本文介紹Parquet格式的OSS外部表格的建立、讀取及寫入方法。
適用範圍
-
OSS外部表格不支援cluster屬性。
-
單個檔案大小不能超過2GB,如果檔案過大,建議拆分。
-
MaxCompute需要與OSS部署在同一地區。
支援資料類型
MaxCompute資料類型詳情請參見1.0資料類型版本、2.0資料類型版本。
-
JNI模式:
set odps.ext.parquet.native=false,表示讀外部表格解析Parquet資料檔案時,使用原有基於Java的開源社區實現,支援讀和寫。 -
Native模式:
set odps.ext.parquet.native=true,表示讀外部表格解析Parquet資料檔案時,使用新的基於C++的Native實現,僅支援讀。模式
Java模式(讀寫)
Native模式(唯讀)
TINYINT
SMALLINT
INT
BIGINT
BINARY
FLOAT
DOUBLE
DECIMAL(precision,scale)
VARCHAR(n)
CHAR(n)
STRING
DATE
DATETIME
TIMESTAMP
TIMESTAMP_NTZ
BOOLEAN
ARRAY
MAP
STRUCT
JSON
支援壓縮格式
-
當讀寫壓縮屬性的OSS檔案時,需要在建表語句中添加
with serdeproperties屬性配置,詳情請參見with serdeproperties屬性參數。 -
支援讀寫的資料檔案格式:以ZSTD、SNAPPY、GZIP方式壓縮的Parquet。
支援Schema Evolution
Parquet外部表格的Schema和檔案列之間按名稱映射列值。
下表中的資料相容問題說明是指:已經進行Schema Evolution操作後的外表,針對“符合修改後的Schema結構的資料”是否可以正常讀取;針對於“存量舊Schema資料”(即和修改後schema不匹配的存量資料)是否可以正常讀取。
|
操作類型 |
是否支援 |
說明 |
資料相容問題說明 |
|
添加列 |
|
|
|
|
刪除列 |
|
Parquet外表的Schema和檔案列之間按名稱映射列值。 |
相容 |
|
修改列順序 |
|
Parquet外表的Schema和檔案列之間按名稱映射列值。 |
相容 |
|
更改列資料類型 |
|
不支援此操作,Parquet格式本身Schema校正非常嚴格,所以原來相容的類型修改後可能無法讀取。 |
不涉及 |
|
修改列名 |
|
不支援此操作,Parquet格式本身Schema校正非常嚴格,所以原來相容的類型修改後可能無法讀取。 |
不涉及 |
|
修改列注釋 |
|
注釋內容為長度不超過1024位元組的有效字串,否則報錯。 |
相容 |
|
修改列的非空屬性 |
|
不支援此操作,預設為Nullable。 |
不涉及 |
建立外部表格
文法結構
當Parquet檔案中的Schema與外表Schema不一致時:
-
列數不一致:如果Parquet檔案中的列數小於外表DDL的列數,則讀取Parquet資料時,系統會將缺少的列值補充為NULL。反之(大於時),會丟棄超出的列資料。
-
列類型不一致:如果Parquet檔案中的列類型與外表DDL中對應的列類型不一致,則讀取Parquet資料時會報錯。例如:使用STRING(或INT)類型接收Parquet檔案中INT(或STRING)類型的資料,報錯
ODPS-0123131:User defined function exception - Traceback:xxx。
精簡文法結構
CREATE EXTERNAL TABLE [IF NOT EXISTS] <mc_oss_extable_name>
(
<col_name> <data_type>,
...
)
[COMMENT <table_comment>]
[PARTITIONED BY (<col_name> <data_type>, ...)]
STORED AS parquet
LOCATION '<oss_location>'
[tblproperties ('<tbproperty_name>'='<tbproperty_value>',...)];詳細文法結構
CREATE EXTERNAL TABLE [IF NOT EXISTS] <mc_oss_extable_name>
(
<col_name> <data_type>,
...
)
[COMMENT <table_comment>]
[PARTITIONED BY (<col_name> <data_type>, ...)]
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH serdeproperties(
'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole',
'mcfed.parquet.compression'='ZSTD/SNAPPY/GZIP'
)
STORED AS parquet
LOCATION '<oss_location>'
;公用參數
公用參數說明請參見基礎文法參數說明。
獨有參數
with serdeproperties屬性參數
|
property_name |
使用情境 |
說明 |
property_value |
預設值 |
|
mcfed.parquet.compression |
當需要將Parquet資料以壓縮方式寫入OSS時,請添加該屬性。 |
Parquet壓縮屬性。Parquet資料預設不壓縮。 |
|
無 |
|
mcfed.parquet.compression.codec.zstd.level |
當 |
level值越大,壓縮比越高,實測取值高時,寫出資料的減少量非常有限,但時間和資源消耗快速增加,性價比明顯降低,因此對於巨量資料讀寫壓縮Parquet檔案的情境,低level(level3~level5)的zstd壓縮效果最好。例如: |
取值範圍為1~22。 |
3 |
|
parquet.file.cache.size |
在處理Parquet資料情境中,如果需要提升讀OSS資料檔案效能,請添加該屬性。 |
指定讀OSS資料檔案時,可快取的資料量,單位為KB。 |
1024 |
無 |
|
parquet.io.buffer.size |
在處理Parquet資料情境中,如果需要提升讀OSS資料檔案效能,請添加該屬性。 |
指定OSS資料檔案大小超過1024 KB時,可快取的資料量,單位為KB。 |
4096 |
無 |
tblproperties屬性參數
|
property_name |
使用情境 |
說明 |
property_value |
預設值 |
|
io.compression.codecs |
當OSS資料檔案為Raw-Snappy格式時,請添加該屬性。 |
內建的開來源資料解析器支援SNAPPY格式情境。 配置該參數值為True時,MaxCompute才可以正常讀取壓縮資料,否則MaxCompute無法成功讀取資料。 |
com.aliyun.odps.io.compress.SnappyRawCodec。 |
無 |
|
odps.external.data.output.prefix (相容odps.external.data.prefix) |
當需要添加輸出檔案的自訂首碼名時,請添加該屬性。 |
|
合格字元組合,例如'mc_'。 |
無 |
|
odps.external.data.enable.extension |
當需要顯示輸出檔案的副檔名時,請添加該屬性。 |
True表示顯示輸出檔案的副檔名,反之不顯示副檔名。 |
|
False |
|
odps.external.data.output.suffix |
當需要添加輸出檔案的自訂尾碼名時,請添加該屬性。 |
僅包含數字,字母,底線(a-z, A-Z, 0-9, _)。 |
合格字元組合,例如'_hangzhou'。 |
無 |
|
odps.external.data.output.explicit.extension |
當需要添加輸出檔案的自訂副檔名時,請添加該屬性。 |
|
合格字元組合,例如"jsonl"。 |
無 |
|
mcfed.parquet.compression |
當需要將Parquet資料以壓縮方式寫入OSS時,請添加該屬性。 |
Parquet壓縮屬性。Parquet資料預設不壓縮。 |
|
無 |
|
mcfed.parquet.block.size |
控制Parquet檔案的塊大小,影響儲存效率和讀取效能。 |
Parquet調優屬性。定義Parquet塊大小,以位元組為單位。 |
非負整數 |
134217728 (128MB) |
|
mcfed.parquet.block.row.count.limit |
當向Parquet外部表格寫入資料時,限制每個行組中的記錄數,避免記憶體溢出。 |
Parquet調優屬性。控制每行組(row group)的最大記錄數。如果出現OOM的情況,可將參數適當調小。 參數使用建議:
|
非負整數 |
2147483647 (Integer.MAX_VALUE) |
|
mcfed.parquet.page.size.row.check.min |
當向Parquet外部表格寫入資料時,控制記憶體檢查的頻率,防止記憶體溢出。 |
Parquet調優屬性。限制記憶體檢查之間的最小記錄數。如果出現OOM的情況,可將參數適當調小。 |
非負整數 |
100 |
|
mcfed.parquet.page.size.row.check.max |
當向Parquet外部表格寫入資料時,控制記憶體檢查的頻率,防止記憶體溢出。 |
Parquet調優屬性。限制記憶體檢查之間的最小記錄數。如果出現OOM的情況,可將參數適當調小。 由於需要對記憶體使用量情況進行頻繁計算,該參數調整可能會帶來額外開銷。 參數使用建議:
|
非負整數 |
1000 |
|
mcfed.parquet.compression.codec.zstd.level |
當需要將Parquet資料以ZSTD的壓縮形式寫入OSS,指定ZSTD壓縮演算法的壓縮層級時,請添加該屬性。 |
Parquet壓縮屬性。指ZSTD壓縮演算法的壓縮層級。取值範圍:1~22。 |
非負整數 |
3 |
寫入資料
MaxCompute寫入文法詳情,請參見寫入文法說明。
查詢分析
SELECT文法詳情,請參見查詢文法說明。
最佳化查詢計劃詳情,請參見查詢最佳化。
-
若需要直讀LOCATION檔案,請參見特色功能:Schemaless Query。
-
查詢最佳化:Parquet外部表格支援通過開啟PPD(即Predicate Push Down)實現查詢最佳化。最佳化效能結果參見支援Predicate Push Down(Parquet PPD)。
在SQL前添加如下參數開啟PPD:
-- PPD參數需在Native模式下使用,即Native開關需為true。 -- 開啟parquet native reader。 SET odps.ext.parquet.native = true; -- 開啟parquet ppd。 SET odps.sql.parquet.use.predicate.pushdown = true;
支援Predicate Push Down(Parquet PPD)
Parquet外部表格本身不支援Predicate Push Down(Parquet PPD),執行帶有WHERE過濾條件的查詢時,MaxCompute預設會掃描所有資料,導致不必要的I/O、資源消耗和查詢延遲。因此,MaxCompute新增了ParquetPDD參數,通過開啟Parquet PDD,可在資料掃描階段利用Parquet檔案自身的中繼資料特性實現Parquet RowGroup層級的過濾,從而提升查詢效能、降低資源消耗與成本。
使用方式
-
開啟Predicate Push Down(Parquet PPD)
執行SQL查詢前,通過
set命令設定以下兩個Session層級的參數以開啟Parquet PDD。-- 開啟parquet native reader。 set odps.ext.parquet.native = true; -- 開啟parquet ppd。 set odps.sql.parquet.use.predicate.pushdown = true; -
使用樣本
基於1TB的TPCDS測試資料集,以
tpcds_1t_store_salesParquet外部表格為例,開啟PPD並執行過濾查詢,總資料量為2879987999。-- 建立外部表格tpcds_1t_store_sales。 CREATE EXTERNAL TABLE IF NOT EXISTS tpcds_1t_store_sales ( ss_sold_date_sk BIGINT, ss_sold_time_sk BIGINT, ss_item_sk BIGINT, ss_customer_sk BIGINT, ss_cdemo_sk BIGINT, ss_hdemo_sk BIGINT, ss_addr_sk BIGINT, ss_store_sk BIGINT, ss_promo_sk BIGINT, ss_ticket_number BIGINT, ss_quantity BIGINT, ss_wholesale_cost DECIMAL(7,2), ss_list_price DECIMAL(7,2), ss_sales_price DECIMAL(7,2), ss_ext_discount_amt DECIMAL(7,2), ss_ext_sales_price DECIMAL(7,2), ss_ext_wholesale_cost DECIMAL(7,2), ss_ext_list_price DECIMAL(7,2), ss_ext_tax DECIMAL(7,2), ss_coupon_amt DECIMAL(7,2), ss_net_paid DECIMAL(7,2), ss_net_paid_inc_tax DECIMAL(7,2), ss_net_profit DECIMAL(7,2) ) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH serdeproperties( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole', 'mcfed.parquet.compression'='zstd' ) STORED AS parquet LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss_bucket_path/'; -- 使用1TB的TPCDS測試資料集。 INSERT OVERWRITE TABLE tpcds_1t_store_sales SELECT ss_sold_date_sk, ss_sold_time_sk, ss_item_sk, ss_customer_sk, ss_cdemo_sk, ss_hdemo_sk, ss_addr_sk, ss_store_sk, ss_promo_sk, ss_ticket_number, ss_quantity, ss_wholesale_cost, ss_list_price, ss_sales_price, ss_ext_discount_amt, ss_ext_sales_price, ss_ext_wholesale_cost, ss_ext_list_price, ss_ext_tax, ss_coupon_amt, ss_net_paid, ss_net_paid_inc_tax, ss_net_profit FROM bigdata_public_dataset.tpcds_1t.store_sales; -- 執行查詢。 SELECT SUM(ss_sold_date_sk) FROM tpcds_1t_store_sales WHERE ss_sold_date_sk >= 2451871 AND ss_sold_date_sk <= 2451880;
效能對比結果
開啟PPD功能可減少資料掃描量,從而降低查詢延遲和資源消耗。
|
模式 |
表總資料量 |
掃描條數 |
掃描Bytes |
Mapper耗時 |
總資源消耗 |
說明 |
|
Parquet外表+未開啟PPD |
2879987999 |
2879987999(100%) |
19386793984(100%) |
18s |
cpu 19.25 Core * Min, memory 24.07 GB * Min 100% |
|
|
Parquet外表+開啟PPD |
2879987999 |
762366649(26.47%) |
3339386880(17.22%) |
12s |
cpu 11.47 Core * Min, memory 14.33 GB * Min ~59.58% |
降低掃描資料量後,延遲和資源消耗降低很明顯 |
|
內表+開啟PPD |
2879987999 |
32830000(1.14%) |
1633880386(8.43%) |
9s |
cpu 5.62 Core * Min, memory 7.02 GB * Min ~29.19% |
內表資料有排序,因此PPD效果更加極致 |
測試詳情
-
Parquet外表+未開啟PPD
SET odps.ext.parquet.native = true; SET odps.sql.parquet.use.predicate.pushdown = false; SELECT SUM(ss_sold_date_sk) FROM tpcds_1t_store_sales WHERE ss_store_sk = 2 AND ss_sold_date_sk >= 2451871 AND ss_sold_date_sk <= 2451880;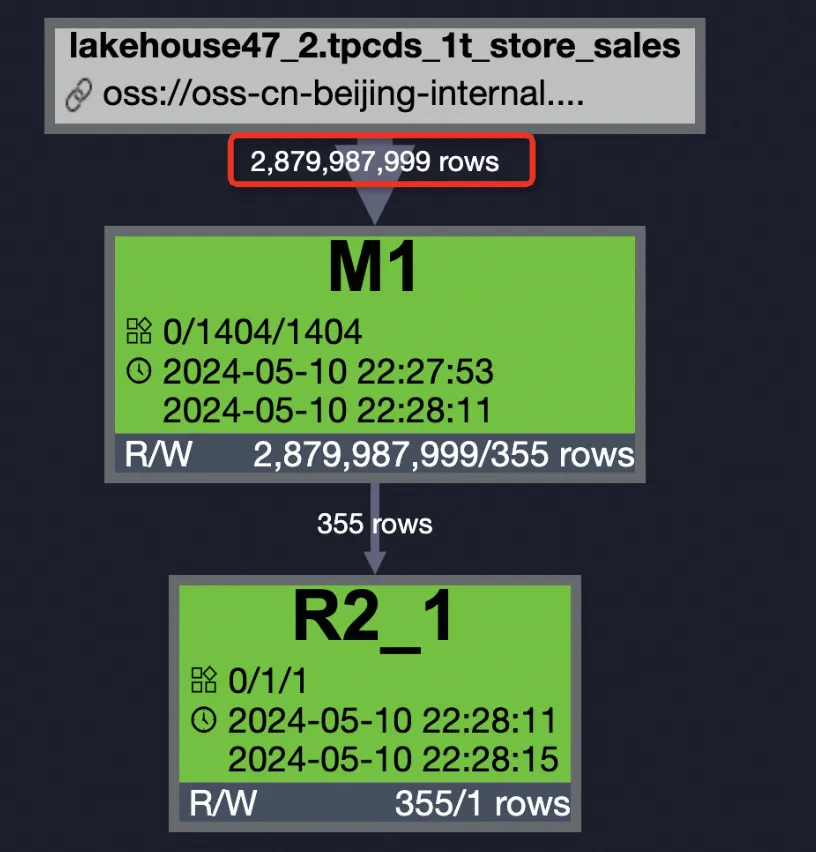
執行結果顯示,Fuxi Jobs 中 M1 任務的 IO Records Input 為 2.9 G,IO Bytes Input 為 18.06 GB,Latency 為 00:00:18.000。
執行結果的 Summary 頁簽顯示:資源消耗為 cpu
19.25 Core * Min,memory24.07 GB * Min;Job 已耗用時間為23.000秒,運行模式為fuxi job 2.0。其中 M1 任務執行個體數 1404,已耗用時間18.000秒,輸入記錄數 2879987999,輸出記錄數 355;R2_1 任務執行個體數 1,已耗用時間4.000秒,輸出記錄數 1。 -
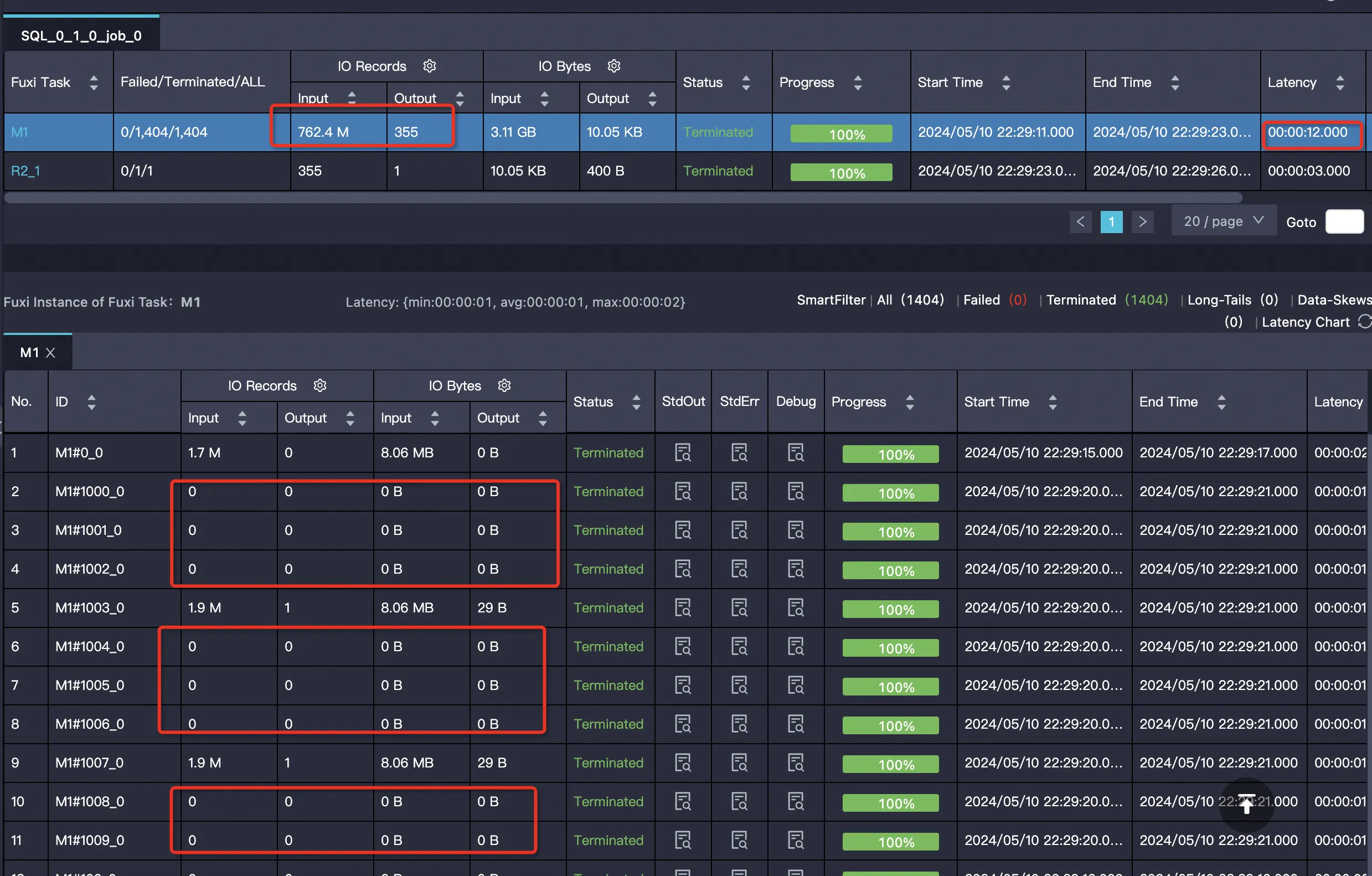
Parquet外表+開啟PPD
SET odps.ext.parquet.native = true; SET odps.sql.parquet.use.predicate.pushdown = true; SELECT SUM(ss_sold_date_sk) FROM tpcds_1t_store_sales WHERE ss_store_sk = 2 AND ss_sold_date_sk >= 2451871 AND ss_sold_date_sk <= 2451880;
執行該查詢後,作業 Summary 顯示資源消耗為
cpu 11.47 Core * Min, memory 14.33 GB * Min,總已耗用時間 15 秒。其中 M1 階段 instance count 為 1404,運行耗時 12 秒,輸入記錄數 762366649 條(約 3339386880 bytes);R2_1 階段 instance count 為 1,運行耗時 3 秒。存在很多空Mapper,無需讀資料:
實際裁減RowGroup的日誌:
[2024-05-10 22:29:22.692182] [INFO] [239551] [/home/admin/odps_build/workspace/IRDS_CMK_7u/jenkins-IRDS_CMK_7u-70 16/common/table/file_formats/parquet/parquet_row_group_pruner.cpp:100] The expression to prune row groups:(((ss_store_s k == 2:int64) and (ss_sold_date_sk >= 2451871:int64)) and (ss_sold_date_sk <= 2451880:int64)) [2024-05-10 22:29:22.705508] [INFO] [239551] [/home/admin/odps_build/workspace/IRDS_CMK_7u/jenkins-IRDS_CMK_7u-70 16/common/table/file_formats/parquet/parquet_reader_factory.cpp:136] Parquet row group pruning is enabled, millisecon ds elapsed:13 Total row group count:1 Pruned row group count:1 The first several row group indexes: [2024-05-10 22:29:22.705532] [INFO] [239551] [/home/admin/odps_build/workspace/IRDS_CMK_7u/jenkins-IRDS_CMK_7u-70 16/common/table/file_formats/parquet/parquet_reader_factory.cpp:60] total feasible parquet row group count:0] -
內表+開啟PPD
內表資料有排序屬性,因此裁減效果更明顯。
SELECT SUM(ss_sold_date_sk) FROM bigdata_public_dataset.tpcds_1t.store_sales WHERE ss_store_sk = 2 AND ss_sold_date_sk >= 2451871 AND ss_sold_date_sk <= 2451880;執行該查詢後,作業 DAG 顯示資料來源總行數為 2,879,987,999,實際掃描行數僅為 32,830,000。M1 階段(703 個執行個體)讀取 32,830,000 行後輸出 323 行,R2_1 階段接收 323 行最終輸出 1 行,表明內表開啟 PPD 且資料有排序屬性時裁剪效果顯著。
Fuxi Jobs 作業監控顯示作業
SQL_0_1_0_job_0已完成,包含 M1(703 個執行個體,Input 32.8M 條記錄 / 1.52 GB,Output 323 條,Latency 00:00:09.375)和 R2_1(1 個執行個體,Input 323 條,Output 1 條,Latency 00:00:03.873)兩個 Fuxi Task,狀態均為 Terminated。M1 執行個體明細中存在 4 個 Data-Skew 執行個體,其中M1#101_0、M1#103_0、M1#105_0等執行個體的 Input 和 Output 均為 0,屬於空跑執行個體,表明該查詢存在資料扭曲問題。resource cost: cpu 5.62 Core * Min, memory 7.02 GB * Min inputs: lakehouse47_2.default.tpcds_1t_store_sales2: 32830000 (1633880386 bytes) outputs: Job run time: 14.000 Job run mode: fuxi job 2.0 Job run engine: execution engine M1: instance count: 703 run time: 9.000 instance time: min: 0.000, max: 2.000, avg: 0.000 input records: TableScan1: 32830000 (min: 0, max: 210000, avg: 46699) output records: StreamLineWrite1: 323 (min: 0, max: 1, avg: 0) metrics_output_count: Calc1: 58025 (min: 0, max: 461, avg: 82) HashAgg1: 323 (min: 0, max: 1, avg: 0) StreamLineWrite1: 323 (min: 0, max: 1, avg: 0) TableScan1: 32830000 (min: 0, max: 210000, avg: 46699) metrics_inner_time_ms: Calc1: 4 (min: 0, max: 2, avg: 0) MaxInstance: 21 GlobalInit: 57752 (min: 60, max: 386, avg: 82) MaxInstance: 17 HashAgg1: 0 (min: 0, max: 0, avg: 0) MaxInstance: 2 StreamLineWrite1: 20469 (min: 5, max: 899, avg: 29) MaxInstance: 400 TableScan1: 131977 (min: 51, max: 1417, avg: 187) MaxInstance: 301 R2_1: instance count: 1 run time: 4.000 instance time: min: 0.000, max: 0.000, avg: 0.000 input records: StreamLineRead1: 323 (min: 323, max: 323, avg: 323) output records: AdhocSink1: 1 (min: 1, max: 1, avg: 1) metrics_output_count: AdhocSink1: 1 (min: 1, max: 1, avg: 1)
情境樣本
本樣本將建立以ZSTD壓縮的Parquet格式外表,並進行讀取和寫入操作。
-
前置準備
-
已準備好OSS儲存空間(Bucket)、OSS目錄。具體操作請參見建立儲存空間、管理目錄。
由於MaxCompute只在部分地區部署,跨地區的資料連通性可能存在問題,因此建議Bucket與MaxCompute專案所在地區保持一致。
-
授權
-
具備訪問OSS的許可權。阿里雲帳號(主帳號)、RAM使用者或RAMRole身份可以訪問OSS外部表格,授權資訊請參見OSS的STS模式授權。
-
已具備在MaxCompute專案中建立表(CreateTable)的許可權。表操作的許可權資訊請參見MaxCompute許可權。
-
-
準備ZSTD格式資料檔案。
在樣本資料的
oss-mc-testBucket中建立parquet_zstd_jni/dt=20230418目錄層級,並將存放在分區目錄dt=20230418下。 -
建立ZSTD壓縮格式的Parquet外部表格。
CREATE EXTERNAL TABLE IF NOT EXISTS mc_oss_parquet_data_type_zstd ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongtitue DOUBLE, recordTime STRING, direction STRING ) PARTITIONED BY (dt STRING ) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH serdeproperties( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole', 'mcfed.parquet.compression'='zstd' ) STORED AS parquet LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/parquet_zstd_jni/'; -
引入分區資料。當建立的OSS外部表格為分區表時,需要額外執行引入分區資料的操作,更多操作請參見OSS外部表格。
-- 引入分區資料。 MSCK REPAIR TABLE mc_oss_parquet_data_type_zstd ADD PARTITIONS; -
讀取Parquet外表資料。
SELECT * FROM mc_oss_parquet_data_type_zstd WHERE dt='20230418' LIMIT 10;部分返回結果如下:
+------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+ | vehicleid | recordid | patientid | calls | locationlatitute | locationlongtitue | recordtime | direction | dt | +------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+ | 1 | 12 | 76 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:10 | SW | 20230418 | | 1 | 1 | 51 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | S | 20230418 | | 1 | 2 | 13 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:01 | NE | 20230418 | | 1 | 3 | 48 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:02 | NE | 20230418 | | 1 | 4 | 30 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:03 | W | 20230418 | | 1 | 5 | 47 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:04 | S | 20230418 | | 1 | 6 | 9 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:05 | S | 20230418 | | 1 | 7 | 53 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:06 | N | 20230418 | | 1 | 8 | 63 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:07 | SW | 20230418 | | 1 | 9 | 4 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:08 | NE | 20230418 | | 1 | 10 | 31 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:09 | N | 20230418 | +------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+ -
寫入資料至Parquet外表。
INSERT INTO mc_oss_parquet_data_type_zstd PARTITION ( dt = '20230418') VALUES (1,16,76,1,46.81006,-92.08174,'9/14/2014 0:10','SW'); -- 查詢新寫入的資料 SELECT * FROM mc_oss_parquet_data_type_zstd WHERE dt = '20230418' AND recordid=16;返回結果如下:
+------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+ | vehicleid | recordid | patientid | calls | locationlatitute | locationlongtitue | recordtime | direction | dt | +------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+ | 1 | 16 | 76 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:10 | SW | 20230418 | +------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+
常見問題
Parquet檔案列類型與外表DDL類型不一致
-
報錯資訊
ODPS-0123131:User defined function exception - Traceback: java.lang.ClassCastException: org.apache.hadoop.io.LongWritable cannot be cast to org.apache.hadoop.io.IntWritable at org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableIntObjectInspector.getPrimitiveJavaObject(WritableIntObjectInspector.java:46) -
錯誤描述
Parquet檔案的LongWritable欄位類型與外表DDL的INT類型不一致。
-
解決方案
外部表格DDL中的INT類型需要改為BIGINT類型。
寫外部表格時報錯java.lang.OutOfMemoryError
-
報錯資訊
ODPS-0123131:User defined function exception - Traceback: java.lang.OutOfMemoryError: Java heap space at java.io.ByteArrayOutputStream.<init>(ByteArrayOutputStream.java:77) at org.apache.parquet.bytes.BytesInput$BAOS.<init>(BytesInput.java:175) at org.apache.parquet.bytes.BytesInput$BAOS.<init>(BytesInput.java:173) at org.apache.parquet.bytes.BytesInput.toByteArray(BytesInput.java:161) -
錯誤描述
大量資料寫入Parquet外表時出現OOM報錯。
-
解決方案
建議建立外部表格時,先調小
mcfed.parquet.block.row.count.limit參數,如果還會發生OOM,或者輸出檔案太大,可以調小mcfed.parquet.page.size.row.check.max參數,更加頻繁地檢查記憶體。詳情請參見專屬參數。在向Parquet外表寫入資料前,加上如下參數。
-- 設定UDF JVM Heap使用的最大記憶體。 SET odps.sql.udf.jvm.memory=12288; -- 控制Runtime側batch size。 SET odps.sql.executionengine.batch.rowcount =64; -- 設定每個Map Worker的記憶體大小。 SET odps.stage.mapper.mem=12288; -- 修改每個Map Worker的輸入資料量,即輸入檔案的分區大小,從而間接控制每個Map階段下Worker的數量。 SET odps.stage.mapper.split.size=64;