_completion.usage.prompt_tokens_details.cache_creation_input_tokens}")
print(f"第二次請求命中緩衝 Token:{second_completion.usage.prompt_tokens_details.cached_tokens}")DashScope
import os
from dashscope import Generation
# 以下為新加坡地區URL,調用時請將WorkspaceId替換為真實的業務空間ID,各地區的URL不同。
dashscope.base_http_api_url = "https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/api/v1"
# 類比的代碼倉庫內容,最小可緩衝提示詞長度為 1024 Token
long_text_content = "<Your Code Here>" * 400
# 發起請求的函數
def get_completion(user_input):
messages = [
{
"role": "system",
"content": [
{
"type": "text",
"text": long_text_content,
# 在此處放置 cache_control 標記,將建立從 messages 數組的開頭到當前 content 所在位置的所有內容作為緩衝塊。
"cache_control": {"type": "ephemeral"},
}
],
},
# 每次的提問內容不同
{
"role": "user",
"content": user_input,
},
]
response = Generation.call(
# 若沒有配置環境變數,請用阿里雲百鍊API Key將下行替換為:api_key = "sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen3.7-max",
messages=messages,
result_format="message"
)
return response
# 第一次請求
first_completion = get_completion("這段代碼的內容是什麼")
print(f"第一次請求建立緩衝 Token:{first_completion.usage.prompt_tokens_details['cache_creation_input_tokens']}")
print(f"第一次請求命中緩衝 Token:{first_completion.usage.prompt_tokens_details['cached_tokens']}")
print("=" * 20)
# 第二次請求,代碼內容一致,只修改了提問問題
second_completion = get_completion("這段代碼可以怎麼最佳化")
print(f"第二次請求建立緩衝 Token:{second_completion.usage.prompt_tokens_details['cache_creation_input_tokens']}")
print(f"第二次請求命中緩衝 Token:{second_completion.usage.prompt_tokens_details['cached_tokens']}")// Java SDK 最低版本為 2.21.6
import com.alibaba.dashscope.aigc.generation.Generation;
import com.alibaba.dashscope.aigc.generation.GenerationParam;
import com.alibaba.dashscope.aigc.generation.GenerationResult;
import com.alibaba.dashscope.common.Message;
import com.alibaba.dashscope.common.MessageContentText;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.InputRequiredException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import java.util.Arrays;
import java.util.Collections;
public class Main {
private static final String MODEL = "qwen3-coder-plus";
// 類比代碼倉庫內容(400次重複確保超過1024 Token)
private static final String LONG_TEXT_CONTENT = generateLongText(400);
private static String generateLongText(int repeatCount) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < repeatCount; i++) {
sb.append("<Your Code Here>");
}
return sb.toString();
}
private static GenerationResult getCompletion(String userQuestion)
throws NoApiKeyException, ApiException, InputRequiredException {
// 以下為新加坡地區URL,調用時請將WorkspaceId替換為真實的業務空間ID,各地區的URL不同。
Generation gen = new Generation("http", "https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/api/v1");
// 構建帶緩衝控制的系統訊息
MessageContentText systemContent = MessageContentText.builder()
.type("text")
.text(LONG_TEXT_CONTENT)
.cacheControl(MessageContentText.CacheControl.builder()
.type("ephemeral") // 設定緩衝類型
.build())
.build();
Message systemMsg = Message.builder()
.role(Role.SYSTEM.getValue())
.contents(Collections.singletonList(systemContent))
.build();
Message userMsg = Message.builder()
.role(Role.USER.getValue())
.content(userQuestion)
.build();
// 構建請求參數
GenerationParam param = GenerationParam.builder()
.model(MODEL)
.messages(Arrays.asList(systemMsg, userMsg))
.resultFormat(GenerationParam.ResultFormat.MESSAGE)
.build();
return gen.call(param);
}
private static void printCacheInfo(GenerationResult result, String requestLabel) {
System.out.printf("%s建立緩衝 Token: %d%n", requestLabel, result.getUsage().getPromptTokensDetails().getCacheCreationInputTokens());
System.out.printf("%s命中緩衝 Token: %d%n", requestLabel, result.getUsage().getPromptTokensDetails().getCachedTokens());
}
public static void main(String[] args) {
try {
// 第一次請求
GenerationResult firstResult = getCompletion("這段代碼的內容是什麼");
printCacheInfo(firstResult, "第一次請求");
System.out.println(new String(new char[20]).replace('\0', '=')); // 第二次請求
GenerationResult secondResult = getCompletion("這段代碼可以怎麼最佳化");
printCacheInfo(secondResult, "第二次請求");
} catch (NoApiKeyException | ApiException | InputRequiredException e) {
System.err.println("API調用失敗: " + e.getMessage());
e.printStackTrace();
}
}
}Anthropic 相容
import anthropic
import os
client = anthropic.Anthropic(
# 若沒有配置環境變數,請將下行替換為:api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 如果使用北京地區的模型,需要將base_url替換為:https://{WorkspaceId}.cn-beijing.maas.aliyuncs.com/apps/anthropic
base_url="https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/apps/anthropic",
)
# 類比的代碼倉庫內容,最小可緩衝提示詞長度為 1024 Token
long_text_content = "<Your Code Here>" * 400
# 發起請求的函數
def get_completion(user_input):
response = client.messages.create(
# 選擇支援顯式緩衝的模型
model="qwen3.7-max",
max_tokens=1024,
system=[
{
"type": "text",
"text": long_text_content,
# 在此處放置 cache_control 標記,將建立 system text內容作為緩衝塊,也可放置在messages訊息中
"cache_control": {"type": "ephemeral"},
}
],
messages=[
# 每次的提問內容不同
{"role": "user", "content": user_input},
],
)
return response
# 第一次請求
first_completion = get_completion("這段代碼的內容是什麼")
print(f"第一次請求建立緩衝 Token:{first_completion.usage.cache_creation_input_tokens}")
print(f"第一次請求命中緩衝 Token:{first_completion.usage.cache_read_input_tokens}")
print("=" * 20)
# 第二次請求,代碼內容一致,只修改了提問問題
second_completion = get_completion("這段代碼可以怎麼最佳化")
print(f"第二次請求建立緩衝 Token:{second_completion.usage.cache_creation_input_tokens}")
print(f"第二次請求命中緩衝 Token:{second_completion.usage.cache_read_input_tokens}")類比的代碼倉庫內容通過添加 cache_control標記啟用顯式緩衝。後續針對該代碼倉庫的提問請求,系統可複用該緩衝塊,無需重新計算,可獲得比建立緩衝前更快的響應與更低的成本。
第一次請求建立緩衝 Token:1605
第一次請求命中緩衝 Token:0
====================
第二次請求建立緩衝 Token:0
第二次請求命中緩衝 Token:1605使用多個快取標籤實現精細控制
在複雜情境中,提示詞通常由多個重用頻率不同的部分組成。使用多個快取標籤可實現精細控制。
例如,智能客服的提示詞通常包括:
系統人設:高度穩定,幾乎不變。
外部知識:半穩定,通過知識庫檢索或工具查詢獲得,可能在連續對話中保持不變。
對話歷史:動態增長。
當前問題:每次不同。
如果將整個提示詞作為一個整體緩衝,任何微小變化(如外部知識改變)都可能導致無法命中緩衝。
在請求中最多可設定四個快取標籤,為提示詞的不同部分分別建立緩衝塊,從而提升命中率並實現精細控制。
如何計費
顯式緩衝僅影響輸入 Token 的計費方式。規則如下:
建立緩衝:新建立的緩衝內容按標準輸入單價的 125% 計費。若新請求的緩衝內容包含已有緩衝作為首碼,則僅對新增部分計費(即新緩衝 Token 數減去已有緩衝 Token 數)。
例如:若已有 1200 Token 的緩衝 A,新請求需緩衝 1500 Token 的內容 AB,則前 1200 Token 按快取命中計費(標準單價的 10%),新增的 300 Token 按建立緩衝計費(標準單價的 125%)。
建立緩衝所用的 Token數通過
cache_creation_input_tokens參數查看。命中緩衝:按標準輸入單價的 10% 計費。
命中緩衝的 Token數通過
cached_tokens參數查看。其他 Token:未命中且未建立緩衝的 Token 按原價計費。
可緩衝內容
僅 messages 數組中的以下訊息類型支援添加快取標籤:
系統訊息(System Message)
說明若請求包含
tools參數(Function Calling 情境),工具定義會作為系統訊息的一部分參與緩衝計算。工具定義不支援獨立緩衝,在工具定義中添加快取標籤會被忽略,快取標籤只能添加在 messages 的 content 中。使用者訊息(User Message)
使用
qwen3-vl-plus模型建立緩衝時,cache_control標記可放置在多模態內容或文本之後,其位置不影響緩衝整個使用者訊息的效果。助手訊息(Assistant Message)
工具訊息(Tool Message,即工具執行後的結果)
以系統訊息為例,需將 content 欄位改為數組形式,並添加 cache_control 欄位:
{
"role": "system",
"content": [
{
"type": "text",
"text": "<指定的提示詞>",
"cache_control": {
"type": "ephemeral"
}
}
]
}此結構同樣適用於 messages 數組中的其他訊息類型。
緩衝限制
最小可緩衝提示詞長度為 1024 Token。
緩衝採用從後向前的首碼匹配策略,系統會自動檢查最近的 20 個 content 塊。若待匹配內容與帶有
cache_control標記的訊息之間間隔超過 20 個 content 塊,則無法命中緩衝。僅支援將
type設定為ephemeral,有效期間為 5 分鐘。單次請求最多可添加 4 個快取標籤。
若快取標籤個數大於4,則最後四個快取標籤生效。
提高 Function Calling 快取命中率
由於工具定義會被序列化為 JSON 字串參與緩衝計算,請確保每次請求的工具定義完全一致,以避免緩衝失效。具體需注意:
工具列表順序一致:tools 數組中各工具的排列順序需保持一致;
欄位順序一致:同一個 tool 的 JSON 欄位順序需保持一致;
欄位結構一致:不要遺漏或新增欄位,即使該欄位為空白或可選。
使用樣本
隱式緩衝
支援的模型
華北2(北京)
以下模型均為中國內地部署範圍。
文本產生模型
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max、qwen3-max-preview、qwen-max
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen-plus
千問 Flash:qwen-flash
千問 Turbo:qwen-turbo
千問 Coder:qwen3-coder-plus、qwen3-coder-flash
DeepSeek:deepseek-v4-pro、deepseek-v4-flash、deepseek-v3.2、deepseek-v3.1、deepseek-v3、deepseek-r1
Kimi:kimi-k2.6、kimi-k2.5、kimi-k2-thinking、Moonshot-Kimi-K2-Instruct
GLM:glm-5.2、glm-5.1、glm-5、glm-4.7、glm-4.6
MiniMax:MiniMax-M2.5
視覺理解模型
千問 VL:qwen3-vl-plus、qwen3-vl-flash、qwen-vl-max、qwen-vl-plus
新加坡
以下模型均為國際部署範圍。
文本產生模型
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max、qwen3-max-preview、qwen-max
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen-plus
千問 Flash:qwen-flash
千問 Turbo:qwen-turbo
千問 Coder:qwen3-coder-plus、qwen3-coder-flash
DeepSeek:deepseek-v4-pro、deepseek-v4-flash、deepseek-v3.2
GLM(阿里雲百鍊部署):glm-5.1
視覺理解模型
千問 VL:qwen3-vl-plus、qwen3-vl-flash、qwen-vl-max、qwen-vl-plus
美國(維吉尼亞)
不同服務部署範圍支援的模型不同。
全球服務部署範圍:
文本產生模型
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen-plus
千問 Flash:qwen-flash
千問 Coder:qwen3-coder-plus、qwen3-coder-flash
DeepSeek:deepseek-v4-pro、deepseek-v4-flash
Kimi(阿里雲百鍊部署):kimi-k2.5
GLM(阿里雲百鍊部署):glm-5.2
視覺理解模型
千問 VL:qwen3-vl-plus、qwen3-vl-flash
美國服務部署範圍:
文本產生模型
千問 Max:qwen3.7-max-us
千問 Plus:qwen-plus-us
千問 Flash:qwen-flash-us
視覺理解模型
千問 VL:qwen3-vl-flash-us
德國(法蘭克福)
不同服務部署範圍支援的模型不同。
全球服務部署範圍:
文本產生模型
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08、qwen3-max
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26、qwen-plus
千問 Flash:qwen-flash
千問 Coder:qwen3-coder-plus、qwen3-coder-flash
DeepSeek:deepseek-v4-pro、deepseek-v4-flash
Kimi(阿里雲百鍊部署):kimi-k2.5
GLM(阿里雲百鍊部署):glm-5.2
視覺理解模型
千問 VL:qwen3-vl-plus、qwen3-vl-flash
歐盟服務部署範圍:
文本產生模型
千問 Max:qwen3-max
千問 Plus:qwen-plus
視覺理解模型
千問 VL:qwen3-vl-plus、qwen3-vl-flash
中國香港
不同服務部署範圍支援的模型不同。
全球服務部署範圍:
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20、qwen3.7-max-2026-06-08
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26
GLM(阿里雲百鍊部署):glm-5.2
中國香港服務部署範圍:
本產生模型
千問 Max:qwen3-max
千問 Plus:qwen-plus
視覺理解模型
千問 VL:qwen3-vl-plus
日本(東京)
不同服務部署範圍支援的模型不同。
日本服務部署範圍:
文本產生模型
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26
DeepSeek(阿里雲百鍊部署):deepseek-v4-pro、deepseek-v4-flash
全球服務部署範圍:
文本產生模型
千問 Max:qwen3.7-max、qwen3.7-max-2026-05-20
千問 Plus:qwen3.7-plus、qwen3.7-plus-2026-05-26
DeepSeek(阿里雲百鍊部署):deepseek-v4-pro、deepseek-v4-flash
GLM(阿里雲百鍊部署):glm-5.1
Kimi(阿里雲百鍊部署):kimi-k2.5
工作方式
向支援隱式緩衝的模型發送請求時,該功能會自動開啟。系統的工作方式如下:
尋找:收到請求後,系統基於首碼匹配原則,檢查緩衝中是否存在請求中
messages數組內容的公用首碼。判斷:
若命中緩衝,系統直接使用緩衝結果進行後續部分的推理。
若未命中,系統按常規處理請求,並將本次提示詞的首碼存入緩衝,以備後續請求使用。
系統會定期清理長期未使用的快取資料。上下文快取命中機率並非100%,即使請求上下文完全一致,仍可能未命中,具體命中機率由系統判定。
qwen3.7-max系列觸發隱式緩衝的最少 Token 數約為1000,其他模型為256。
提升命中緩衝的機率
隱式緩衝的命中邏輯是判斷不同請求的首碼是否存在重複內容。為提高命中機率,請將重複內容置於提示詞開頭,差異內容置於末尾。
文本模型:假設系統已緩衝"ABCD",則請求"ABE"可能命中"AB"部分,而請求"BCD"則無法命中。
視覺理解模型:
對同一映像或視頻進行多次提問:將映像或視頻放在文本資訊前會提高命中機率。
對不同映像或視頻提問同一問題:將文本資訊放在映像或視頻前面會提高命中機率。
如何計費
開啟隱式緩衝模式無需額外付費。
當請求命中緩衝時,命中的輸入 Token 按 cached_token 計費,折扣比例因模型而有差異;未被命中的輸入 Token 按標準 input_token 計費。輸出 Token 仍按原價計費。
除 deepseek-v4-pro 外的模型:
cached_token單價為input_token單價的 20%deepseek-v4-pro:
cached_token單價不是input_token單價的 20%,具體價格請參見百鍊控制台
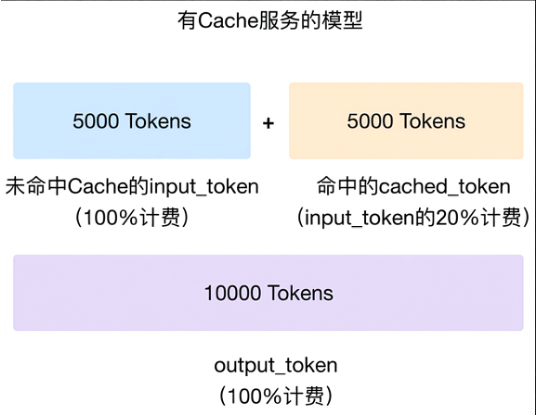
樣本:某請求包含 10,000 個輸入 Token,其中 5,000 個命中緩衝。費用計算如下:
未命中 Token (5,000):按 100% 單價計費
命中 Token (5,000):按 20% 單價計費
總輸入費用相當於無緩衝模式的 60%:(50% × 100%) + (50% × 20%) = 60%。
可從返回結果的cached_tokens屬性擷取命中緩衝的 Token 數。
OpenAI相容-Batch(檔案輸入)方式調用無法享受緩衝折扣。
命中緩衝的案例
文本產生模型
OpenAI相容
當您使用 OpenAI 相容的方式調用模型並觸發了隱式緩衝後,可以得到如下的返回結果,在usage.prompt_tokens_details.cached_tokens可以查看命中緩衝的 Token 數(該數值為usage.prompt_tokens的一部分)。
{
"choices": [
{
"message": {
"role": "assistant",
"content": "我是阿里雲開發的一款超大規模語言模型,我叫千問。"
},
"finish_reason": "stop",
"index": 0,
"logprobs": null
}
],
"object": "chat.completion",
"usage": {
"prompt_tokens": 3019,
"completion_tokens": 104,
"total_tokens": 3123,
"prompt_tokens_details": {
"cached_tokens": 2048
}
},
"created": 1735120033,
"system_fingerprint": null,
"model": "qwen-plus",
"id": "chatcmpl-6ada9ed2-7f33-9de2-8bb0-78bd4035025a"
}DashScope
當您使用DashScope Python SDK 或 HTTP 方式調用模型並觸發了隱式緩衝後,可以得到如下的返回結果,在usage.prompt_tokens_details.cached_tokens可以查看命中緩衝的 Token 數(該數值是 usage.input_tokens 的一部分。)。
{
"status_code": 200,
"request_id": "f3acaa33-e248-97bb-96d5-cbeed34699e1",
"code": "",
"message": "",
"output": {
"text": null,
"finish_reason": null,
"choices": [
{
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "我是一個來自阿里雲的大規模語言模型,我叫千問。我可以產生各種類型的文本,如文章、故事、詩歌、故事等,並能夠根據不同的情境和需求進行變換和擴充。此外,我還能夠回答各種問題,提供協助和解決方案。如果您有任何問題或需要協助,請隨時告訴我,我會儘力提供支援。請注意,連續重複相同的內容可能無法獲得更詳細的回覆,建議您提供更多具體資訊或變化提問方式以便我更好地理解您的需求。"
}
}
]
},
"usage": {
"input_tokens": 3019,
"output_tokens": 101,
"prompt_tokens_details": {
"cached_tokens": 2048
},
"total_tokens": 3120
}
}Anthropic 相容
當您使用 Anthropic 相容的方式調用模型並觸發了隱式緩衝後,命中緩衝的 Token 數通過 usage.cache_read_input_tokens 查看(該數值不計入 usage.input_tokens,而是單獨報告)。
{
"id": "msg_01XFDUDYJgAACzvnptvVoYEL",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "這段內容是重複的佔位文本"
}
],
"model": "qwen3.7-max",
"stop_reason": "end_turn",
"usage": {
"input_tokens": 82,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 1536,
"output_tokens": 14
}
}視覺理解模型
OpenAI相容
當您使用 OpenAI 相容的方式調用模型並觸發了隱式緩衝後,可以得到如下的返回結果,在usage.prompt_tokens_details.cached_tokens可以查看命中緩衝的 Token 數(該 Token 數是usage.prompt_tokens的一部分)。
{
"id": "chatcmpl-3f3bf7d0-b168-9637-a245-dd0f946c700f",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "這張映像展示了一位女性和一隻狗在海灘上互動的溫馨情境。女性穿著格子襯衫,坐在沙灘上,面帶微笑地與狗進行互動。狗是一隻大型的淺色犬種,戴著彩色的項圈,前爪抬起,似乎在與女性握手或擊掌。背景是廣闊的海洋和天空,陽光從畫面的右側照射過來,給整個情境增添了一種溫暖而寧靜的氛圍。",
"refusal": null,
"role": "assistant",
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1744956927,
"model": "qwen-vl-max",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": null,
"usage": {
"completion_tokens": 93,
"prompt_tokens": 1316,
"total_tokens": 1409,
"completion_tokens_details": null,
"prompt_tokens_details": {
"audio_tokens": null,
"cached_tokens": 1152
}
}
}DashScope
當您使用DashScope Python SDK 或 HTTP 方式調用模型並觸發了隱式緩衝後,命中緩衝的Token數包含在總輸入Token(usage.input_tokens)中,具體查看位置因地區和模型而異:
北京地區:
qwen-vl-max、qwen-vl-plus:在usage.prompt_tokens_details.cached_tokens查看qwen3-vl-plus、qwen3-vl-flash:在usage.prompt_tokens_details.cached_tokens查看
新加坡地區:所有模型均查看
usage.cached_tokens
目前使用usage.cached_tokens的模型,後續將升級至usage.prompt_tokens_details.cached_tokens。
{
"status_code": 200,
"request_id": "06a8f3bb-d871-9db4-857d-2c6eeac819bc",
"code": "",
"message": "",
"output": {
"text": null,
"finish_reason": null,
"choices": [
{
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": [
{
"text": "這張映像展示了一位女性和一隻狗在海灘上互動的溫馨情境。女性穿著格子襯衫,坐在沙灘上,面帶微笑地與狗進行互動。狗是一隻大型犬,戴著彩色項圈,前爪抬起,似乎在與女性握手或擊掌。背景是廣闊的海洋和天空,陽光從畫面右側照射過來,給整個情境增添了一種溫暖而寧靜的氛圍。"
}
]
}
}
]
},
"usage": {
"input_tokens": 1292,
"output_tokens": 87,
"input_tokens_details": {
"text_tokens": 43,
"image_tokens": 1249
},
"total_tokens": 1379,
"output_tokens_details": {
"text_tokens": 87
},
"image_tokens": 1249,
"cached_tokens": 1152
}
}Anthropic 相容
當您使用 Anthropic相容的方式調用視覺理解模型並觸發了隱式緩衝後,命中緩衝的 Token 數會體現在 usage.cache_read_input_tokens 欄位中(與文本產生模型一致)。
{
"id": "msg_01XFDUDYJgAACzvnptvVoYEL",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "這張圖片展示了一位女性和一隻狗在海灘上互動的溫馨情境。"
}
],
"model": "qwen-vl-max",
"stop_reason": "end_turn",
"usage": {
"input_tokens": 369,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 896,
"output_tokens": 28
}
}典型情境
如果您的不同請求有著相同的首碼資訊,上下文緩衝可以有效提升這些請求的推理速度,降低推理成本與首包延遲。以下是幾個典型的應用情境:
基於長文本的問答
適用於需要針對固定的長文本(如小說、教材、法律檔案等)發送多次請求的業務情境。
第一次請求的訊息數組
messages = [{"role": "system","content": "你是一個語文老師,你可以協助學生進行閱讀理解。"}, {"role": "user","content": "<文章內容> 這篇課文表達了作者怎樣的思想感情?"}]之後請求的訊息數組
messages = [{"role": "system","content": "你是一個語文老師,你可以協助學生進行閱讀理解。"}, {"role": "user","content": "<文章內容> 請賞析這篇課文的第三自然段。"}]雖然提問的問題不同,但都基於同一篇文章。相同的系統提示和文章內容構成了大量重複的首碼資訊,有較大機率命中緩衝。
代碼自動補全
在代碼自動補全情境,大模型會結合上下文中存在的代碼進行代碼自動補全。隨著使用者的持續編碼,代碼的首碼部分會保持不變。上下文緩衝可以緩衝之前的代碼,提升補全速度。
多輪對話
實現多輪對話需要將每一輪的對話資訊添加到 messages 數組中,因此每輪對話的請求都會存在與前輪對話首碼相同的情況,有較高機率命中緩衝。
第一輪對話的訊息數組
messages=[{"role": "system","content": "You are a helpful assistant."}, {"role": "user","content": "你是誰?"}]第二輪對話的訊息數組
messages=[{"role": "system","content": "You are a helpful assistant."}, {"role": "user","content": "你是誰?"}, {"role": "assistant","content": "我是由阿里雲開發的千問。"}, {"role": "user","content": "你能幹什嗎?"}]隨著對話輪數的增加,緩衝帶來的推理速度優勢與成本優勢會更明顯。
角色扮演或 Few Shot
在角色扮演或 Few-shot 學習的情境中,您通常需要在提示詞中加入大量資訊來指引大模型的輸出格式,這樣不同的請求之間會有大量重複的首碼資訊。
以讓大模型扮演營銷專家為例,System prompt包含有大量文本資訊,以下是兩次請求的訊息樣本:
system_prompt = """你是一位經驗豐富的營銷專家。請針對不同產品提供詳細的營銷建議,格式如下: 1. 目標受眾:xxx 2. 主要賣點:xxx 3. 營銷渠道:xxx ... 12. 長期發展策略:xxx 請確保你的建議具體、可操作,並與產品特性高度相關。""" # 第一次請求的user message 提問關於智能手錶 messages_1=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": "請為一款新上市的智能手錶提供營銷建議。"} ] # 第二次請求的user message 提問關於膝上型電腦,由於system_prompt相同,有較大機率命中 Cache messages_2=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": "請為一款新上市的膝上型電腦提供營銷建議。"} ]使用上下文緩衝後,即使使用者頻繁更換詢問的產品類型(如從智能手錶到膝上型電腦),系統也可以在觸發緩衝後快速響應。
視頻理解
在視頻理解情境中,如果對同一個視頻提問多次,將
video放在text前會提高命中緩衝的機率;如果對不同的視頻提問相同的問題,則將text放在video前面,會提高命中緩衝的機率。以下是對同一個視頻請求兩次的訊息樣本:# 第一次請求的user message 提問這段視頻的內容 messages1 = [ {"role":"system","content":[{"text": "You are a helpful assistant."}]}, {"role": "user", "content": [ {"video": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250328/eepdcq/phase_change_480p.mov"}, {"text": "這段視頻的內容是什麼?"} ] } ] # 第二次請求的user message 提問關於視頻時間戳記相關的問題,由於基於同一個視頻進行提問,將video放在text前面,有較大機率命中 Cache messages2 = [ {"role":"system","content":[{"text": "You are a helpful assistant."}]}, {"role": "user", "content": [ {"video": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250328/eepdcq/phase_change_480p.mov"}, {"text": "請你描述下視頻中的一系列活動事件,以JSON格式輸出開始時間(start_time)、結束時間(end_time)、事件(event),不要輸出```json```程式碼片段"} ] } ]
常見問題
Q:如何關閉隱式緩衝?
A:無法關閉。隱式緩衝對所有適用模型請求開啟的前提是對回複效果沒有影響,且在命中緩衝時降低使用成本,提升響應速度。
Q:為什麼建立顯式緩衝後沒有命中?
A:有以下可能原因:
建立後 5 分鐘內未被命中,超過有效期間系統將清理該緩衝塊;
最後一個
content與已存在的緩衝塊的間隔大於20個content塊時,不會命中緩衝,建議建立新的緩衝塊。
Q:顯式快取命中後,是否會重設有效期間?
A:是的,每次命中都會將該緩衝塊的有效期間重設為5分鐘。
Q:不同帳號之間的顯式緩衝是否會共用?
A:不會。無論是隱式緩衝還是顯式緩衝,資料都在帳號層級隔離,不會共用。
Q:相同帳號使用不同模型顯式緩衝是否會共用?
A:不會。快取資料存在模型間隔離,不會共用。
Q:為什麼usage的input_tokens不等於cache_creation_input_tokens和cached_tokens的總和?
A:為了確保模型輸出效果,後端服務會在使用者提供的提示詞之後追加少量 Token(通常在10以內),這些 Token 在 cache_control 標記之後,因此不會被計入緩衝的建立或讀取,但會計入總的 input_tokens。